RabbitMQ Summit 2018 was a one day conference which brought light to RabbitMQ from a number of angles. Among others, our own Lovisa Johansson address the most common misconception, misconfigurations and anti-patterns in RabbitMQ usage.
Since 2012 CloudAMQP has been running dedicated and shared RabbitMQ clusters for customers around the world, in seven different clouds. In this talk Lovisa will address the most common misconception, misconfigurations and anti-patterns in RabbitMQ usage, and how they can be avoided. Lovisa will talk about how you can increase RabbitMQ reliability and performance and she will also mention common RabbitMQ use cases among CloudAMQP’s customers.
What we've learned from running thousands of production RabbitMQ clusters
I fell into the rabbit hole in 2014 when I started working at CloudAMQP - where we provide RabbitMQ as a service.
Managing the largest fleet of RabbitMQ clusters in the world
My goal when I started to work at CloudAMQP was that I wanted to make it more easy for everyone to get started with RabbitMQ. I wanted to bring simple use cases to the public and also point out all the benefits of using RabbitMQ . So I started to write technical documentations, update code examples, and write blog posts, then more blog posts and tutorials… I answered questions on stack overflow and I also created two eBooks.
So today, sometimes, when I'm at a bar and having a beer; or when I talked to unfamiliar people… I ironically call myself an influencer. And the life of a blogger and an influencer of this kind is almost as glamorous as you might think. You get spoiled with all kinds of luxury and you get to hang out with important people. I don't know if you can see it but it's a dog trying to disturb me because I work from home a lot.
I have, during my time at CloudAMQP – replied to more than 3.000 emails about RabbitMQ and I have been part of the urgent support team… where we respond to urgent support issues (which can be when a client needs the attention directly, when a server is running out of memory or when the RabbitMQ is under a heavy load).
Due to all this writing, many things were documented. I met up with different customers to see how they are using RabbitMQ. I wrote down lots of common use cases. We collected and anti-patterns we see in setups, configuration mistakes and all sorts of common mistakes that we see. Things that can go wrong and things that work out well.
So what kind of issues are we dealing with then? First of all, we have client side problems where users like you and me, or client libraries are using RabbitMQ in a bad way. Then we have situations where things are just not done in an optimal way.
Then of course we have the server side (a server running old versions, misconfigured servers or when the setup of the server is not configured for a selected use case).
What we’ve learned from running thousands of production RabbitMQ clusters
So today I will spread the knowledge and talk about what we have learned from running thousands of RabbitMQ notes. My name is Lovisa and I'm from Umeå, Sweden. I work at 84codes which is the provider of CloudAMQP. I work as marketing manager and support engineer… and lots of in between. I have a growing family of lovely colleagues. Many of them are with me here today and they are always happy to talk. So come by and talk to us in our booth downstairs. 84codes is also the provider of 3 other services:
- Cloudkarafka - Apache karafka as a service
- ElephantSQL - PostgresSQL as a service
- CloudMQTT - the message broker for IOT
We work remote from all over the world. We also have customers from all over the world but, our Headquarter is based in Stockholm.
Largest provider of managed RabbitMQ servers
We are today the largest provider of managed RabbitMQ servers with thousands of running instances in seven clouds in 75 regions.
And I will now give some recommendations where sum is equal to 16 and they will also give a summary of all these recommendations in the end of this presentation.
1. Don’t use too many connections or channels.
Try to keep a connection and channel count low. Each connection uses about hundred kilobytes of Ram and of course, even more if TLS is used. So… thousands of connections can be a heavy burden on the RabbitMQ server (especially if you're running on a small instance). Believe it or not, a connection and channel leaks are one of the most common errors that we see. But, luckily it's mostly on staging and dev servers.
2. Don’t open and close connections or channels repeatedly.
Make sure you don't open and close connections or channels repeatedly. If you do that, it will give you a higher latency as more TCP packages has to be sent and received…and the process of AMQP connection is as mentioned before, quite involved and requires at least 70 TCP packages and again, even more if TLS is used.
A RabbitMQ is optimized for a long lived connection, so keep connections if you are able to; keep them open and then reuse them if you are able to. Channels can be opened and closed more frequently, but even channels should try to be long lived - if possible. The best is to not open a channel every time you're publishing.
Each process should ideally only create one TCP connection and use multiple channels in that connection for difference threads. We deal with servers that are under heavy load due to opening and closing off connections almost every week.
Some clients can't keep long live connection to the server and this has - as I said before, an impact of latency. One way to avoid that connection churn is to use a proxy that pulls connections and channels for reuse. We have developed an AMQP proxy for this.
Our benchmarks show that the proxy is increasing publishing speed with a magnitude or more. https://github.com/cloudamqp/amqproxy
We are developing in many different languages. And the amqproxy is developed in Crystal, which we're also really proud sponsor of.
3. Separate connections for publishers and consumers
One should always separate connections for publish and consume. First of all, imagine what will happen if you are using the same connection for publisher and consumer - when the connection is in flow control.
A flow controlled connection is a connection that is being blocked and unblocked several times per second in order to keep the rate of messages at a speed that the rest of the server can handle. A publisher and the consumer on the same connection might worsen this flow control – since you might not be able to consume messages when the connection is being blocked.
Secondly, RabbitMQ can apply back pressure on the TCP connection when the publisher is sending too many messages to the server. If you consume on the same TCP connection, the server might not receive the message acknowledgement from the client. And so, the consumer performance is affected too. And at lower consumer speed the server might be overwhelmed after a while.
As I said, I'm Swedish and if you know something about Sweden except Swedish fika, than it might be that will love queuing. What we don't like is large queues or when people in some way try to squeeze in right in front of you. So, recommendation number 4 comes straight from my heart.
4. Don’t have too large queues.
Try keeping your queue as short as possible. A message published to an empty queue will go straight up to the consumer as soon as queue receives the message. And of course, a persistent message also will be written to disk.
It's recommended to have less than 10,000 messages in a queue and many messages in a queue can also put a heavy load on the RAM usage. In order to free up RAM, RabbitMQ starts flushing or pages out messages to disk. And this page out process usually takes time and blocks the queue from processing messages when there are many messages to page out.
Another thing that is bad with large queues is that it's time consuming to restart a cluster with many queues - since the index has to be rebuilt. It's also time consuming to sync messages between nodes in the cluster.
Large queues are also a very, very common error that our customers have. A queue is just piling up due to missing consumers or due to the clients publishing messages faster than the customers are able to handle the messages. Then eventually the server is overloaded and killed. When this happens, we usually add up more power to those machines… but, it still takes time to restart the cluster because of the rebuilding of the indexes etc.
It is sometimes recommended for applications that often get hits by spikes of messages and were throughput is more important than anything else: to set the max length on the queue because… this keeps the queue short by discarding messages from the head of the queue.
5. Enable lazy queues to get predictable performance.
A feature called “Lazy queues” was added in RabbitMQ 3.6 and “Lazy queues” writes messages immediately to the disk… thus spreading the work out over time, instead of taking a risk of a performance hit somewhere down the road.
Messages are only loaded into memory when they are needed and thereby the RAM usage is minimized; but the throughput time will be longer with “lazy queues”. So “Lazy queues” gives you a more predictable and smooth performance curve without any sudden drops; but at the cost of little overhead.
If you're sending many messages at once, like - if you're a processing batch jobs… or, if you think that your consumer will not keep up with the speed of the publisher all the time, then we recommend to enable “lazy queues”. We think that you can ignore “lazy queues” if you require a high performance or, if you know that your queue will always stay short due to a max links policy… or something like that.
6. Don’t set RabbitMQ Management statistics rate mode to detailed.
A RabbitMQ management interface collects and calculates metrics for every queue, connection and channel in the cluster. Also setting RabbitMQ management that takes the great mode to detailed - could have a serious performance impact, and should not be used in production if you have thousands upon thousands of active users or consumers.
7.1 Split queues over different cores and route messages to multiple queues.
Queues are single threaded in RabbitMQ. And one queue can handle up to 50,000 messages a second. You will therefore get better performance… have you split your queues over different course and nodes and if you're out messages between multiple queues.
The queues are bound to the node where they are first declared, so all messages relative to specific queue - will end up on the node where that queue resides. You can of course manually split queues evenly between nodes, but the downside is that you need to remember where that queue is located.
We are in command to plugins that can help you if you have multiple nodes or a single node cluster with multiple courses: it's the consistent hash exchange plugin and RabbitMQ sharding.
7.2 The consistent hash exchange plugin
The consistent hash exchange plugin has been mentioned a lot today. The plugin allows you to use an extension to load balance messages between the queues. So, messages sent to an exchange are consistently and equally distributed across many bounded queues…and it would quickly become hard to do this manually - without adding too much information about number of queues and their bindings into the publishers. Note that it's important to consume from all queues bounded to the exchange - when using this plugin.
The sharding plugin (a RabbitMQ sharding) does the petitioning of queues automatically for you. So, once you have defined an exchange is sharded, the supporting queues are automatically created on every cluster node…and messages are sharded across them. Sharding shows one queue to the consumer, but it could be manic use running behind it in the background.
8. Have limited use on priority queues.
Then we have priorities. Queues can have zero or more priorities…and behind the scenes of a priority queue - a new backing queue is created. So, each priority level uses an internal queue on the Erlang virtual machine which takes up some resources. Using 255 thousands of priorities means you will have resources usage similar to having close to that many queues.
In most use cases, it's sufficient to have no more than 5 priority levels. This is fixed in RabbitMQ 3.7.6. The max priority cap for queues is now enforced and set to 255. Applications that rely on a higher number of priorities will break and such applications must be updated to use no more than 255 priorities.
We had like, two weeks ago or maybe three weeks ago, a case where 2 consumers were starting up RabbitMQ… it took a really long time and memory usage just exploded. This was despite few queues and few messages - which is the common error when it takes long time to restart a broker. But, this time it was due to many priority levels.
9. Send persistent messages and durable queues.
Everyone needs to be prepared for broker restarts, for broker hardware failure or a server precious. And to ensure that messages and broker definition survive restarts, we need to be ensured that they are on disk.
Messages, exchanges and queues that are not durable and persistent are lost during a broker restart. So, make sure that queue is declared as durable and messages are sent with delivery mode persistent.
Remember: persistent messages are heavier, as they have to be written to disk. So, for high performance it's better to use transient messages and temporary or non-durable queues.
10.1 Adjust prefetch value
Then we' have the prefetch - which is used to specify how many messages are sent to the costumer and cached by the RabbitMQ client library: how many messages the clients can receive before acknowledging a message. It's used to get as much out of the consumer as possible.
RabbitMQ default prefetch settings give clients an unlimited buffer; meaning that RabbitMQ - by default, send as many messages as it can - to any consumer that looks ready to receive them or accept them. Messages that are sent are cached by the RabbitMQ client library in the consumer - until it has been processed.
So, not setting a prefetch can lead to clients running out of memory and makes it impossible to scale out with more consumers.
In RabbitMQ we got everything at 3.7 we got a new option to adjust the default prefetch value; this value is by default set to 1000 on all new clouding QP servers with version 3.7 (or higher). It doesn’t really exist yet, but soon.
10.2 Prefetch – too small prefetch value
A too small prefetch count may hurt performance since most of the time, it’s waiting for permissions to send more messages.
This figure is illustrating along idling time. As an example: We have a prefetch setting of 1 and this means that RabbitMQ won't send out the next message until the round trips completes (where a round trip is deliver, process and acknowledge).
We have in this image and total round trip time of 125 milliseconds – with a processing time of only 5 milliseconds. So, too low... Well, you will keep the consumer idling a lot since they need to wait for messages to arrive.
10.3 Prefetch – too large prefetch value
On the other hand, a large prefetch count could deliver lots of messages to one single consumer… and keep that consumer busy while other consumers are held in idling state.
10.4 Prefetch
So, if you have one single or few consumers and you are processing messages quickly, we recommend prefetching many messaging at once and trying to keep your client as busy as possible.
If you have about the same processing time - all the time and the network behavior remains the same, you can use the total round trip time divided by processing time - on the client, to get the estimated prefetch value for each message.
And if you have many consumers and short processing time, we recommend that you lower prefetch value time (than for the single or few consumers). And finally, if you have many consumers and / or long processing time, we recommend setting prefetch count to 1. So, the messages are evenly distributed among all your workers.
Another thing that you should remember is that if your client auto – ack messages, then the prefetch value has no effect.
11. HiPE
HIPE increases server throughput at the cost of increased start-up time…So, when you enable HIPE - RabbitMQ, is compiled at startup and this throughput increases with 20 to 80 percent -according to benchmark tests.
The drawback of HiPE is that startup time increases quite a lot: to 1 to 3 minutes, and it's therefore not recommended if you require high availability due to this long startup time.
We don't consider HIPE as experimental any longer. Six percent of our clusters has HIPE enabled and we haven't seen issues we've had for a really long time.
12. Acknowledgments and Confirms.
Acknowledgements: Let the server and client know if the message has to be retransmitted again… and the client can either act a message when it receives it or when the client has completely processed the message.
So, pay attention to where in your consumer logic you're acknowledging messages… Like, assuming application that receives essential messages - should not acknowledge messages until it has finished whatever it needs to do with them…so that unprocessed messages don't go missing in case of worker crashes, exceptions, etc.
And the acknowledgement has a performance impact – so, for the fastest possible throughput, manual acts should be disabled.
Publish confirm is the same thing, but for publishing and the server acks, when it has received a message from the publisher. Publish confirm also has a performance impact… but however… Once you keep in mind that it's required, the publisher needs messages to be processed at least once.
13. Use a stable RabbitMQ version.
Thanks to the RabbitMQ team great improvements are made all the time, which is really great. In 3.7, we got to the default prefetch as mentioned, and this will probably completely remove cases where the consumer has been killed - due to large message delivery… or due to an unlimited prefetch value.
Further, individual vhost message stores are now available… and this helped us at CloudAMQP a lot.
We have 2 subscription plans that are shared plans - which gives the customer a single vhost and a multi-tenant server. And this means that our share plans can be even more, more stable; and even if you have multiple vhosts on a dedicated plan - it will also be more stable.
RabbitMQ 3.6 had a new feature release “lazy queue” that gave many of our customers and more predictable and stable cluster. And we found the “lazy queue” features so good, that all our new clusters with version RabbitMQ 3.6 or larger – have “lazy queue “enabled by default.
Many of our customers with issues are running old versions or documented unstable versions. Version 3.6 had many memory problems up to version 3.6.14.
Also, 3.5.7 was good – but it lacks some good features, like the “lazy queue” feature.
We still have lots of servers running on 3.5.
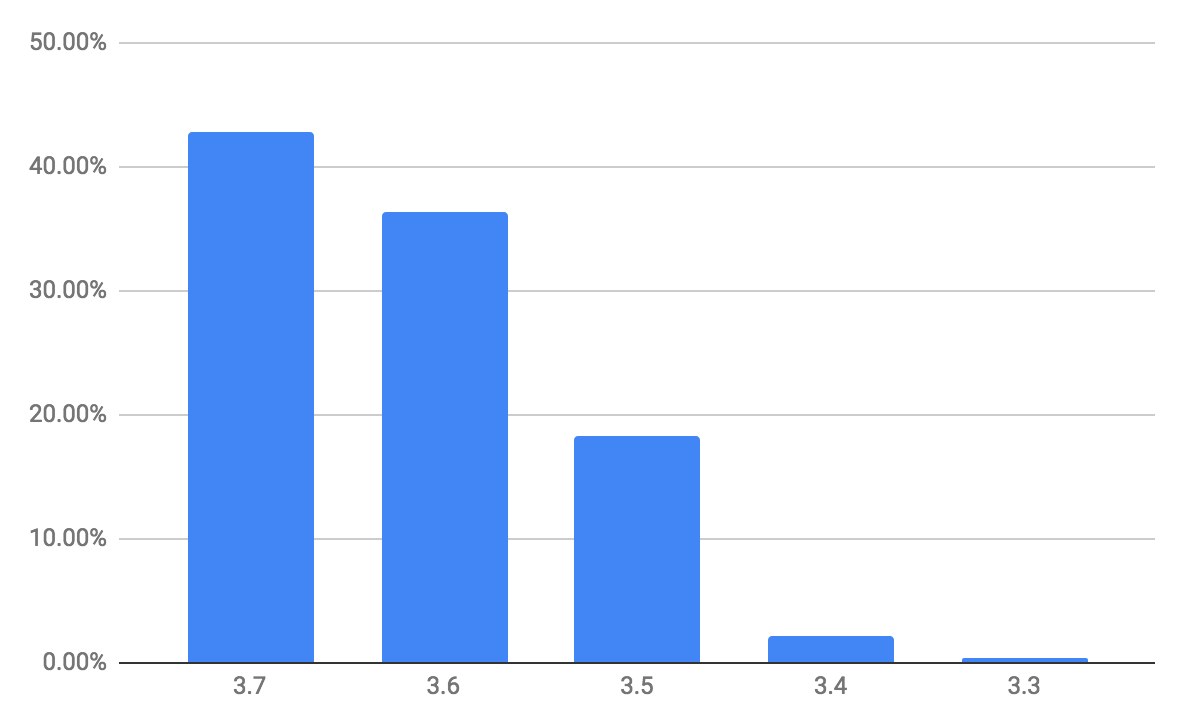
And this is the image of a RabbitMQ distribution version in CloudAMQP customers. And it's nice to see that - so many have upgraded to 3.7 because it's always something we try to push to make better… We want our customers to run new, stable versions.
And we always test new versions before that. We set them as available versions in CloudAMQP so, the menu that is selected in our drop-down menu on the page where you select which version you want to run - that is the version we recommend at the moment.
So, this recommendation is up to date with things that are happening in RabbitMQ and uses a stable version - and also a stable Erlang version and a stable client library version.
14. Disable plugins you are not using.
Some plugins might be a super nice to have, but on the other hand, they might consume a lot of resources. Therefore, they are not recommended in production servers. So, make sure to disable plugins that you are not using.
An example of a plugin that we are using a lot, but we are disabling every time we were finished using it; it is the top plugin which we are using when we were troubleshooting RabbitMQ servers for our customers.
15. Delete unused queues
Even unused queues take up some resources… you index management to statistics etc. Leaving temporary queues can eventually cost RabbitMQ to run out of memory. So, make sure that you don't leave unused queues left behind and set the temporary queues out to delete exclusive or out to expire.
16. Enable HA-vhost policy on custom vhosts.
Many of our customers are creating custom vhosts… and then they forget to add a HA-policy at the new vhost, which causes message loss during netsplits.
We also have an HA-policy on all our clusters (even single node clusters) because we are using that when customers are upgrading to new versions; or if they want to change from a two node cluster to a three node cluster - we use that. Also if they want to upgrade the RabbitMQ versions etc.
Summary Overall
Here's the summary of it all.
- Try to have short queues.
- Use long lived connections.
- Have limited use of priority queues.
- Use multiple queues and consumers.
- Split your queues over different cores.
- Use a stable Erlang and RabbitMQ version (and also client library version)
- Disable plugins you are not using.
- Have channels on all of your connections.
- Separate connections for publisher and consumer.
- Don't set management statistic rate mode too detailed in production.
- Delete unused queues
- Set temporary queues to auto delete
Summary for High performance
And for those who are more interested in recommendations for high performance
- Use short queues (use max length if possible).
- Do not use lazy queues.
- Send transient messages.
- Disable manual acks and publish confirms.
- Avoid multiple nodes (HA).
- Enable RabbitMQ HiPE.
And for those who are more interested in high availability…
- Enable lazy queues.
- Have two nodes and don’t forget to add HA-policy on all vhosts
- Use persistent messages to durable queues.
- Do not enable HiPE (due to long startup time)
RabbitMQ Diagnostics Tool
We have created a diagnostic tool that is available from the CloudAMQP control pane. Here customers can validate their RabbitMQ setup and get a score of this setup. And it's been used by many customers and it's nice to have. When we get a support request, we could check this one first and then always get back to customer and say you need to fix this, this, this and this - and then the servers are usually running much better after that.
The CloudAMQP Diagnostics Tool
Here are examples of things that are validated in this diagnostic tool. I think I've talked about many of them - but not all of them.
- RabbitMQ and Erlang version.
- Queue length.
- Unused queues.
- Persistent messages in durable queues.
- No mirrored auto delete queues.
- Limited use of priority queues.
- Long lived connections.
- Connection and channel leak.
- Channels on all connections.
- Insecure connections.
- Client library.
- AMQP Heartbeats.
- Channel prefetch.
- Limited use of priority queues.
- Management statistics rate mode.
- Ensure that you are not using topic exchange as fanout.
- Ensure that all published messages are routed.
- Ensure that you have a HA-policy on all vhosts.
- Auto delete on temporary queues.
- Persistent messages in durable queues.
- No transient messages in mirrored queues.
- No mirrored auto delete queues.
- Separate connections for publishers and consumers.
Finishing words
As we've seen today: best practice recommendations are different for different use cases… and some applications require high throughput, while other applications are publishing batch jobs that can be delayed for a while… and other applications just need to have lots of connections… and tradeoffs have to be done between performance and guaranteed message delivery, etc.
And our customers are today able to select number of nodes when they are creating a cluster, a single node for high performance and two or three nodes mainly for high availability and / or consistency.
We also have lots of other features built in, into the clouding CloudAMQP control panel: like, option to configure alarms for queue links or for missing consumers, etc. And users can view how many messages there has been in the queue over time - which helps us a lot when we are troubleshooting our servers, since the statistics for the queues are available all the time.
And we also had a show metrics for usage like CPU, RAM and the disk.
We have seen many different use cases and our future plan as CloudAMQP is to make it even easier for customers to quickly set up a cluster - as specified for a selected use case, based on best practice recommendations.
It would be nice if we could have a list like this in the community, like a list of recommendations - because it's makes it so much easier for beginners to start using RabbitMQ.
So, if you have any recommendations or things that we need to add… or, if you have different opinions about something, just let me know or send me an email or reach out to me.
Questions from the audience
Which public cloud providers are you using at CloudAMQP?
The customer can select the data center when they create their cluster. They can choose between most common public cloud provider.
Are you doing everything with bash scripts?
Yes.
I wonder if you have a strategy to help customers to keep up to date? If you handle part of the upgrades, if you provide tools or anything else.
In our control panel we have a simple button where you can press upgrade. And we regularly send out information about new versions including information about their benefits.
In every case possible we do upgrades without downtime. So, if it’s a patch upgrade we do it node by node. And in the other case: if it requires downtime, then we will notify you before the upgrade is taking place.
Would you say that RabbitMQ 3.7 is more stable than 3.6?
I would say yes. The early versions of 3.6 we had a lot of problems with, but the current 3.6 version and 3.7 version has been working really well. And the lazy queues was a really good feature for us.
What’s the downside of using HiPE with HA?
When a node needs to come back online, due to e.g. netsplit, it can take quite some time for the node to boot with HiPE enabled. If there are a lot of messages in the queue it already takes a lot of time and if you add HiPE on top of that it takes much longer time.
