RabbitMQ provides persistence by writing messages to disk before processing them so that they can be recovered if needed. Although the default persistence configuration generally allows for good performance, RabbitMQ is bounded to disk I/O performance, and changing the storage parameters for your RabbitMQ cluster can have a significant impact.
To achieve the desired effect, it is important to understand the configurations and their impact on a broker to know if it is appropriate to configure, but first of all, we will break down the most common terminology.
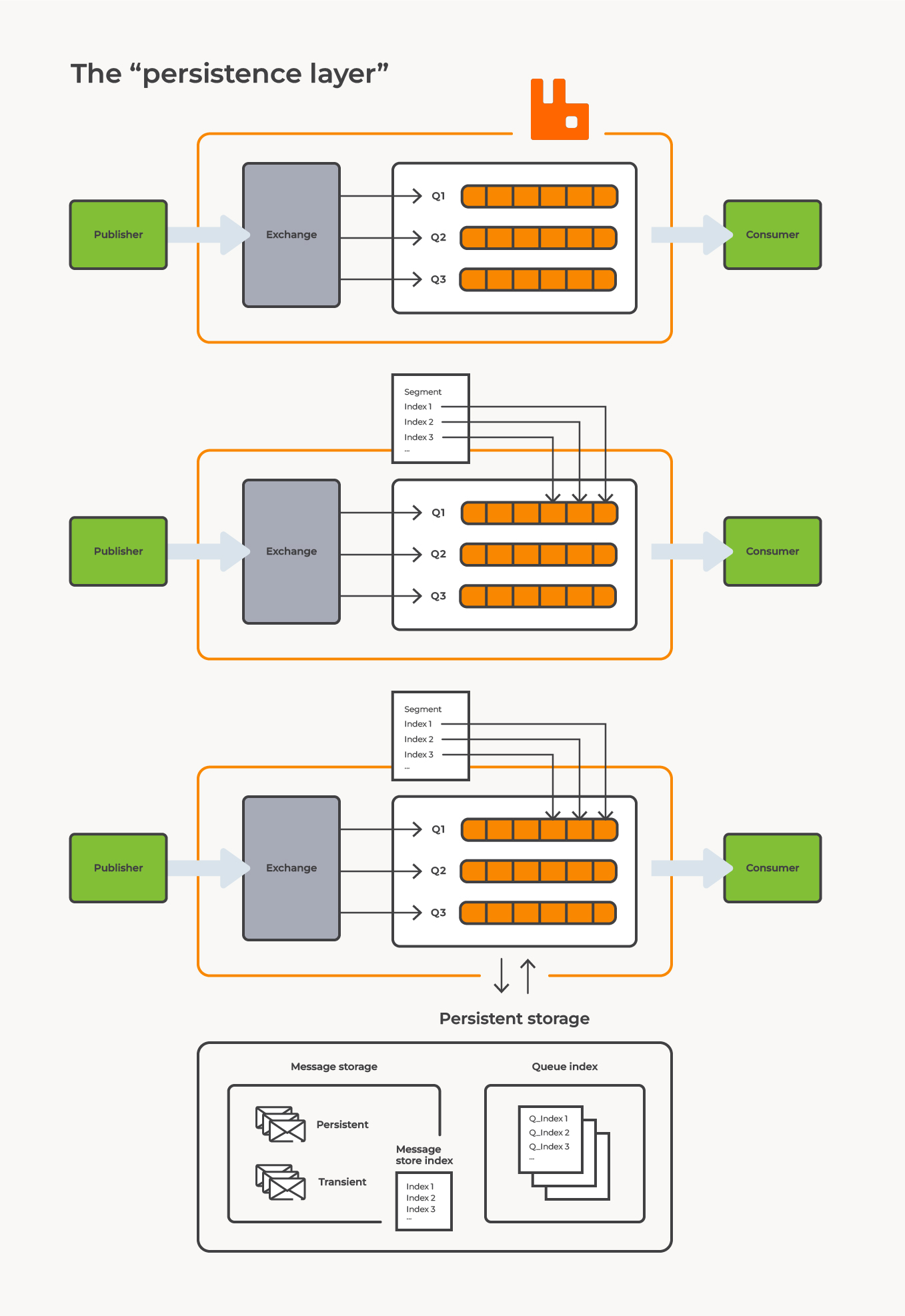
In this blog, we will refer to a non-replicated classic queue simply as a queue. The message store is a key-value store that stores both persistent and transient messages. The message store has a message store index, which keeps track of all messages in the message store. Apart from the message store, we also have a queue index for each queue which keeps track of each message's position in the queue. Smaller messages can be stored in the queue index alone and do not require an entry in the message store. The queue index is split up into segments each containing entries for a range of messages. The segments are then persisted to segment files.
Persistent message storage - How it works
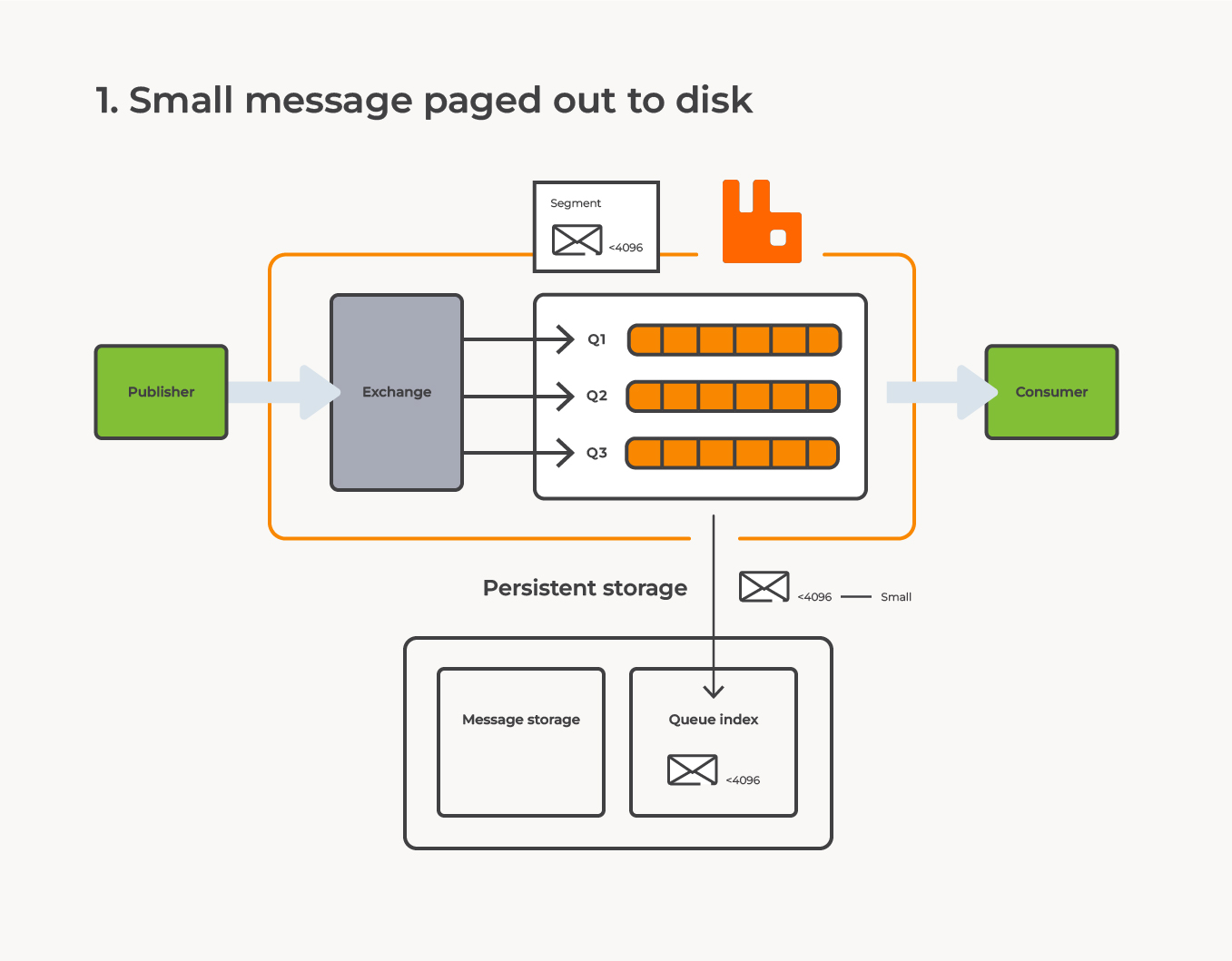
When RabbitMQ receives a message, it is either stored directly to disk to ensure persistence or held in memory as a transient message to optimize disk usage. The mechanism that helps store the messages is called the persistence layer, which consists of the message store and the queue index. The message store is shared by all queues on the vhost and is technically divided into two parts: the transient message store and the persistent message store. Here, the body of a message is stored using a message index to keep track of all messages. In addition, each queue has its own queue index, which records the positions of each message and whether it has been acknowledged or not. However if a message is small enough (< 4k by default), the whole message can be embedded directly in the queue index. We will explain later why this can be an efficient method.
During high-memory usage peaks, the persistence layer attempts to free up as much memory as possible by writing messages to disk. However, some message information must still be stored in memory, including some metadata for each unacknowledged messages, and a message store index that tracks messages in the message store.
Benefits and costs of message embedding
According to the RabbitMQ team, writing messages directly to the index store should be done to optimize small messages, determined by the configurable variable queue_index_embed_msgs_below. By default, the threshold is set at 4096 bytes, meaning messages below that size are written directly to the queue index. However, if this variable is set to zero, all messages will be stored in the message store, bypassing the queue index altogether.
Storing messages directly in the queue index has several advantages, including the absence of an entry in the message store index and no storage cost when the message is paged out. Additionally, the queue index can be almost completely evicted to disk, leaving only one segment in memory with a constant size, which is particularly useful for queues with a high number of messages.
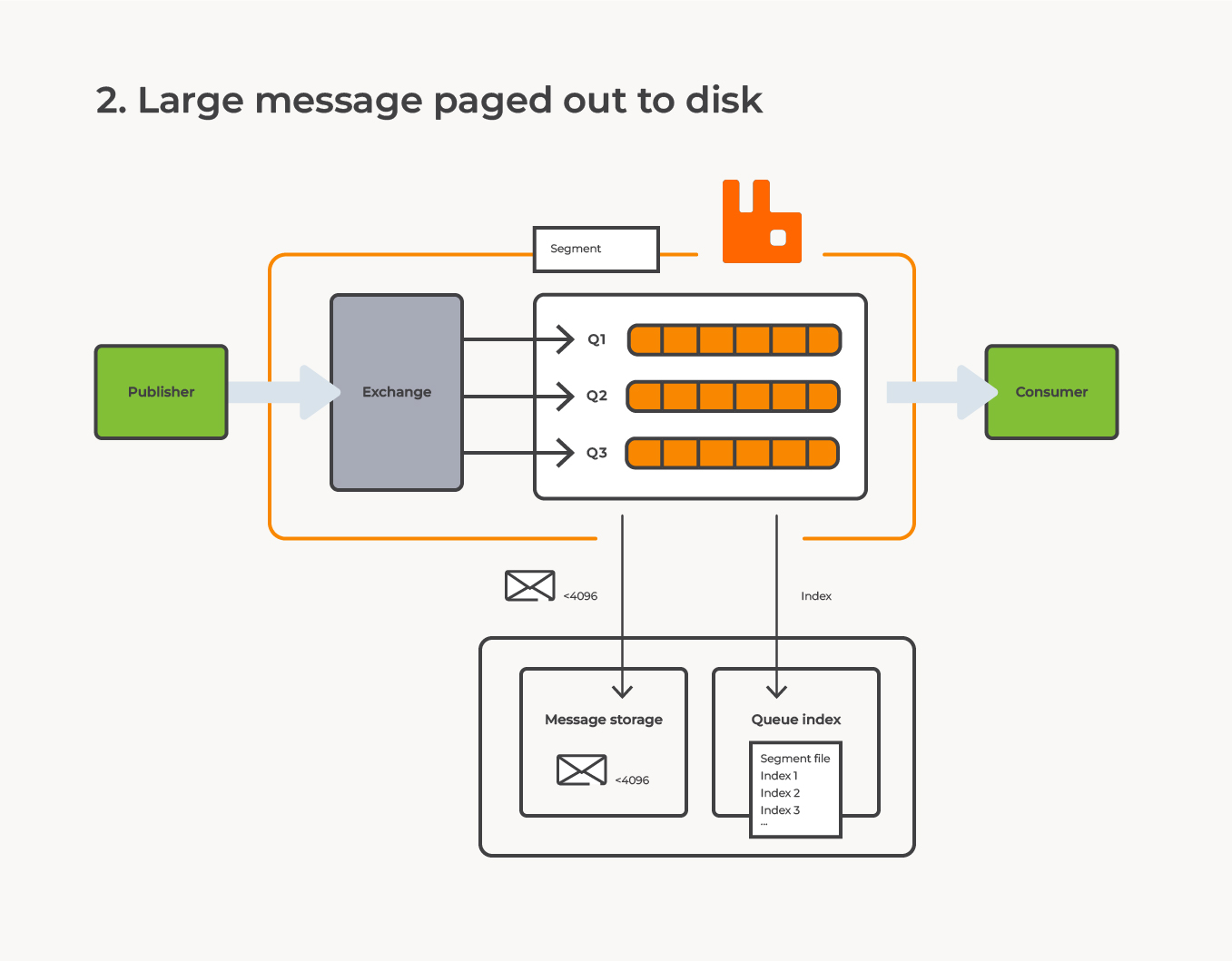
However, there are some cases where using the message store might be better. For instance, if there are many queues involved, storing messages in the message store can be more efficient. The queue index always holds at least one segment file in memory, and a small increase in message size can result in a large increase in memory usage. For example, if a message is smaller than 4096 bytes and is routed to 1000 queues, it will use 1000 x 4096 bytes, or 4096000 bytes. However, if a message is larger than 4096 bytes, it will use only 1 x 4096 bytes plus 1000 x 64 bytes, resulting in only 68096 bytes of memory usage.
Also, any unacknowledged messages stored in the queue index will always be kept in memory. This means that if there are many unacknowledged messages, they can consume a lot of memory and potentially cause performance issues. Finally, if a message is routed to multiple queues, each queue will store the entire message instead of just a reference, which can also increase disk usage.
In conclusion…
…RabbitMQ's persistence layer is a component that stores both transient and persistent messages to disk. The two central components of the persistence layer are the message store and the queue index. It is important to understand the relationship between these components when configuring the persistence layer to ensure optimal performance.
When deciding whether to store messages in the message store or directly in the queue index, it is essential to consider the size of the message and the number of queues it will be routed to. Storing messages directly in the queue index has advantages, such as a lower storage cost and the ability to evict the queue index from memory. On the other hand, storing messages in the message store may be more advantageous when dealing with many queues or larger messages.
Overall, a well-configured persistence layer can greatly improve the performance and reliability of your RabbitMQ cluster, and understanding the pros and cons of each configuration option is crucial in achieving optimal effectiveness.
