In this talk from RabbitMQ Summit 2019 we listen to Karl Nilsson from Pivotal.
Quorum Queues are a promising new RabbitMQ feature but how do they work under the hood? What were the design decisions and trade-offs that had to be made and what even is Raft? In this session Karl aims to explain how Quorum Queues came about and provide a high-level overview of the design.
Short biography
Karl Nilsson (
Twitter,
GitHub )
wrestles distributed systems for a living. He works for Pivotal on the RabbitMQ core team.
Lifting the lid on Quorum Queues
Thank you for your interest in this little talk about Quorum Queues internals. We will lift up the lid and take a look inside and see what we can find. It can be called a feature, a thing… a concept for which I have been thinking about for nearly four years.
I do remember my interview for joining the RabbitMQ team and I was speaking with Michael Klishin about Quorum Queues and implementing a queue on top of Raft.
I could have given you a standard and dry overview of the internals and what components and functions they have etc. But, when I started, I didn’t find it particularly interesting myself.
So, I will come and go a little bit off the topic – but, we are still focusing on Quorum Queues and approach the subject in a slightly different way. I am going to ask a question. It came to me when Michael and I were talking about implementing a queue on top of Raft. Don’t be worried if you don’t understand the question or the subtlety of the question. The idea is that this content will give you enough context to understand the question… and possibly the answer. And the question is: How can we make the snapshotting of a Quorum Queue state fast and efficient?

This is the main topic of our focus and hopefully by the end of it, you will gain an appreciation of the internals as a side effect of focusing on this topic. Just to back up a little bit...
Quorum Queues
- New replicated queue type in RabbitMQ 3.8
- Based on the Raft consensus algorithm.
You are probably already aware of the new replicated queue type in RabbitMQ 3.8. I am not going to be able to fit in a detailed explanation of Raft but, I am strongly hoping that you will be able to understand the key aspects of Raft as we go on.
First, I think we need to talk a little bit about consensus algorithms. This way, everyone would learn what the consensus algorithms do for us and why we need them. In the simplest terms consensus algorithms are:
- Agreement on a value in a distributed system (among different agents, processes or running on different server within the network.)
- In Raft this “value” is a log of operations.
- Log replication
What does Raft do for us?
I find it more helpful to think about Raft as this value that we agree on – being in a pending log of operations. Raft does log replication and that’s a very important aspect of Raft. But, this is as far as we are going to go in that direction and for now we are just going to focus on the log itself.
A Log of Quorum Queue (ish) Operations

Quorum Queues is a replicated queue implemented on top of Raft. We actually wrote a Raft library which is generic and not especially designed for Quorum Queues; it can be used for any kind of purposes for when to use Raft. Quorum Queues run on top of that library creating a sample log of operations in a kind of AMQP 0.9.1 language. This log has a monotonic index and it is in order. We have got two publish operations. This is 1 and 2.
After that, a consume operation comes in. A consumer attaches and wants to consume from the queue. The next operation we get is an acknowledgment of the consumer having finished with message 1 (M1), which makes it ok to discard it. Then follows another publish operation and another acknowledgment operation. This is the actual log we are going to focus on today, and how it changes state. This log includes all operations that change the state of the queue.
You might have heard of other messaging systems that use logs which actually just puts the messages or the events into the log… it is not a set of full operations.
Another thing to bear in mind about the Quorum Queue and how it uses a Raft log. It is including message bodies. Meaning that the full message is in the log of operations.
So RabbitMQ Quorum Queues don’t use the message store. Reason being, if we put the message outside of the consensus system – we don’t get the consensus guarantees (without adding a lot of complexities and cross accounting between different systems). So when you get a publisher confirm, Raft provides the guarantees you need in your system in order to rely on it.
Quorum Queues - It’s all about the log
The log...
-
Is what is replicated across multiple nodes
- Always ends up exactly the same on all nodes
- Is persisted to disk
- Is what is "agreed on" (consensus)
- Used to calculate the current queue state
-
No operations are evaluated until they are safe
- Written to a quorum of nodes
- NB: fsync! (flushed to underlying storage)
Really, it is all about the Log – as you already figured out. It is what we replicate across multiple nodes. And the Raft consensus algorithms ensure that it ends up in exactly the same order and with the same contents on all the nodes. That is what Raft provides for us. It is persisted to disk. We use run these operations to calculate the current state of the queue, and we are going to go through this state transition flow in more detail. One thing that I would like to highlight: no operations are evaluated until they are safe; and by safe we mean that they are written to a quorum of nodes. Actually, that’s where the name comes from. The Quorum Queues need a Quorum of nodes to respond and say that they received each operation safely. It also gives a picture of the availability properties of the queue. Actually, you need a quorum available to make progress. Hopefully, this is what saves us from writing a lot of documentation. By naming it like that.
And, what is a quorum?
It is a majority in a set of nodes (more than half… saying that of three node replication factor, you will need two nodes to have the message; for a five node cluster, you will need three nodes).
And another point. They are fsynced. They are flushed to the underlying storage medium. Other systems usually provides strategies that you can apply on when and how often you flush to the underlying medium. But I think RabbitMQ Quorum Queues is relatively unique.
Actually, you don’t have a choice since we are going to fsync everything – doing it in the most optimal way we can.
State Transitions
Let’s go through the state transitions

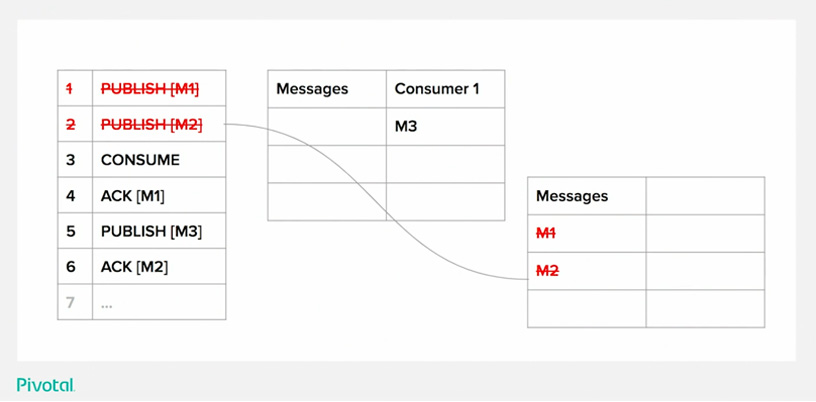
The table on the left is the log of operations and the table on the right is our queue state in a very, kind of cut down simplified form. Once we’ve processed the first publish operations, we have a single message on queue and that column is a list of messages or queue messages… and another message [M2] joins the queue and there are no consumers yet.
Then, we process the consume operation and we end up with a single consumer. For the purposes of this, the consumer has a single item of prefetch – and that is the prefetch of one (it can only have one single message in progress at any one time). So, it gets assigned this M1 message and the queue will deliver the message to the client, waiting for acknowledgment. When the acknowledgement comes in for M1, we remove M1 from the queue state… it’s gone!
Instead, we send M2 to the consumer and we assign it to the consumer. Another publish operation comes in that has to be queued up – because the consumer hasn’t yet acknowledged M2… but, eventually it does and it gets assigned with M3. Here is where we will stop for now in terms of state transitions.
As you can see, a lot of messages are no longer needed. This is a mutable queue – the classic AMQP type of queue. We delete the messages, we don’t keep them forever. But, the log has them, right? They are in the log. But then, you might see a slight problem with that, right? We need to truncate the log. Because this is an infinite growing log… it will grow and grow forever, until you exhaust a disk and the system won’t recover… and it will take a very long time.
One thing I missed is that – because we have this persistent log of operations… this is what happens in real time, when the queue is up… but, should we need to restart the node and recover the state of the queue, we do exactly the same thing. We just play through the log from the beginning to the end and we end up with the same state. So, that is a recovery phase. What we won’t do at that time is actually deliver the messages to the consumer. It kind of, enters a special state where it only does the calculation; it doesn’t do the delivery. But, that is how we recover.
But, we need to truncate the log. We can’t let it grow forever, right? In standard Raft, there is a snapshotting part of the algorithm. It is very simple: you take the current state (we have index 6) where we got no messages but, we have a consumer who has a single message outstanding. We serialize it to disk, fsync. And then after that, we can truncate the log. Then, next time we want to recover, we restart… we just read a snapshot state and then, any new entries we’ve got in the log that might have appeared whilst we were restarting. But, that wouldn’t be efficient, would it?!
Truncation is an efficient way of getting rid of the log. But putting the state on disk isn’t necessarily efficient. Because, in RabbitMQ, in this instance if we had only a single message – that would probably be fine. But, what about if we had millions?! We could have millions of messages on this. That is not going to be efficient, even if you have really efficient flushing to disk and all those kind of fancy stuff. It is not going to be efficient.
Also, you are kind of risking exhausting the disk transiently, because you need to write the snapshot to disk before you can truncate the log. And you have to do it in that order – otherwise it is not safe. You cannot truncate the log and then write the snapshot because you could crash in between. And, that is not good. This is kind of what the problem is, this is what the original question is about. We can restate it now to: “how can we snapshot without rewriting message bodies without writing to disk?”
Log Truncation
- Without it the log would grow and eventually exhaust disk
-
The current state can be snapshotted and put on disk instead of a prefix of log entries
- Truncation is more efficient than incremental "log cleaning"
- But the state contains message bodies! Potentially millions!
-
Not efficient
- Write amplicifaction
- How can we snapshot without (re) writing message bodies to disk?
- Hint: Quorum Queues are FIFI(ish) queues
How can we do the same thing but, without this kind of write amplification where we write messages over and over again, especially in big lumps? There is a hint. The solution comes from the fact that quorum queues are first in – first out (ish), depending on how many consumers you’ve got on the queue. So, messages that come in tend to get deleted or removed in roughly the same order as they are added to the queue.
Quorum Queue Snapshot [Index 6]
Having this in mind, we can do a different kind of snapshot. At this point, we are at index 6 and we acknowledged M2. We don’t need M1 and we don’t need M2. To recover to the same state we currently are, we don’t need those two operations.
Therefore we could at index 6, rather than take the state as it is in index 6, we take the state of index 2; redact the two messages that would have been there because we don’t need them. Then, write that to disk and truncate the log from a past index.
Does that make sense? Because, for me it’s been four years since we have been thinking about this. Because it is a first in – first out queue, we know that we are going to get an order that at some point we are going to have a sequence. A prefix of messages or publishers we can just delete and which we don’t need to recover. Instead, we can replace them with a nearly empty snapshot, which is small and efficient. It doesn’t need much time, we can do lots of snapshotting and keep the log under control in a reasonable amount of time.
Quorum Queue Snapshot Replay
So, just to kind of prove that – let’s go through the state transitions from the snapshot and to the current point. We have taken the snapshot and now we need to restart.
We have got our log, but now the log starts at 3 (3 – 6)… but, we are starting from an empty snapshot because that is what we’ve put on the disk. We took the messages out.
One important thing is that all of the intermediate state transitions don’t have to be 100% correct, as long as we end up exactly correct when we get to where we were (at 6).

So, consumer operation: add to consumer - and that is ok. Originally we would have had a message there but, that message has been deleted so it doesn’t have a message anymore.
We ack something [M1] but, we don’t have knowledge of M1 anymore, right? Because we’ve redacted it and it is effectively a no-op (no operation).
M3 goes on to queue as you can see. But shouldn’t it go to Consumer 1? Well, if you did get a little bit of additional state that I didn’t tell you about, it would have… but, we do keep enough information in the real world about the consumer to know that at this point. That you already got a message checked out – we just don’t have the message; we have knowledge that there was a message (or you may say a “ghost message”).
We then put the message on queue – rather than assigning it straight to the consumer because, if we assign it straight to the consumer – we wouldn’t be recovering to the correct state at the end. So it is very important that we don’t do that.
Then we acknowledege (ack) M2, and that does let us know that we can assign M3 to the consumer.
Now, we are back at the current state. And that is pretty much how Quorum Queue works! Those are the state transitions that happen within Quorum Queues.
So again. How can we make the snapshotting of a Quorum Queue state fast and efficient?
The answer is: Use FIFO (ish) properties of the queue to snapshot “in the past” to avoid including any message bodies.
Potential problems of using this strategy
There are some issues, and potential problems that might occur by using this strategy. But by requiring FIFO progress on the queue, there are certain things that could threaten that delicate kind of equilibrium.
Consumers that continuously reject messages. Does anyone do this?
- Don’t do this. If you don’t mind, at least - don’t do this on purpose… well, at least not with Quorum Queues.
- It violates the FIFO (ish) properties… it will hold, say it was the first message [M1] and it would never be able to go beyond M1. If M1 kept existing forever – you would have a consumer that kept consuming it and always returning it.
- Quorum queues include a feature that other queues don’t have and that is poison message handling. We do keep the count of the number of times we try to deliver a message to a consumer or the number of times it is being returned to the queue. And you can put a limit on that using the poison message handling configuration of the queue. It will then drop the message or dead letter the message after a certain number of free delivery attempts. If you are using Quorum Queues, you should configure this.
- Consumers that never ack and never disconnect and never crash… they get a consumer message and they sit on it forever… this is a “faulty” consumer if you like; but, it can also threaten the First In – First oOut progress. For that we have a consumer_timeout which operates at a channel level so, if the message hasn’t received an ack for a message for a certain amount of time – it will determinate and thus, it will return the message to the queue. Then someone else could consume it and the queue continues with making progress.
And that is pretty much all I had to say about Quorum Queues internals. Thank you!
[Applause]
