RabbitMQ Summit 2018 was a one day conference which brought light to RabbitMQ from a number of angles. Among others, Ayanda Dube talked about the internal design of RabbitMQ.
As the use of RabbitMQ grows, there's a growing need for its operators and engineers to have a good understanding and appreciation of its internal design, and how its sub-components interact to meet the various messaging requirements in industry. In this talk I walk through the internal design of RabbitMQ, explaining some of the key components which attribute to its robustness and reputation of being a world leading and well trusted messaging system.
A walk-through of the design and architecture of RabbitMQ
I'm going to talk about a challenging topic. Saskia approached me and said, "Hey, Ayanda, we're having a RabbitMQ Summit with CloudAMQP. Can you do a talk?" This was just after I had done a meetup where I spoke and I thought I could re-use that talk for this event.
And then, after working with a whole various number of customers, I noticed that there's a need for people to understand the internals of RabbitMQ. I was like, "Why not have a talk which is going a bit deeper on the internals of RabbitMQ?" So today I'm going to try and explain the internal design. Well, attempt to explain it. Because it's not easy.
With engineering, there's a common problem. There's an ever-present need for efficient communication, be it hardware, RF communication, or software, you always have two entities that just want to communicate efficiently. I think RabbitMQ meets this need for applications very effectively.
You've just got two applications. Simple case, two applications that want to communicate and we plug in RabbitMQ in there.
Quote
Just a quote, before I start. There was a gentleman called Frederick Barnard. I'm sure you've heard this quote.
"A picture is worth a thousand words."
I was trying to justify my slides. Then, I came up with a quote as well that's nice.
"A software system diagram is worth a thousand lines of code."
That's by me (last night). You will see why.
Initialization: Start scripts
We start with, you download RabbitMQ. You install it on your server. The directory structure is generally this.
You have your scripts directory. In your scripts directory, you've got the RabbitMQ server script which is basically what starts everything up. You can check this out and just follow along as well.
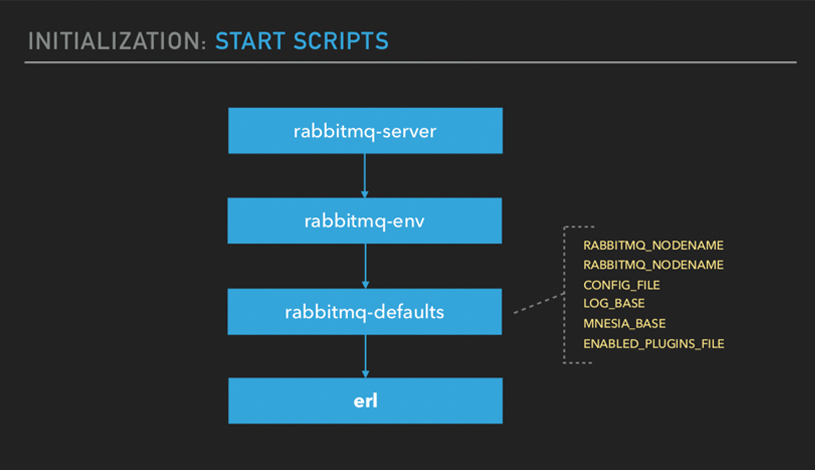
What does the Rabbit script do? Basically, it'll execute the RabbitMQ script which will basically initialize your environment variables. It will set some default environment variables. You can override these on your OS, which I'm sure most of you guys have done. After that, it will execute the erl command which will basically kickoff the Erlang node. That's the startup.
Initialization: Erlang Node
If you look at the scrip. You will find the
erl
command somewhere down the
Rabbit server script. Part of that command, you've got all the arguments
that would pass through that for node startup. One of the arguments is the
RABBITMQ_START_RABBIT
environment variable. If you navigate to where that
is, you'll notice that that that argument sets a boot module. The
-s
argument will execute that module and that function. Basically, the
function that will be executed will be
Rabbit:boot()
like based on the argument. Basically, that's what starts Rabbit.
Initialization: Boot
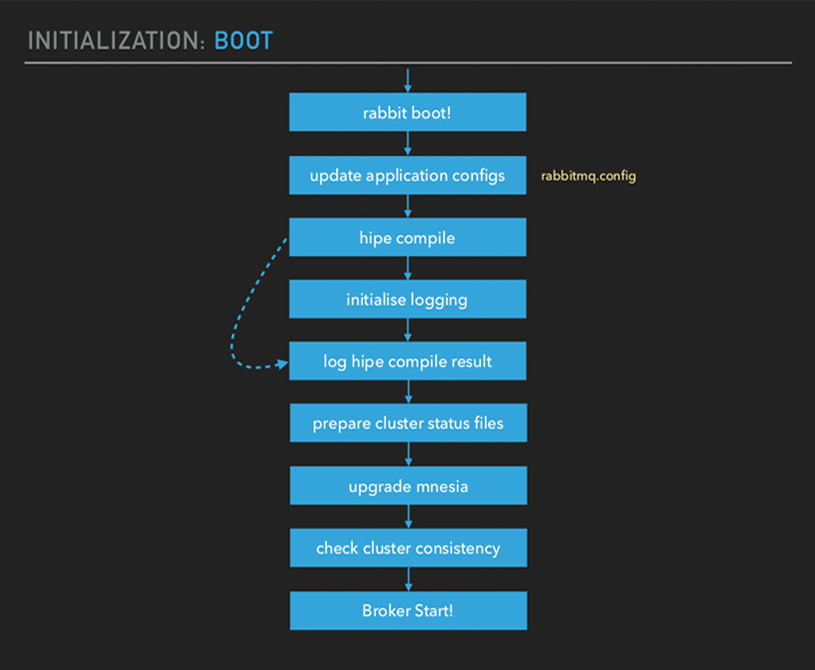
And then what happens in boot? The first thing which happens in boot is you
get your application configs updated. This is where your
rabbitmq.config
file where you define all your application configs. I think in 3.7, now,
they get merged with the new config format and you just get one config file
which is applied as application config. And then, you put a whole bunch of
other procedures that are carried out. You've got hipe compile options and
checking cluster consistency.
In later versions of RabbitMQ they're planning to have different versions being able to run together, so you can have 3.6 node running with a newer node, for example.
At the moment, if that cluster consistency check fails, you won't be able to start your node. And then, Broker Start, obviously. That is the next step.
Initialization: Broker start
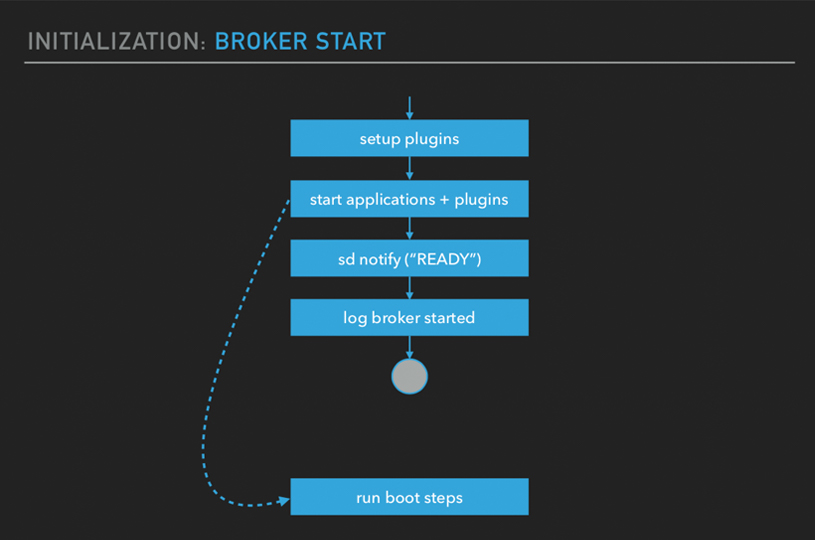
What happens when you start the broker? It will set up your plugins. There's a whole bunch of procedures that are done within that set of plugins procedure. It will start all the applications, the dependencies. You've got systemd notifications. If you started it as a service. And then, you get the log message on your logs.
Initialization: Boot steps
And then, within that applications phase, there's an important step which Rabbit does as part of initialization which is executing the boot steps. RabbitMQ has got a concept of boot steps.
I think, for Erlang developers, if you've worked with start phases and OTP, it's a very similar concept but this I find it a bit more flexible because you're not tied up to a single application file, as you have with OTP start phases.
Boot steps are basically going to initialize, run through a number of initialization phases. Basically, some of the boot steps. There's quite a lot. If you look at the RabbitMQ module, you've got a lot of boot steps that are executed. RabbitMQ will just run through all these. Do some initialization.
Maybe just a couple, just to point out, is you've got your alarming
infrastructure then that will be initialized. All your memory alarms will
be part of that. You've got your
file_handle_cache
for efficient usage of
your disk I/O. There's quite a lot. You can go into the Rabbit module and
see all these.
And then, at the end, what you have is you've got more internal boot steps which are not part of the initial boot steps. These are like distributed across other modules in the codebase. And then, after that, you've got your plugin bootsteps. If you do incorporate a boot step in your plugin, that's when it will get executed.
Initialization: Internal boot steps
Part of the internal bootsteps that are executed, you've got your authentication mechanisms. You've got your queue mirror modes, HA nodes. You've got your policy validators that are initialized. You've got a priority queue. This is interesting because priority queues are enabled by default in RabbitMQ. That is always enabled. We'll get to that at the end. If you look at the backing queue module that is used by the queue process. You'll notice that it defaults to the priority queue/backing queue callback. And then, you've got runtime parameters and other things that are initialized.
Initialization: Node state
So, you know that it's initialized. The boot steps have run. You've got you alarm processes running, memory monitor, node monitor. You've got your port and listeners running, and a whole bunch of other processes that are initialized. And then you've got some recovery schemes which are executed as part of startup.
I think in the newer versions, part of those recovery schemes is to recover the vhost. We noticed an interesting issue quite recently that there are some cases where that recovery phase was just taking way too long, up to eight hours. Thankfully, that was fixed.
Basically, this is when your node is initialized. Obviously, there's more stuff. I could've added like a whole stack of OTP stuff which is started under the hood but we’ll just focus on RabbitMQ.
Part of initialization as well, you've got your Mnesia tables that are started up. You've got your Rabbit user tables. All the users are stored in there. You've got your durable queues. Queues which is basically transient and durable queue tables, your vhost, and a whole lot more. The exchanges table as well.
That's initialization. That's when you know RabbitMQ is started. You haven't done anything. It's just all plain, nothing running at the moment, in terms of the operations that you're executing against it.
AMQP: Connection establishment
Just to try to explain how stuff works internally we will now look at the AMQP operations.
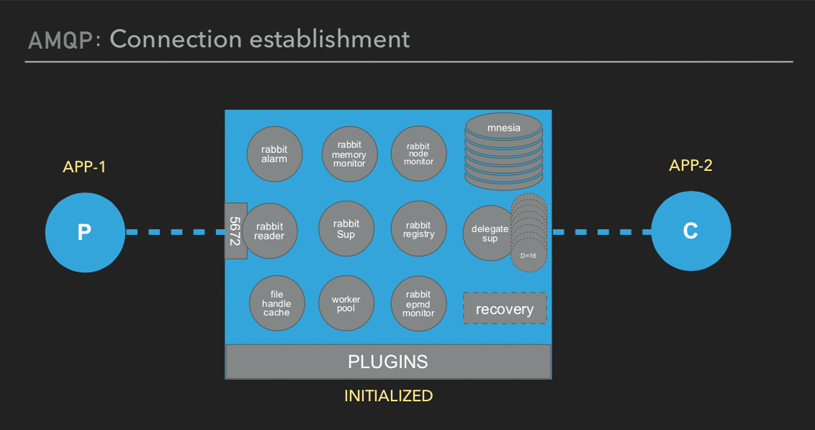
Our two applications which we mentioned - APP 1 and APP 2, they basically need to connect to the nodes and then start interacting. Your node is initialized. We'll take the first step, connection establishment.
AMQP Handling: Connection Establishment
This is your application, everything you see in the diagram below: that’s the Broker.
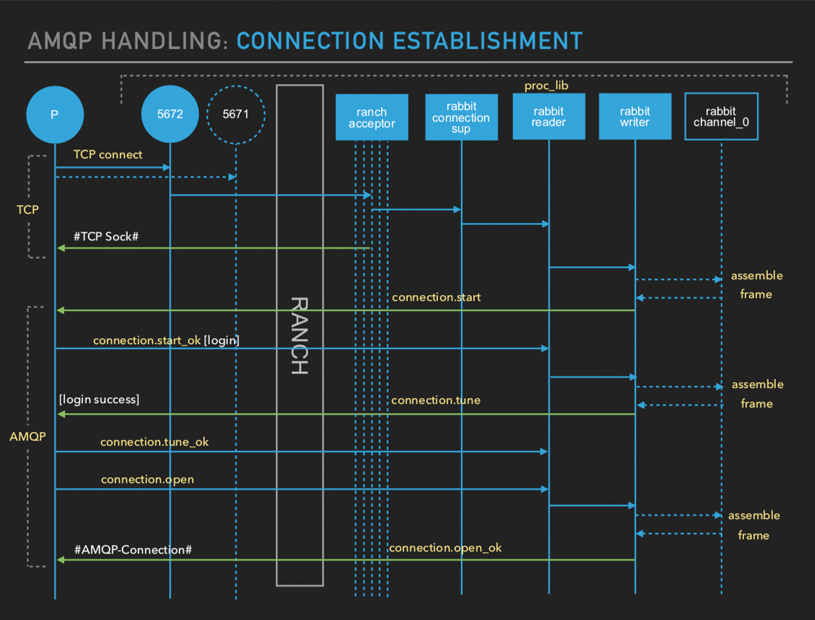
When your application connects (AMQP connection establishment) there's two
phases that take place which are abstracted to the developer. All your
client libraries will first open. And then, they will engage in AMQP
handshaking. Internally, in the server, you've got
RANCH
which is handling all your TCP details. And then, you've got a lot of acceptors which, for
each connection request that comes in, it'll handle that request.
The reader is actually the process that's going to handle your messages
coming in from your socket. The moment that is started, it'll will issue a
connection.start.
It will issue a connection start primitive back to the client. The client
will send back connection.start_ok. Part of that connection.start_ok
contains your credentials - username and password of the application. Then
there's connection tuning. And after that, the broker is going to send a
connection.open_ok.
That's your AMQP
connection.open.
AMQP Handling: Connection Establishment
If we then look at what actually happens after the connection is open, in terms of the procedures, you have your RabbitMQ reader started. And then, you have to wait for messages coming in. Obviously, the first message will be the protocol initialization pack which will contain the version, some bytes basically which depicts the version, which the client and the server need to agree on.
Internally, what happens? Rabbit will check those four fields. And then, it will match those fields and pick the AMQP version module which it's going to use.
Once we've set up, and the AMQP version has been agreed on, the connection pid is registered. Server properties are set up. If you do a trace, you'll see a lot of properties that are negotiated between the client and server.
AMQP Handling: Connection Establishment
Just a brief on the Erlang setup. On the boot phases, you're going to have
the TCP listener processes and supervisors being added to the RabbitMQ
supervisor. All of this is being taken care of by
RANCH.
If you know how
RANCH
works. Basically, what it does is it's got a whole
bunch of acceptors which Rabbit sets as 10 by default. This is
configurable. You can pump this up or reduce it based on your need.
Then it will start up the reader setup. Your acceptors get back to the accept phase. And then each client connection that comes in: it will set up a reader, which is the handler, for that client connection. You can have as many readers of the RabbitMQ “reader supervision trees” started as client connections come in. That's just a brief on the connection establishment.
AMQP Handling: Channel Creation (Node state)
Next, once you have a connection, you want to open or you created channel. Channels in RabbitMQ are internal processes which are going to handle the AMQP requests.
AMQP Handling: Channel open
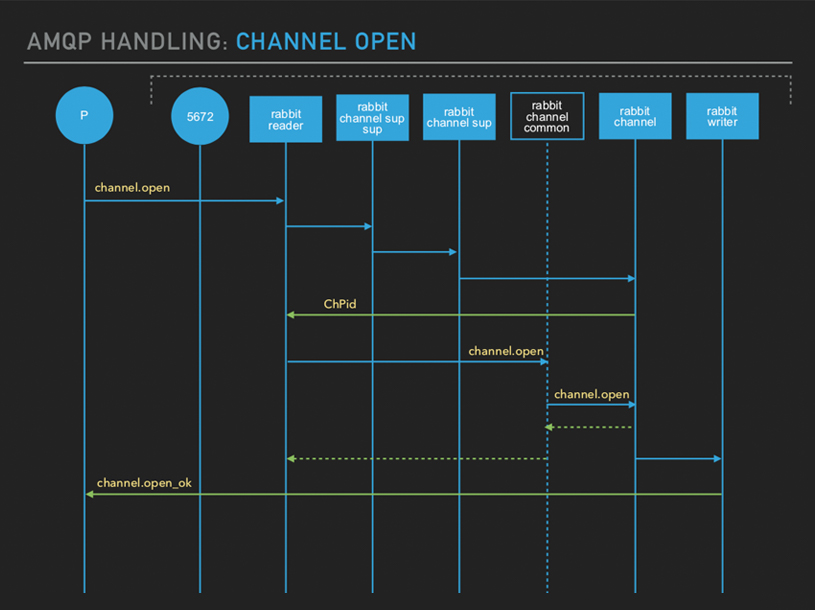
What happens when you send or connect a
channel.open
? The
channel.open
request will be handled by your Rabbit reader, like everything else, I
mean. And then, the channel top-level supervisor will be started. That will
start another supervisor for the specific channel. Then the channel process
will be started. The moment you get that channel process started they will
send back a channel.open message to the already started channel. That's
just for updating the state of the channel, just setting it to running
state.
After that, the
channel.open_ok
is sent to the rabbit writer process. You can go to the code base and actually see all these implementations.
AMQP Handling: Channel open
Let’s explain the procedures which are taken care of during channel
establishment. Your
channel.open
request will propagate through your rabbit
reader and that frame will get handled.
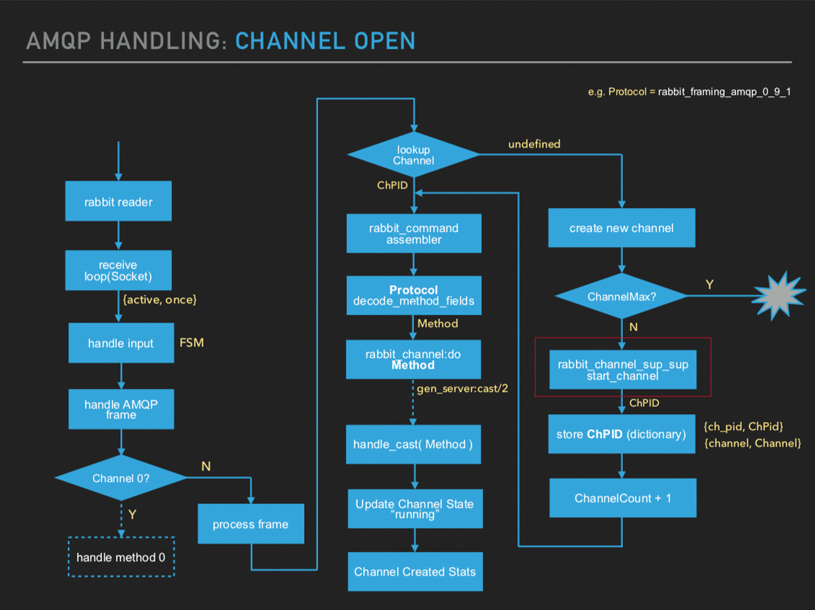
Here there is a check. You're not permitted to use channel 0. Channel 0 is only for setting up the rabbit reader process. If it's not channel 0, then it will process the frame.
All channels (their PIDs) are stored in the rabbit reader process
dictionary. And if you do a channel lookup, which is just a RAM store, it
will check if it’s already existing. If it is, then RabbitMQ basically will
decode that
channel.open
primitive.
Initializing the state. This can be sent across different nodes. It will forward that message and that will set the channel to a running state. And that's when your channel is started. If it didn't exist, it'll create a new channel.
At the same time there's a check whether the maximum number of permitted
channels are exceeded or not. If they are, obviously, your
channel.open
operation will fail. If they're not, it will start up the channel and then
come back to all these procedures.
AMQP Handling: Channel open
A channel consists of the supervisor process. If it's a direct channel, you will have a rabbit channel process and the rabbit limiter. If it's a network channel, which probably most of you are using - you can open direct channels/connections.
This is the handler for all your commands. The limiter handles all your prefetch counts mechanisms. The role of the limiter is to limit the interactions between the queue process and the channel in sending out traffic.
Finally we have the RabbitMQ writer process which issues out commands back to your client. And that's channel creation for you.
AMQP Handling: Create/declare an Exchange
Next, you want to create and declare an exchange. What happens when we do
that? A similar procedure. Your
exchange.declare
primitive is sent to the
rabbit reader, it’s forwarded to the channel. And then, there's a rabbit
exchange module. Here RabbitMQ will make a lookup in Mnesia, in the
database, and check if that exchange has already been created. If it's
there, you get an okey exchange and
exchange.declare_ok
operation will be returned back to the client.
Moving on. The exchange type will be declared. And then, the exchange is
inserted into Mnesia, into your database, and
exchange.declare_ok
will be returned back to the client. Pretty straightforward.
AMQP Handling: Exchange Declaration
Some checks are done when creating exchanges, to check if the type is valid. If it's within the direct topic headers scope - or, if you write your own plugin which like the consistent hash exchange. That will be registered on startup and the check will be carried out against that.
If it doesn't exist, your
exchange.declare
operation will fail. Then we check the permissions. “Does the exchange have configuration permission for
the user?” If it doesn't, it will fail.
Basically, it will check for the permissions for the user to create an exchange. If the user does have permissions to lookup the exchange. If it's there, it will return it. If it's not there, it will create it and insert in Mnesia, then return to the client.
AMQP Handling: Queue Declaration
Now, you've got your exchanges. You've got your channel. You’ve got exchanges. Now, you want to declare a queue.
Queue declaration, how is that handled? When you create a queue, obviously, you'll send your queue.declare primitive. Then there's an API for thee Rabbit AMQ queue module. That will do a lookup against the database.
If the queue is already existing in the database, it will return
queue.declare_ok.
That's when you've got the nowait flag set to true. But
if you had set it to true, it will first confirm that the queue is actually
created. It will just get some initial statistics from the queue process
that has been started. It will send out a stat message which goes through a
bunch of processes called delegates in RabbitMQ.
Rabbit has got a pool of processes called delegates. They split commands whether they are for a local queue or a remote queue. And then, if it's for a remote queue, it will actually ship across the command and execute it on the remote node which is more efficient than directly doing remote calls from this API.
This just return a couple of stats and return your declare_ok. This is confirmed that the queue is actually started. Whenever you set that nowait flag to false, this is what will happen.
If the queue wasn't found in the database, on the initial lookup, it will be declared. Your queue name. Is it durable? Auto delete? Your arguments that you set from your client application, they'll be propagated to the queue supervisor which will start the queue process. And then, the queue process will initialize the backing queue which has been configured for that queue process.
The backing queue actually determines how your queue behaves. You've got a
process and behind the scenes, there is a backing queue which varies on the
types of queues that you have. For example, if you've got the priority
queue. The backing queue will be the priority queue (default) which also
interacts with the variable queue. Those are just call backs, at the back.
Then, that will send back your
queue.declare_ok
back to your client application.
AMQP Handling: Queue Declaration
If there are any policies that you had set during queue declaration, like High Availability policies, those will be set on the queue. And if you've got any queue leader location strategies set up, those will be set here.
Basically, you compute the node on which the queue is going to reside. If it's a mirrored queue, you check the leader queue node. Usually, these are the same. That’ll then start up the queue supervisor.
This goes through another process called the prequeue process. It will check: “Is the queue a leader queue or a follower queue?” If it's a leader queue, it will start the leader queue and then initialize it with the backing queue, initialize your queue index and the message store.
For RabbitMQ 3.7 the message stores are per view host.You'd have a transient and a persistent message store. After that, your queue process will start. I will send init new. And, thus, the recovery strategy. That's mentioned to the queue which will proceed on more initialization steps. So there's quite a lot that takes place here. And if it’s a follower, the follower queue will be started from the mirror queue - follower process.
AMQP Handling: Bind Queue to Exchange
We’ve got the queues now. Then you want to create a binding between your exchange and your queues.
Bindings will basically exist in the database, as you're going to see. It's not like you've got a direct link between your exchanges and your queue.
AMQP Handling: Queue Exchange Binding
You issue your queue.bind command from your client mentioning your queue
and your exchange - the source and destination. That will go to your
channel along to the Rabbit binding module. It will check: “Does that
binding exist in the rabbit root table?” That's the table which holds all
your bindings. If there's an element, it will return
queue.bind_ok.
If there is nothing, it will write it to your database. There's actually three
tables there: the
rabbit_route
,
rabbit_durable_route
, and
rabbit_semi_durable_route.
And then, it will return
queue.bind_ok
to the client.
AMQP Handling: Queue to Exchange Binding
Initially, a couple of checks for the binding. There is formatting of the source and the destination which is your queue name and the exchange name. For example, stripping of carriage return characters in your queue names or exchange names. And then, it will write permissions for the destination.
Then, the Rabbit binding module will validate the binding, check in the database and return it. If it wasn't there it will create an entry in the database. And then issue it out via the Rabbit writer. That's why the channel always has a Rabbit writer.
Once you've got your bindings, the next thing is to subscribe the consumer to our queues.
AMQP Handling: Consuming
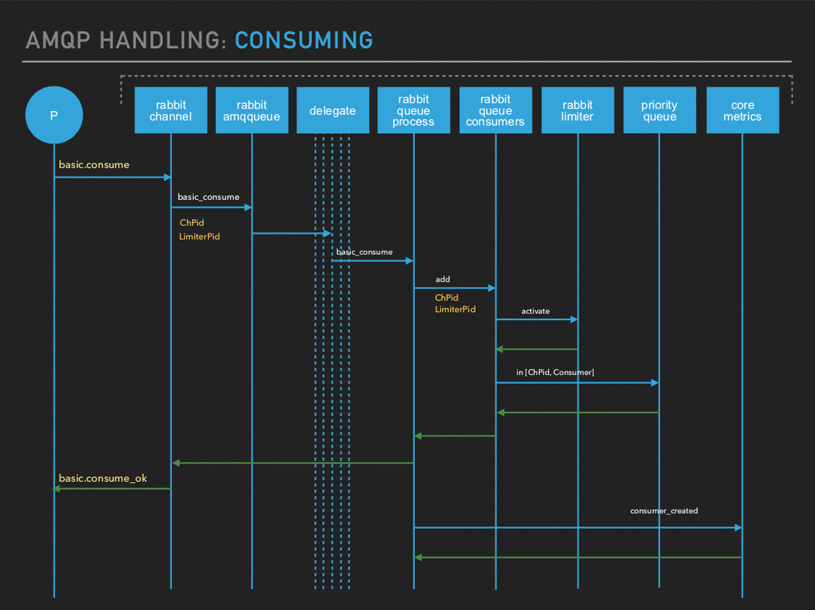
Here you issue out your basic.consume command. Your Rabbit channel will forward the basic.consume command to your queue process via the API. It will also mention the Channel PID delimiter. I did mention there are three processes for handling your prefetch counts and all that. The moment it gets to your queue, the queue will basically interact with this Rabbit queue consumer’s API. It's not like consumers are stand-alone processes within the server. Everything is happening within that queue process.
The request will initialize with the Rabbit limiter and give it the PID to activate. Once activated, the Channel PID and the consumer entry will be added into a queue (formatted into a record). You've got a small priority queue for each consumer that is created for a queue. It’s added into an internal queue in the queue process. So, you have a queue of consumers which are added.
The reason why it's a priority queue is because you can incorporate things like consumer priorities. If you want to prioritize your consumers, it'll be set within this priority queue in the queue process.
Then, the
basic.consume_ok
will be returned back to your client application
and also there are some
consumer_created
stats which are created.
AMQP Handling: Message Publish
We've got our consumers now. Everything is set up. We have our channel, exchanges and queues. The consumers with their own channels. And now we're ready to publish messages from our client application to the consumer.
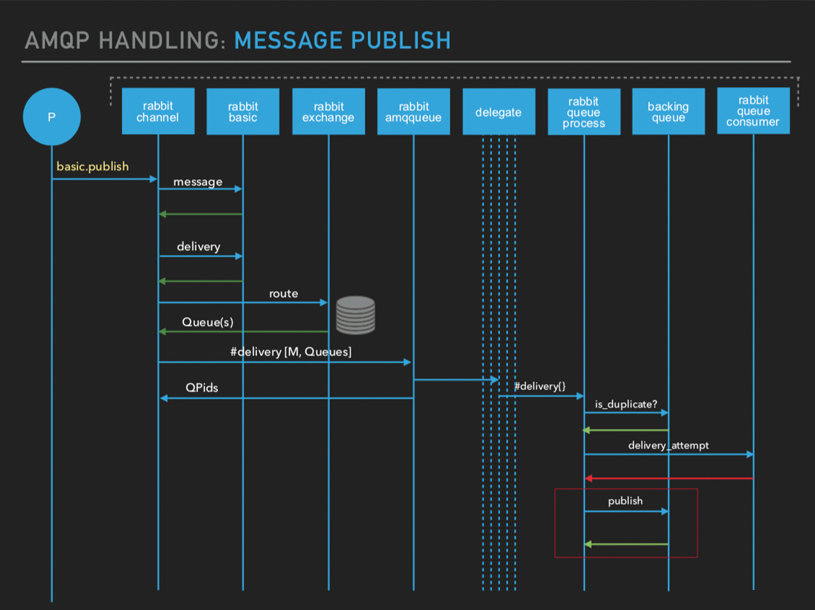
What happens when you do basic publish? If you push your message, it will be formatted by the Rabbit basic API into a delivery payload which is just a record. Then there's a route lookup basically looking at “Which queues am I going to deliver messages to?”. And for each message, you get a list of queues.
If your exchange is a direct exchange, you get a single queue there. If your exchange is a fanout, you get a list of queues. Or, if you have multiple direct bindings which have got the same routing keys, you get multiple queues. Everything is based on the type of exchange you choose.
The list of queues are then forwarded to your delegates, because these can be cross-node calls. Some queue can be local. Some queue can be remote. So that delivery record is forwarded to the queue process. This is not implemented in the backing queue but there’s a check to see if the message is a duplicate. At the moment, it just returns false by default.
And then, the first thing which Rabbit will do is the queue process will immediately attempt to deliver the message to the consumer. It makes sense because if you send a message, the first thing that you want to do is quickly check if a consumer can receive it. But if it can't, that's when we queue it up. That's the whole queueing theory.
There's an attempt to deliver the message and that fails. So the queue process will publish the message to the backing queue, to insert it into the actual queue message store (queue index). That's what takes place there.
Backing Queue
A bit on the on the backing queue: when it receives that publish command. Rabbit backing queues are very interesting. Basically, when you get a publish command, there’s a check: if it can be stored in the Rabbit queue index.
If the message payload is less than the queue index embed size, it will be stored in the Rabbit queue index. But if it's not, it will be stored in the message store. In the message store, you’ve got either transient and the persistent mode. Depending on your delivery mode flag. When you publish for persistence, it will be stored in in the persistence message store. Else, it will be stored in your transient, that will be returned.
Then the backing queue uses a message status record which all the actions are acted upon, based on what's been updated on this message status record. And after storing the message, the message status record is also stored in the internal backing queue queues.
You've got a whole bunch of queues internally which the backing queue uses. You’ve got Q1, Q2, Q3 and Q4. And you've got message classifications called ALPHAs, BETAs, GAMMAs. This is based on where the message is going to reside.
For example, a beta classification in your message exists on the disk and its position is held in RAM. When your node goes through memory pressure all messages that are in RAM are pushed to your DELTA's, to disk. Basically, during paging, that's what will be happening. It is just shuffling of messages from certain queues to another queue. That's it. Your messages are now going through.
AMQP: Node State
That's why we’ve got messaging now. APP 1 and APP 2 are now communicating, That's just an overview of what takes place internally when you’re interacting messages from one app to another.
Operations: Clustring
In case you to setup a RabbitMQ cluster you are just telling RabbitMQ that you have another node. And what it will just update the Mnesia config with that node. The Mnesia will handle everything else under the hood - such as authenticating to the other nodes, using Erlang distribution and synchronizing. All your tables will be synced across your cluster and all your internal routing will be handled across the cluster.
Operations: High Availability (HA) Queues
A quick note on High Availability queues. The moment you set a policy to make a queue HA, the backing queue changes to the mirror queue leader module. The queue state will be updated dynamically. And then, all your synchronization operations will be handled by Erlang distribution.
What actually happens is you’ve got your leader queue process which will be created. And if you set an HA policy, you get follower queues which are created on the other nodes. And as part of creation, the leader queue has got a coordinator process which it will use to interact with the GM group, basically.
This is because the leader queue cannot directly interact with the GM, instead it will use that coordinator. Each follower has a GM process which handle events and react to events through and publish messages across the cluster. This is your clustering, replication and synchronization algorithm.
Conclusion: Design and Architecture
I don't think we can strictly define the architecture of Rabbit. There's a whole bunch of things that can cause it to change. Plugins are going to change how RabbitMQ appears. Version releases are going to introduce new design changes. Just by the way you all are going to use it will affect the design. Finally, this was an attempt to explain how it works but it is ever changing. And everything we've talked about can be found in these two repositories:
[Applause]
