RabbitMQ Summit 2018 was a one day conference which brought light to RabbitMQ from a number of angles. Among others, Michael Klishin from the RabbitMQ core team talked about 3.8 and beyond.
An update from the RabbitMQ team - What's new in RabbitMQ 3.8 and beyond
All right. Thank you for coming. Thank you to the organizers. It’s great to deliver an update on behalf of the RabbitMQ team.
Who am I? Michael Klishin
Let's get started. First of all, who am I? You may know me as the person who tells everyone on the mailing list, 20 times a day, to read the logs. I'm also a senior engineer at Pivotal, working in the RabbitMQ team. I have been a RabbitMQ contributor since about 2010, if I remember correctly. I use this handle @michaelklishin on most services ( Twitter , GitHub ).
Agenda
What are we going to talk about today? A little bit about what our team has been up to since 3.7.0, some future directions and what you can expect in 3.8, and maybe even beyond that.
RabbitMQ 3.7.0 release themes
Before we discuss that, let's take a look at what 3.7.0 brought. We had some themes that we never really explicitly mentioned. We wanted to make RabbitMQ easier to operate. And that comes, I think in my opinion, primarily in two areas. First of all, you have to have a service that's easy to deploy. Deployment these days happens - machines do that, not humans, so Day 1 operations. But, beyond that, you have what, at Pivotal, we usually call Day 2 operations which is basically everything else. That's Day 2 to infinity. You need to have a service that you know how to operate, that you understand the limitations of, that you can monitor and so on because if you don't have any of those things eventually your experience will be less than great. And, as with any release, we wanted to make things more stable and set some things up for future changes that we will be talking about today.
Deployment Automation Friendliness
Specifically, we have a new config file which is easier for humans to use. But it is also easier for machines to generate. We have a peer discovery subsystem in environments such as AWS or Kubernetes. You have to do very little for nodes to discover each other. We have stats that are stored on every node individually instead of just one node which was a pretty easy way to overload a cluster. We have operator policies and limits to enforce some of the limits because, as was mentioned in the previous talk, sometimes applications do things that developers don't expect and that affects the overall stability of your systems. Operators have to have something in place, some guardrails basically. There were none. There were other changes as well but that was one year ago, almost one a year ago.
What have we been up to in 3.7.x?
What have we been doing in 3.7 releases ever since? We focused on things that are not necessarily cool but are very important, in our opinion, - best practices, documentation, non‑breaking changes, as always, improving the ecosystem which is a pretty strong point for RabbitMQ.
Guidance and best practices
For example, we now have a doc guide and a pretty well-understood practice of blue/green deployments. This is a way to operate where you have your original cluster, you bring up a new one, and you switch traffic over. In my opinion, this is the lowest risk way of upgrading should anything go wrong, because you can always go back to the system you already have, so I highly recommend it.
Documentation
We have a repository, which I'm not yet ready to announce, but if you take a look on GitHub you will find a repo named workloads. it has various settings and recommendations. For example, for lower latency environments and so on that a couple of engineers at Pivotal have been working on. Sometimes it's remarkable how much you can improve and configure things if you understand your workload well.
We also have some doc updates. My favorite one is monitoring because it's a bit surprising to me but we still see a lot of people go into production without monitoring. Don't do that. It's not going to end well. We asked ourselves, “Why is that?” And we figured, “Well, we don't really have any monitoring docs, how about we add some and see if that works?”
We also have a guide in upgrades, updates to the production checklist, and a runtime tuning guide. I don't think that is live but it will be soon, definitely before 3.8.
Non-breaking refinements
We also have a number of non-breaking changes. I don't think it's worth going through every single one of them. We have Erlang 21 support. We have a Kubernetes deployment environment which has been refined. We are using the new config format in more and more places. We package cutting-edge versions of Erlang. You know how I learned about new Erlang releases these days? Our build system publishes a new update whenever there is a tag in the OTP bot, so I don't have to look for announcements.
Future directions: General Directions
But that's not why you came to hear me speak. You are interested in something cooler than that. What would you like to improve in the future? Well, honestly, the general idea is the same - make it the system that is more reliable, easier to operate, address unknown scalability problems, simplify upgrades, and, in the end, drop some homegrown distributed system algorithms. It's even worse than going into production without monitoring. It's very hard to get those things right. If you find yourself in a situation where, “Hmm, maybe I should implement a new distributed system algorithm.” Honestly, maybe you shouldn't. Try to look for something developed in the last 40 years. That might be suitable.
What problems are we addressing with RabbitMQ 3.8?
Reliability
This is the most painful slide but I have to go through it. If we have this general direction, we have to also acknowledge what doesn't work very well in RabbitMQ today. Otherwise, how can we possibly improve on it. Well, we have the suspects that I'm sure you know. In certain failure scenarios, recovery of RabbitMQ nodes is not a very well-defined process and it depends on a couple of things. Well, homegrown algorithms and mirroring. But also, the schema database used. Certainly, we will talk about that a little bit.
Which is why some resiliency tests, RabbitMQ currently doesn't pass them. Well, 3.7 doesn’t. Also, once you have a node failure, if a queue mirror, if a follower, has to sync with the leader replica, it has to transfer a lot of data - way more than necessary, even if it has been offline for a few seconds. That's clearly not great because it can cause, basically, a thundering herd kind of problem.
The schema data store used internally has originally been designed for very different workloads. I think it's a reasonable system in many ways but RabbitMQ users expect something else. They expect it to work differently from how it works today. It would be nice to find a way to address that. Lastly, RabbitMQ currently doesn't have a single write ahead log or operation log (depending on what database you're more familiar with) which, in particular, makes backups harder - incremental backups. It would be nice to get there one day.
Scalability
Scalability is another area. Mirrored queues use a variation of an algorithm called chained replication. Basically, the way it works is nodes form a ring and messages pass around the ring twice. Messages pass around the ring, then confirmations too. If you think about it, that's a linear algorithm. We all know how well that scales when it comes to growing your cluster. It's not DC aware. It was not really designed to be DC aware. It uses a lot of bandwidth.
Another area, which was mentioned in the previous talk, we support multiple protocols. We really want to support all of them to the best of our ability but currently they all build on a core which is very protocol-specific. it would be nice to both reduce overhead and simplify some code and avoid some, because protocols do not exactly match each other even though, in my opinion, next gen protocols are quite similar. You can run into correctness issues where one protocol expects things that the other one cannot possibly deliver.
Currently in progress
With that out of the way, we have a number of improvements that we're going to discuss. The first one is Quorum Queues. You can think of them as mirroring 2.0. They use a consensus protocol called Raft. I will, very briefly, explain what that is. OAuth 2.0 support. Mixed version clusters. This is not a promise of delivery but by the time 3.8 comes around maybe you will be able to temporarily have 3.7 and 3.8 nodes in the same cluster instead of doing blue/green or just shutting down all 3.7 nodes and then starting them back one by one. Protocol-agnostic core is another area that we are working on.
RabbitMQ 3.8 Quorum Queues
How does raft-based replication compare?
Let's start with Quorum Queues and specifically how do they compare to the mirror queues we have today. We will talk about Raft in a bit.
Improved Reliability
With Raft, recovery from failures is well-defined. in fact, I think, most of the Raft paper discusses how exactly recover from failure - the happy path is quite trivial. I will show it to you in two slides in a bit.
When a follower has to catch up with the leader after a failure, it only transfers the Delta as little as possible instead of the entire contents. That's a huge improvement. It passes certain resiliency tests. I'm not going to claim it passes all of them but those we have tried and those that are well-known in the community, it does pass, so there is that.
Because Raft uses a log of operations, then certainly it opens the door to a unified oplog which makes incremental backups possible. We are not there yet. Raft, itself, will not get us there. Well, Raft alone will not get us there. But now you have a system that is increasingly built around that abstraction.
Improved Scalability
Comparing to mirror queues, there is no ring topology. Replication is parallel which, I think, is self-explanatory. As I mentioned, it has more reasonable bandwidth usage. Actually, Raft has a reputation for being chatty. We’ve found ways to improve on that. We're going to cover that a little bit. Again, it doesn't give you cross-data center replication for free but it opens the door. There are existing systems that are cross-DC compatible and use Raft - specifically Raft, not a Raft-like thing, under the hood. It's doable. It's reasonably easy to reason aboutboth for us and for the users.
What is Raft?
What is Raft? It's a collection of algorithms and their collective goal is reaching consensus in a distributed system. it is implementer-focused so it was designed to be easier to explain, easier to reason about - specifically, recovery and cluster membership changes. it is proven by now and not just the fact that it has a formal specification. Several data services that you have used, without knowing it, adopted Raft extensively. As different as etcd console and CockroachDB. I'm sure, these days, there is more.
Raft: An Oversimplified Explanation
With Raft, we have a number of nodes. In this case, we have three. Every Raft cluster has a leader and all operations flow through it. Followers, they store replicas.
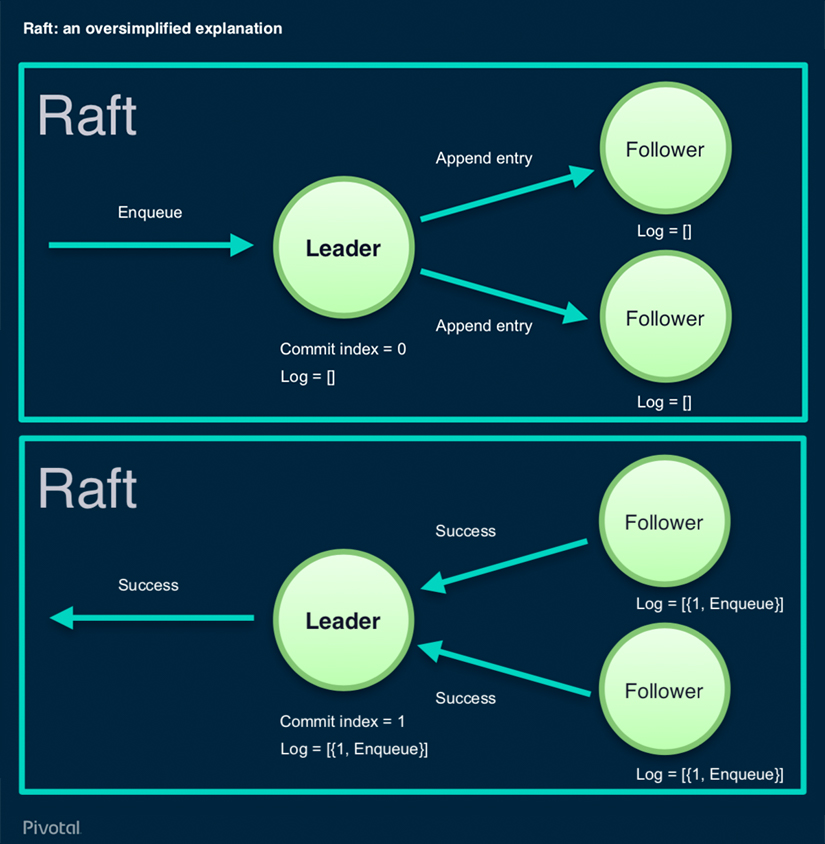
Let's say a command comes in like, “Hey, enqueue this message.” The leader has a log in the commit index. The log, you can think of it as an array, for the purpose of this discussion. The commit index is what's the latest operation that is known to be successfully committed on all nodes. The leader tells its known followers, “Hey, please append this entry to your log.” We can see that the log of those two followers is empty, in this case. They do that. How exactly they commit, it doesn't matter. Let's just say that Raft is pretty I/O-heavy. It really tries to be reliable and things should go to disk as quickly as possible, basically. Both followers. in this case, modify their log to have this index 1 operation in queue and report success. As soon as a quora of them, more than half, reports to the leader, the leader does its own commit increments to index and reports success to the client. That's basically it. How exactly leader election happens is not very interesting. It’s not particularly novel.
When followers fail and then come back, or a new follower comes back, there is a way in Raft to calculate the Delta reasonably efficiently and transfer just that. It sounds pretty straightforward. That's how it should be. Unfortunately, most consensus protocols aren't.
State of Quorum Queues
What's the state of Quorum Queues? They are reasonably polished. We have been working on them for slightly over a year, I think. I'm happy to report that its throughput beats mirrored queues because ring-based topologies are not exactly known for efficiency. Even though Raft is very I/O heavy, we’ve found ways to optimize that. You can expect, at least our tests which do not represent every workload, but they demonstrate that it is at least as efficient as mirror queues so you won't have to sacrifice things, at least, in terms of throughput, if you want to switch to them. It passes a slightly modified Jepsen test. I say slightly modified because we discovered some possibly unintentional things in the Jepsen test. We just had to modify it slightly. It doesn't mean we fully changed it. It is available, RabbitMQ, on GitHubs near you, in a release called 3.8.0-beta1. I don't remember if it's public. If not, I will make it public as soon as I'm done with this talk so you will be able to give it a try.
Implementing Quorum Queues
Quorum Queues has been a year of work. We had to implement a protocol which was not necessarily designed for this kind of system. Some of our team members talked about that in detail at other conferences, so you can search YouTube. Basically, we have our own from‑scratch Raft implementation in Erlang (GitHub). It's not verbatim RabbitMQ-specific. You can use it in any Erlang or Elixir project but, obviously, it was designed to fit RabbitMQ needs well.
It deviates from Raft a little bit but in ways that, we believe, do not sacrifice correctness. it includes a peer unavailability library which, again, is not a homegrown protocol. It's a paper that has been known for a long time. For some reasons, it’s not that widely used. This is what reduces Raft’s chatter because, in Raft, nodes periodically send the chatter, basically, hard bits saying like, “Hey, I'm there.” If you have 10,000 queues and they are all mirrored, then that's 10,000 Raft cluster's that generates like an unreasonable amount of traffic, so we just rely on this library instead of doing that chatter. Again, I don't think that sacrifices correctness and that's a serious deviation.
it is optimized for throughput as opposed to latency but it adapts the way it does I/O. If it has a huge backlog, it will basically fsync in larger batches. That helps with throughput but not latency. If it doesn't have any backlog, it will fsync in tiny batches, maybe sometimes as small as one message. That helps with latency and does not help with throughput. There it is.
The state of Quorum Queues in RabbitMQ
So far, it sounds too good to be true. It's like this awesome implementation which happens to be more efficient and doesn't reinvent any wheels and so on. Most distributed systems have some kind of trade-offs, so what sucks about this? There has to be something. Quorum queues have limitations. Specifically, they don't implement every feature. We hope to narrow this gap over time.
We believe that certain features such as TTL don't necessarily make sense. Why would you care so much about your data, and replicate it, and care about the recovery? Basically, overemphasize data safety and consistency, and then apply TTL to that just to throw that data away? If you want to throw that data away because your consumers can no longer use it, your consumers should make that decision. RabbitMQ should keep things around and TTL, by definition, means you don't keep things around.
Don't let me get started on other things like log synchronization and distributed system. There are all kinds of problems that you avoid by simply not supporting TTL. Queues themselves will support TTL. I'm talking about message TTL.
Memory management is not getting any easier with Raft or what not. In fact, with Raft, it's harder because it's so I/O-oriented. It remains in the area where we might want to tweak things once or twice before 3.8. So far, it has been quite good because we wanted to - our best-case scenario was reaching parity with mirror queues. We already surpassed that. Maybe we should stop right here but, currently, Quorum Queues keep their log in memory which you cannot have an infinitely long queue that way. We hope to address that. We will see how it goes and what happens to throughput. Ask me in a year.
As any major feature, it's obviously mature. We need your help with testing it, try to break it. we found plenty of ways to break in. Last year, we addressed them but we cannot possibly test every workload to come up with every single way of using Quorum Queue and mirrored queues. It's a new feature. I don't mean to discourage you, just keep that in mind. Don't deploy this first milestone into production just yet.
One queue type to rule them all?
A little intermission. I mentioned that maybe not all queue should support every feature. With this, we effectively introduced the concept of queue types whether we liked it or not. How about RabbitMQ today, so 3.7.x, has all these features. You can have a queue that is durable, auto-delete, mirrored, lazy, has TTL, has message TTL, has a length limit, has dead-lettering, has certain failure recovery settings, has exclusive consumers and can be like sharded, so affected by plugins.
One queue type per workload? Or, is there a better way?
What are the chances that it can be implemented efficiently for every combination of those or even most? It's probably unrealistic. How about, in the future, RabbitMQ will have queue types that are workload-specific? Some can be consensus that don't support TTL because maybe you don't need that, if you need those kind of guarantees. And you have transient queue that, by definition, they don't store anything on disk and don't do the pretty crazy memory management that regular RabbitMQ queues do today. But you don't expect them to do that.
You can have infinite queues. Basically, what lazy queues do today, maybe without some of the limitations, you can have lower latency queues - whatever exactly that means. That makes more sense to me. I I'm confident that our entire team believes this.
RabbitMQ OAuth 2.0 support - How does it work?
Let's keep moving on. We have OAuth 2.0 support. What that means is you will be able to provide the JWT token as a username. Every JWT token has scopes which are your permissions. They are translated to RabbitMQ permissions. This is not a breaking-change. Internally, nothing changes. You can still even combine that with LDAP if you want. I don't know I would but you can. We don't care how you obtain the token as long as RabbitMQ has a key to decrypt it and verify it.
Management UI will use a specific authorization flow because web applications tend to do that in a certain way. It makes sense there.
Officially supported clients will probably have some kind of total renewal because you, honestly, don't want to deal with that. It's a bit annoying. JWT tokens, by definition, expire on long-lived connections. You can run into a situation that your token has expired but your application still intends to use that connection. This has to be addressed. We believe this is mostly a client library and application concern because RabbitMQ technically could renew your tokens but maybe you don't want it to do that. It's just too much.
The state of Oauth 2.0 Support
What's the state of this? It's a plugin. It's already done. The core part has been sitting there on GitHub for months. it will ship in the next milestone, in 3.8. We just have to include it into the distribution.
Management UI still needs a bit of work but, in my opinion, that's the easy part in OAuth 2.0 support. It targets CloudFoundry UAA which is a user authentication and authorization service and via that Active Directory because that's what the majority of UAA users use. That's what we will test against for 3.8.
How does next generation schema storage compare?
Improved Reliability
Next generation schema storage. I already mentioned that RabbitMQ’s internal schema database is very opinionated. The way it recovers and handles failures, it just doesn't fit what distributed data service users expect today. We would like to have something that makes sense when it comes to failure recovery for RabbitMQ so that one part of the partition doesn't have to wipe itself out and completely sync, something that can integrate with this unified operation log that I keep talking about.
Improved Scalability
It can be an improvement in terms of scalability. But actually Mnesia, for what we use it for, does reasonably well there. What we don't like about it is the way it handles failures. We would like to have something that we can make this year very reasonably easier without doing major architecture, eventually. Mnesia has other limitations that would be too much inside baseball. You don't care about them. Let's just say that Mnesia is a data store which is over 20 years old.
What are the chances that it will have major breaking changes to address some of its known problems? I think the probability of that is about zero. By simply having something that doesn't heavily rely on MNESIA, we can increase our development iteration rate. With high developer iterations, usually come good products and improvements that ship sooner. At least, that's what we believe at Pivotal.
The state of Mnevis
We call this project Mnevis. By the way, the Raft implementation is called RA which is a prefix in Raft and RabbitMQ but also an Egyptian deity of some kind. Mnevis is another, I think, Egyptian deity. Don't ask why.
It's currently an area of experimentation. The idea is that, because we don't like the distributed aspects of Mnesia, “What if we replaced that but kept Mnesia’s transaction local storage?” because that part actually works reasonably well even though it's over 20 years old.
It turns out that Mnesia is very extensive. In fact, it's unbelievable. I have never seen a data store where you can replace a transaction layer with your own. Again, I'm not saying that you should but that's quite remarkable.
At this point, we don't think that Raft, without extensions, would be optimal for this kind of data store. Because we have a Raft implementation, that's quite tempting. That's what we are looking at. Raft introduces higher latency. For this kind of data store, we are not sure if we are willing to accept that trade-off. We will see what comes out of it.
Mixed version clusters: How do we get there?
Mixed version clusters, this is possibly my favorite feature. As you know, you cannot run a 3.7 cluster that has a 3.6 node in it. That primarily comes down to the fact that MNESIA actually has very specific ways of managing schema. If two nodes don't have matching schema, MNESIA will freak out and one of the nodes will fail.
Historically, RabbitMQ had very conservative restrictions. As soon as you try to cluster two nodes, they will check a whole bunch of things. If something doesn't look right, that operation fails. Relax some of those restrictions because they were not necessary. In fact, even in 3.6-- and we are migrating to not doing version testing, doing capability testing as well and using feature flags.
Currently, we have a prototype that's not merged. I don't know if that will be what will ship in 3.8 exactly. We have a prototype where you can cluster a 3.8 node and a 3.7 node, and enable 3.8 features on that 3.8 node, when you're ready, and everything-- at least in the relatively basic tests we did, just works. Basically, some 3.8 features are not available until you enable them. You will only be able to enable them once all of the nodes are all on 3.8.
Again, I'm not a fan of in-place upgrades but it paves the way for relatively straightforward in‑place upgrades. We hope that. It almost seems to be too good to be true, maybe that's all we have to do to enable this.
Our internal API's become pretty - if you are familiar with Erlang, they would seem pretty funny to you because Erlang records are actually a nightmare when it comes to version compatibility and all. Erlang has a lot of features for distributed systems and hot code swapping but its records are unbelievably archaic and non-extensible and actually make upgrades harder but we use them. Everyone uses them extensively. We have our own API that avoids using records the way they are meant to be used in Erlang to work around this. Well, that's the cost of doing business here, so to speak.
The state of Mixed Version Clusters
What's the state of mixed version clusters? Again, we have a pretty promising experiment. It's meant to simplify upgrades. We don't expect people to run mixed versions for a long time. It, honestly, makes no sense, especially with feature flags. Why would you run a 3.8 node if you cannot use any of its features?
Long-running cluster is not a goal there.
We cannot guarantee safety for every single workload because in a distributed system sometimes the only way to address the problem is to address internal nodes. If one of the nodes doesn't do the right thing, the rest might as well not be happening. Again, common workloads, so far so good.
It needs more feedback. Once we merge it, we will definitely ask all of you to give it a try.
What’s coming in RabbitMQ 3.8?
RabbitMQ 3.8, I keep referring to it. What is it going to include? We are certain that it will include quorum queues, OAuth 2.0. Hopefully, initial mixed version cluster support. There are minor technically-breaking usability improvements. Nothing major but there are certain things that we decided that maybe we shouldn't merge into 3.7.
What’s coming in RabbitMQ 3.9?
That’s it. How about RabbitMQ 3.9? Anyone interested in RabbitMQ 3.9 updates? We would like to get protocol-agnostic core in 3.9. We will see why when we discuss 4.0. Yes, there will be 4.0.
The rest is on the table. If you have ideas about what you would like us to address - anything that's not like major breaking-changes, let us know.
RabbitMQ 4.0
4.0, finally, that’s where next generations schema data bus is going to ship. I don't know. Everything else is like all the breaking changes we can fit. The last time RabbitMQ shipped a major version was 2012, I think. We might introduce food replicators, tricorders. I don't know, transport beams. You can tell I'm a Star Trek fan.
Thank you
So, thank you. Let's open up for questions.
[Applause]
Questions and Answers from the audience
“Is a Docker image available for the latest build?”
We don't produce our own Docker image but the Docker image maintained by the doctor community - I think they have previews as one of the Docker files. Because we haven't announced 3.8 beta1 yet, they don't have that. There will be, hopefully, reasonably soon. Honestly, you can contribute it. It should be just a version log.
“Will the switch to Raft change the deployment topology in something like Kubernetes where currently you have, the Sentinel pods or something like that as well as the main pods? Will any of that change?”
Quorum Queues is an incremental addition. It doesn't break anything. Your mirrored queues are not going to become Quorum Queues overnight.
As far as I understand, absolutely nothing changes except - with Raft, you need to have the majority of your nodes online in order for the cluster to make progress. If you use Quorum Queues and you lose more than half of your nodes, those Quorum Queues will reject the operations. That's how Raft is designed to work.
If you think about it, reaching a consensus in a system that doesn't have the majority of nodes, is it really possible? That's the only major limitation.
We will publish documentation around that. There are certain things that operators need to be aware of but, basically, it's almost as non-breaking as we can possibly make it.
As far as deployments, specifically as Kubernetes go, I don't think that anything would change except for this Day-2 operations kind of moment that you have to keep in mind.
“What's the target release for the different queue types you were talking about?”
Effectively, 3.8 because we already have two types. We have Quorum Queues. We have mirrored queues. And one specific case of mirrored queues is a non-mirrored queue, with a single replica.
We need to re-factor some things internally. We probably will do that before 3.8. From there, because a new queue type is an incremental addition, just like Quorum Queue is, we will see how it goes. Again, we don't really have anything beyond protocol-agnostic core plan for 3.9 but I can see how we can introduce a new queue type.
I'm not going to name them but we have some pretty crazy just queue-type experiments that some of our team members did. It's basically blasphemy. No, I'm kidding. It introduced this feature not associated with RabbitMQ necessarily.
Are we going to ship them? I don't know. This is not a promise of delivery. Don't make any purchasing decisions based on that.
“When is the plan to release the version RabbitMQ 3.8?”
We don't promise any ETA. Sometime next year is all I can say. And also, 3.7 will be supported for some time after 3.8 ships. There will be a migration period anyway.
How far advanced is Mnevis?
An area of active research. It's not vapourware but it's not something that not only merged but we are ready to like, “Hey, here's a pull-request. Let's all QA and try to break it.” It's very much early days.
By the way, speaking of that, even if Mnevis was ready to be merged, 4.0 will not ship before 3.9, most likely. And definitely, not before 3 8. Your actual availability date will be a little bit further into the future.
“Is Mnevis just a fork of Mnesia?”
It's not a fork of Mnesia. it's an extension of Mnesia that uses Mnesia in a non‑local way and replaces replication. Well, the entire distribution layer, to be fair.
“Did you say the Quorum Queues will have data center awareness, so I can put them in different availability zones?”
Well, because they are structured around the log, we believe that it's not as scary as it sounds to make them datacenter-aware one day. They are not in 3.8 because we have to ship this thing first, get it reasonably mature, and then continue working on it.
The work on Quorum Queues, Raft, queue types and so on will, obviously, not stop with 3.8. But, at some point, we have to ship something. Especially since it will potentially include mixed version clusters and simplified upgrades. We are not trying to squeeze everything we can into 3.8. It makes no sense. It's also not the Pivotal philosophy - I had to mention that.
“Are there any plans to change the mirrored queue linear algorithm to something better?”
I think the only change to mirrored queues, at some point, will be they just go away. That's the only thing we can make because if you think about it replacing that algorithm is a breaking change. There is no way to not make it breaking. I think most people would not appreciate that. Basically, their eventual fate is just being deprecated and then removed. Don't ask me when it's going to happen. They have been around for many years.
