All jobs that are added to the queue are consumed by Heroku workers running with MsgFlo. This article focus on how to use work queues in RabbitMQ.
Background
The Grid wants to make the art of building attractive, functional websites as easy as keeping up a social network profile; you get an AI website that design itself with help of small inputs from you. The Grid produces websites from user-provided content. You are able to set up a webpage within a few minutes by selecting color schemes and uploading your own content. The Grid currently serves thousands of sites. It’s understandable that they are doing a lot of computationally heavy work server-side.
I had the opportunity to chat with Jon Nordby and Henri Bergius from flowhub.io about building The Grid.
When we were building The Grid, we went with an architecture heavily reliant on microservices communicating using message queues. RabbitMQ was a natural choice for CPU intensive work.
Microservices communicating via RabbitMQ
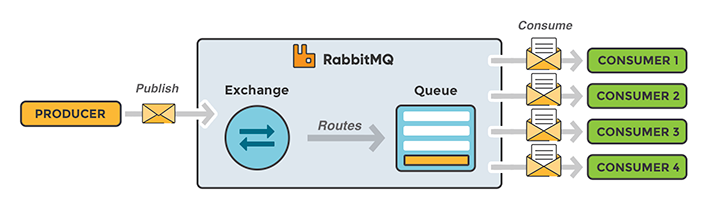
Communication between microservices in The Grid is done via RabbitMQ, which results in one microservice consuming data from a queue and publishing the outcome to another queue. As a result, a chain of microservices processes the requests.
All computationally intensive work is created as jobs in an AMQP/RabbitMQ message queue, which are consumed by Heroku workers. It includes jobs like:
- Image analytics (for understanding the content)
- Constraint solving (for page layout)
- Image processing (optimization and filtering to achieve a particular look).
RabbitMQ work queues are used to distribute time-consuming tasks among multiple workers. The main idea behind Work Queues (also called task queues) is to avoid doing a resource-intensive task immediately and having to wait for it to complete. A task can be scheduled to be done later. The task is encapsulated as a message and sent to the queue. A worker process running in the background pop the task and execute the job. By running many workers, the tasks will be shared between them.
Rate limiting
Some of the microservices also deal with external APIs, allowing them to handle service failures and API rate limiting in a robust manner. If the rate limit was reached for a 3rd party service, messages were simply added to a queue, delayed and handled once the restrictions were removed.
RabbitMQ Acknowledgement
If one of your microservices crashes, you probably would like your tasks to be delivered to another worker or held in the queue until the worker is ready to receive the request again. In order to make sure a message is never lost, RabbitMQ support message acknowledgements. An acknowledgement can be sent back from the worker to tell the message queue that a particular message has been received and processed and that the message queue is free to delete it.
If a worker dies without sending an acknowledgement, the message queue will understand that a message wasn't processed fully and will redeliver it to the queue. That way you can be sure that no message is lost.
RabbitMQ Dead lettering
RabbitMQ can also be configured to route any failed operations into a dead-letter queue for further inspection. This gives you a full record of any failing operations. The queue can grow, and preserve the messages while the code to handle them is being fixed.
Heroku - Platform as a service (PaaS)
The Grid runs on Heroku; For those who are not familiar with Heroku, it’s a platform as a service (PaaS) that enables developers to build, run, and operate applications entirely in the cloud. That means you do not have to worry about infrastructure; you can simply focus on your application.
CloudAMQP was a simple choice - it was available with a click of a button as add-on in Heroku.
Using Heroku is an easy way to get started with message queueing and RabbitMQ. Step-by-step guides for deploying your first app can be found here. It’s easy to deploy and even easier to scale if needed.
Thanks for your time, Jon and Henri!

Jeff Hara
Customer Success Manager
Hi, I'm Jeff, and I'm here to help
Curious about what CloudAMQP can do in your architecture?
Reach out to us and let us help. The consultation is free, and we'll ensure you get in touch with one of our experienced architects. / Jeff
Contact us today