In the part 1 of this blog series, we covered the fundamentals of Change Data Capture (CDC). We recommend starting from there if you are not familiar with the concept of CDC, the problems it solves and some of its use-cases.
In this part, we are going to run a demo pipeline that helps us see CDC in action. To begin, let’s get an overview of the demo project.
The demo
Our demo will simulate an e-commerce platform's backend with two services:
-
Inventory Management Service:
On launch, this service will populate a PostgreSQL database with a new
product every five seconds. Each product would have the following fields:
- id
- name
- quantity
- Order Management Service: Ideally, this service would be responsible for processing an order. And expectedly, it will be needing data from the inventory service to check the availability of a product. One way to implement this, is to have the order service create its own local copy of the required data in the inventory service. For brevity’s sake we won’t be doing all that in our demo - we will stream changes from the inventory service down to this service and log these changes to the console.
CDC pipeline with RabbitMQ streams and Debezium server
Recall we illustrated in part 1 of this series that a typical CDC pipeline would have the following components:
- An upstream application: With some data source - a PostgreSQL database, for example.
- A CDC mechanism: Responsible for monitoring the database for changes, capturing these events and sending them down to the streaming platform as they occur.
- Streaming platform: Responsible for propagating the events it receives to the downstream component in real-time.
- Downstream application: “Application” is used here loosely to refer to any component that acts as the final destination of the data generated in the upstream application.
Do we have all the pieces of the puzzle in our use-case?
Well, we know that the Inventory Management Service is the upstream component and the Order Management Service, the downstream component. For our CDC mechanism, we’d use Debezium server and for the streaming platform, we’d use RabbitMQ Streams.
We are already familiar with the Order and Inventory services, next, let’s quickly look at RabbitMQ Streams and Debezium server.
RabbitMQ streams
RabbitMQ is a popular open-source message broker that has been widely adopted as a middleman, efficiently handling message flow between different software components. By doing so, RabbitMQ facilitates a decoupled process flow, allowing software systems to operate independently and communicate asynchronously.
For very long, RabbitMQ’s focus has been on the traditional pub-sub message queueing. However, the introduction of Stream Queues in RabbitMQ extends its core messaging model into the event streaming doamin as well, specifically addressing the needs associated with event-driven architectures and real-time data processing.
For our CDC pipeline, RabbitMQ will be our streaming platform of choice— we will leverage the stream queues in RabbitMQ.
Debezium server
Previously, we discussed that in the log-based CDC, the CDC mechanism connects to a database's transaction log to extract data. However, this process varies significantly between different databases. For instance, the method for extracting data from PostgreSQL is different from the method used for MongoDB. To implement CDC, should you develop custom solutions for each database type?
This is precisely the problem Debezium was created to solve. As an open-source, log-based CDC platform, Debezium introduces a unified interface for moving data out of various databases. It does so through a set of specialised connectors. Each connector is a component that connects to a specific database.
Initially created to only integrate with Kafka, Debezium uses connectors for various databases that attach to the Kafka Connect framework as source connectors. Recently, Debezium introduced Debezium Server, which allows the use of these connectors independently of Apache Kafka. Debezium Server operates in a standalone mode and includes built-in sink connectors for numerous messaging systems.
For our demo, we will be using the Debezium server along with:
- The PostgreSQL source connector to capture change events in PostgreSQL.
- The RabbitMQ streams sink connector to stream change events from Debezium to a predefined stream queue in RabbitMQ.
The illustration below describes what our CDC pipeline would now look like, with all the pieces of the puzzle put together:

In the image above →
- Inventory service will connect to a PostgreSQL database and insert a new product record every five seconds.
- Debezium server with a RabbitMQ streams sink connector will capture these changes and send them to a stream queue (products) in RabbitMQ.
- Order management service will connect to the RabbitMQ cluster and subscribe to the products queue, logging messages received to the console.
Running the demo CDC pipeline
To be able to follow the steps here, you will need some things upfront. The demo project is available on GitHub.
Pre-requisites
- Docker installed and some familiarity with docker — This tutorial uses Docker to run the required services.
-
You can
create a managed RabbitMQ instance
or you can
run RabbitMQ locally with docker.
Whichever route you go, take note of the following - we will need them in some
of the subsequent steps:
hostname, vhost, user, and password.
- If running RabbitMQ locally, hostname is “localhost” , default user is “guest”, and password is “guest”. You will have to grab vhost to use from the RabbitMQ management interface.
-
If running RabbitMQ on CloudAMQP, grab this information from your console’s overview page:
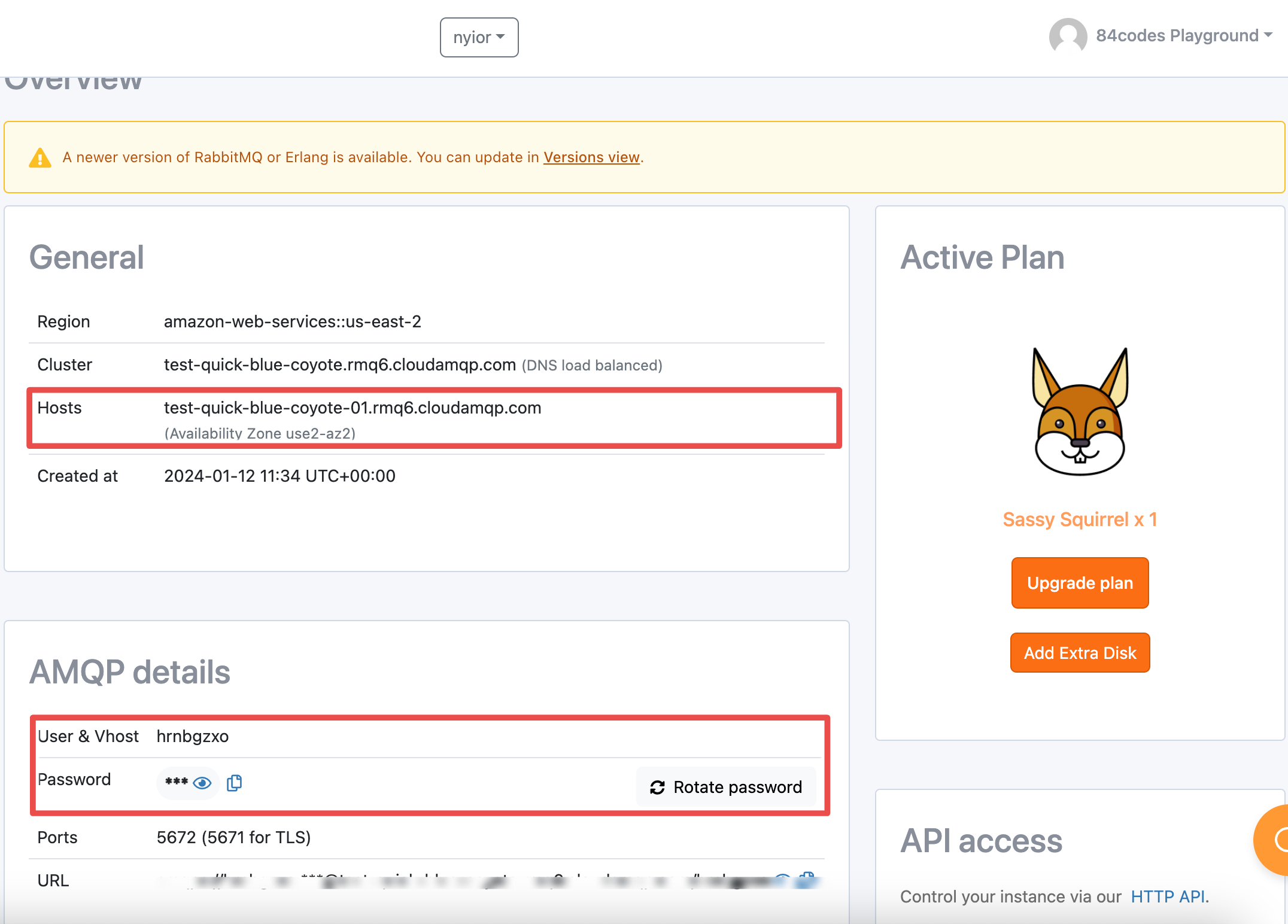
Step 1: Creating a queue, an exchange and a binding
Create the resources below in your selected vhost, the one you will also use in the subsequent steps.
-
In the management interface of your RabbitMQ node, create a direct exchange named
productsand a stream queue namedproductsas well -
Create a binding between the
productsexchange and theproductsqueue with the binding keyproducts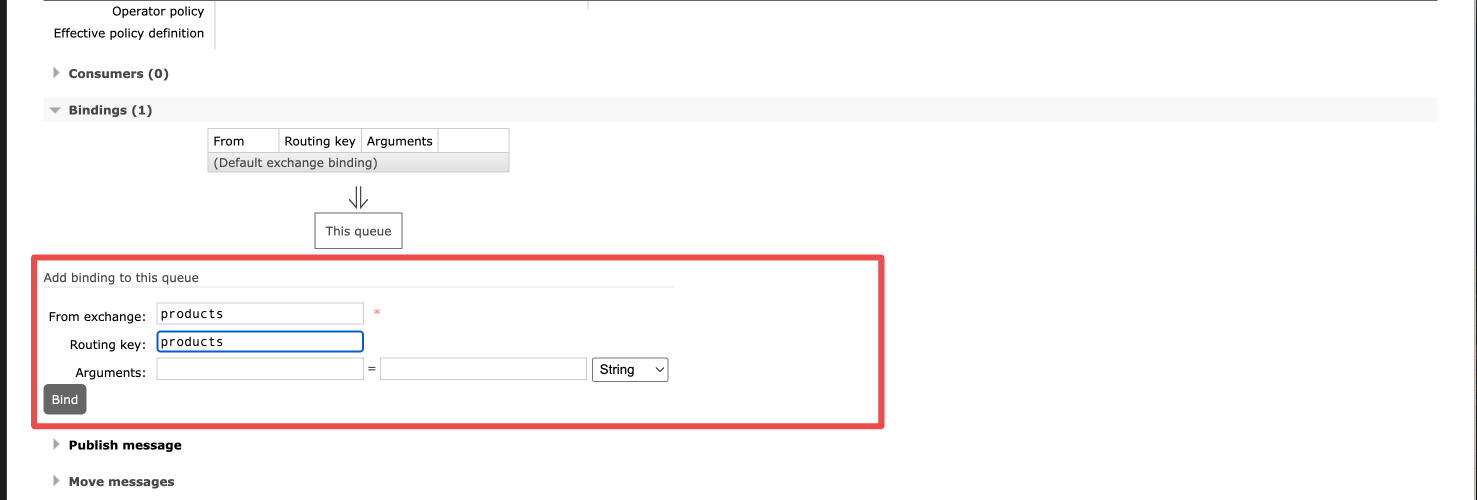
Step 2: Setting up the project repository
-
Clone the project:
git clone https://github.com/cloudamqp/rabbitmq-integration-demos.git -
Create an:
application.propertiesfile indebezium_conf/and add the content ofexample.application.propertiesto the new file -
In the
application.propertiesfile, update the following fields with your correct hostname, username, password and vhost, respectively:debezium.sink.rabbitmq.connection.host=your-host-url debezium.sink.rabbitmq.connection.username=your-username debezium.sink.rabbitmq.connection.password=your-password debezium.sink.rabbitmq.connection.virtual.host=vhost -
Create a
.envfile inorder_app/and add the content ofenv-exampleto the new file -
Don’t forget to update the URL in the
.envfile with the appropriate information.CLOUDAMQP_URL="amqps://user:password@host-url/vhost"
Note: In the subsequent steps, we recommend running each container in the foreground in a separate terminal. This way, all of the output of a container will be displayed.
Step 3: Build images
Navigate into the project directory and build the Docker images with:
docker compose build --pull --no-cache
[+] Building 13.6s (19/19) FINISHED docker:desktop-linux
=> [inventory_app internal] load build definition from Dockerfile 0.1s
=> => transferring dockerfile: 204B 0.0s
=> [inventory_app internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [order_app internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 204B 0.0s
=> [order_app internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [order_app internal] load metadata for docker.io/library/python:3-slim-buster 4.1s
=> [inventory_app auth] library/python:pull token for registry-1.docker.io 0.0s
=> [order_app internal] load build context 0.0s
=> => transferring context: 94B 0.0s
=> CACHED [order_app 1/6] FROM docker.io/library/python:3-slim-buster@sha256:c46b 0.0s
=> [inventory_app internal] load build context 0.0s
=> => transferring context: 1.07kB 0.0s
=> [inventory_app 2/6] RUN mkdir /code 0.8s
=> [order_app 3/6] WORKDIR /code 0.0s
=> [order_app 4/6] ADD requirements.txt /code/ 0.0s
=> [inventory_app 4/6] ADD requirements.txt /code/ 0.0s
=> [order_app 5/6] RUN pip install -r requirements.txt 4.9s
=> [inventory_app 5/6] RUN pip install -r requirements.txt 8.4s
=> [order_app 6/6] COPY . /code/ 0.1s
=> [order_app] exporting to image 0.3s
=> => exporting layers 0.3s
=> => writing image sha256:0c17e19dadd6d0bbcb3e91fffd0bb04f0bbb1bd4c25eb7766ed626 0.0s
=> => naming to docker.io/library/order_app 0.0s
=> [inventory_app 6/6] COPY . /code/ 0.0s
=> [inventory_app] exporting to image 0.2s
=> => exporting layers 0.2s
=> => writing image sha256:1070e3d6eea9328fb619ffb41f1356421385fcc2a0d9912b66beca 0.0s
=> => naming to docker.io/library/inventory_app
Step 4: Run the inventory service
Start the
inventory service
and since this service depends on the db service, it will also start that service automatically:
docker compose up inventory_app
[+] Running 15/15
✔ db 14 layers [⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿] 0B/0B Pulled 24.8s
✔ f546e941f15b Pull complete 3.3s
✔ 926c64b890ad Pull complete 3.1s
✔ eca757527cc4 Pull complete 2.7s
✔ 93d9b27ec7dc Pull complete 4.7s
✔ 86e78387c4e9 Pull complete 5.8s
✔ 8776625edd8f Pull complete 5.3s
✔ d1afcbffdf18 Pull complete 6.9s
✔ 6a6c8f936428 Pull complete 6.6s
✔ ae47f32f8312 Pull complete 12.1s
✔ 82fb85897d06 Pull complete 8.1s
✔ ce4a61041646 Pull complete 8.9s
✔ ca83cd3ae7cf Pull complete 9.5s
✔ f7fbf31fd41d Pull complete 10.3s
✔ 353df72b8bf7 Pull complete 10.9s
[+] Running 3/2
✔ Volume "debezium_rabbitmq_cdc_demo_postgres_data" Created 0.0s
✔ Container postgres Creat... 0.2s
✔ Container inventory_app Created 0.0s
Attaching to inventory_app
Step 5: Run the order management service
Start the
order service
with:
docker compose up order_app
Step 5: Run Debezium
Start Debezium Server with:
docker compose up debezium
How do I know that my demo works?
By the time you run Debezium in step 6, the
inventory_app
service has already
and should still be inserting some products into the database. Debezium will
start streaming these changes to the products queue. If your setup works, Debezium should
log an output similar to this (just the last 3 lines added here), indicating that it
is capturing the new changes.
debezium | 2024-02-25 10:15:42,326 INFO [io.deb.con.com.BaseSourceTask] (pool-7-thread-1) 5 records sent during previous 00:00:10.439, last recorded offset of {server=tutorial} partition is {transaction_id=null, lsn_proc=26766968, messageType=INSERT, lsn_commit=26766968, lsn=26766968, txId=817, ts_usec=1708856141585456}
debezium | 2024-02-25 10:16:02,007 INFO [io.deb.con.com.BaseSourceTask] (pool-7-thread-1) 10 records sent during previous 00:00:19.68, last recorded offset of {server=tutorial} partition is {transaction_id=null, lsn_proc=26768944, messageType=INSERT, lsn_commit=26768944, lsn=26768944, txId=827, ts_usec=1708856161720018}
debezium | 2024-02-25 10:16:40,598 INFO [io.deb.con.com.BaseSourceTask] (pool-7-thread-1) 19 records sent during previous 00:00:38.591, last recorded offset of {server=tutorial} partition is {transaction_id=null, lsn_proc=26772832, messageType=INSERT, lsn_commit=26772728, lsn=26772832, txId=846, ts_usec=1708856200119030}
Additionally, once Debezium starts streaming changes from PostgreSQL to the
products queue,
the
order_app
service should consume and log these messages to the console. Each message would look like this:
[✅] Received #b'{
"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"},{"type":"string","optional":false,"field":"name"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"tutorial.public.products.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"},{"type":"string","optional":false,"field":"name"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"tutorial.public.products.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false,incremental"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":false,"field":"schema"},{"type":"string","optional":false,"field":"table"},{"type":"int64","optional":true,"field":"txId"},{"type":"int64","optional":true,"field":"lsn"},{"type":"int64","optional":true,"field":"xmin"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"name":"event.block","version":1,"field":"transaction"}],"optional":false,"name":"tutorial.public.products.Envelope","version":1},"payload":{"before":null,"after":{"id":102,"name":"product-101","quantity":101},"source":{"version":"2.5.1.Final","connector":"postgresql","name":"tutorial","ts_ms":1708943362966,"snapshot":"false","db":"cdc_db","sequence":"[\\"26778128\\",\\"26778128\\"]","schema":"public","table":"products","txId":848,"lsn":26778128,"xmin":null},"op":"c","ts_ms":1708943363167,"transaction":null}}'
From the management interface, you should also see some activity on the products queue, if the pipeline works.
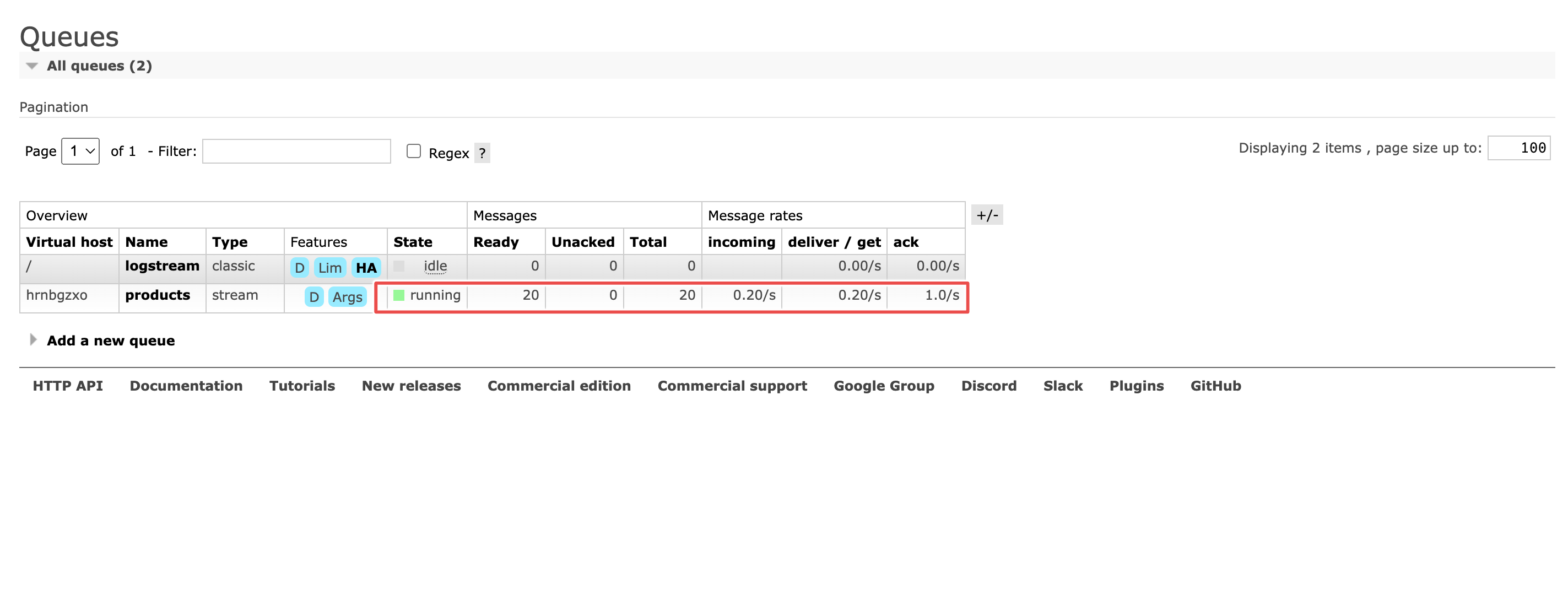
And there you have it: A working example of Change Data Capture with RabbitMQ, Debezium and PostgreSQL.
The anatomy of a change event
Earlier, we shared what the messages streamed to the
products
queue and by extension down to the
order_app
service would look like — re-formatted here for readability:
{
"schema": {
"type": "struct"
"fields": [
{"type": "struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"},{"type":"string","optional":false,"field":"name"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"tutorial.public.products.Value","field":"before"},
{"type": "struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"},{"type":"string","optional":false,"field":"name"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"tutorial.public.products.Value","field":"after"},
{"type": "struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type": "string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false,incremental"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"}, {"type": "string","optional":false,"field":"schema"}, {"type":"string","optional":false,"field":"table"}, {"type":"int64","optional":true,"field":"txId"}, {"type":"int64","optional":true,"field":"lsn"}, {"type":"int64","optional":true,"field":"xmin"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},
{"type": "string","optional":false,"field":"op"},
{"type":"int64","optional":true,"field":"ts_ms"},
{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"name":"event.block","version":1,"field":"transaction"}
],
"optional":false,
"name":"tutorial.public.products.Envelope",
"version":1
},
"payload":{
"before": null,
"after": {"id":102,"name":"product-101","quantity":101},
"source": {"version":"2.5.1.Final","connector":"postgresql","name":"tutorial","ts_ms":1708943362966,"snapshot":"false","db":"cdc_db","sequence": "[\\"26778128\\",\\"26778128\\"]","schema":"public","table":"products","txId":848,"lsn":26778128,"xmin":null},
"op": "c",
"ts_ms": 1708943363167,
"transaction": null
}
}
Let’s a take a moment here and dissect the structure of the change event that Debezium streams to RabbitMQ. A Debezium change event would usually have two parts:
-
A
schema -
And a
payload
The
schema
describes the fields in the
payload.
In our case, the schema says every payload would have the following fields:
-
opfield of typestring -
beforefield of typestructthat would in turn have theid, name, and quantityfields -
afterfield of typestructthat would also have theid, name, and quantityfields -
sourcefield of typestructthat has a bunch of other fields -
ts_msfield of typeint -
And
transactionfield of typestructthat also has its own nested fields
The
op
field describes the type of operation with a string value. Possible values are:
c
for create (or insert),
u
for update,
d
for delete, and
r
for read.
In our case, the value of
op
is
c
because it’s an insert operation.
The
before
field contains the state of the field before the event occurred.
In our case, the value of the op field is null because it’s an insert
operation and before the insert, the field was non-present.
If this was an update or delete operation, this field would not have been null.
The
after
field contains the state of the field after the event occurred.
In our case it contains the details of the new product inserted.
If this was a delete operation, then this field would have been
null.
The
source
field contains a structure describing the source metadata for the event,
which in the case of PostgreSQL, contains several fields.
The
ts_ms
field contains the time at which the connector processed the event.
Wrap up
In conclusion, while this blog series has focused on the integration of RabbitMQ with PostgreSQL, it's essential to recognise the extensive capabilities of Debezium. With its diverse range of connectors, Debezium opens the door to integrating RabbitMQ with an array of databases— from Cassandra, MySQL to MongoDB, among others.
In this blog series we configured Debezium server to stream changes to the stream queue using the AMQP protocol. However, you can configure Debezium to work with the native stream protocol in RabbitMQ.
As we wrap up, we invite you to share your thoughts on what integrations you'd like to explore next in the comment section. Or reach out to us directly via contact@cloudamqp.com
