Quorum queues provide excellent data safety and high availability, but their disk usage patterns require careful attention to operational practices. Understanding how delivery acknowledgement timeouts affect disk space management is vital for maintaining healthy quorum queue deployments.
In this blog post, we'll explore the relationship between unacknowledged messages and disk usage, as well as how to configure delivery limits and acknowledgement timeouts effectively.
Understanding quorum queue storage architecture
Before diving into delivery acknowledgement timeouts, it's important to understand how quorum queues store data on disk.
Write-Ahead Log (WAL) and segment files
Quorum queues use a sophisticated storage architecture consisting of two main components:
- Write-Ahead Log (WAL): - A shared log across all quorum queues on a node that records all operations (message publications, acknowledgements, etc.)
- Segment Files: - Per-queue files where data from the WAL is eventually flushed for long-term storage.
The flow works as follows:
- All operations first get written to the WAL (both in memory and on disk).
- When the WAL reaches a predefined size limit (default 512 MiB), it gets flushed to segment files.
- Segment files can be truncated (deleted) periodically when it's safe to do so.
When segment files are truncated
Segment files can only be truncated when all messages within them have been acknowledged.
If even one message in a segment file remains unacknowledged, the entire file must be retained on disk. Additionally, all subsequent segment files will remain on disk until that message in the previous segment is acknowledged.
For instance, consider this queue with only one unacked message in it. This single message represents a ‘slow’ consumer. The message rate of pub/delivery is relatively high, with all messages being 1MB or larger.

The queue data is only 1MB according to the management UI. But the quorum directory on the server is rapidly increasing:
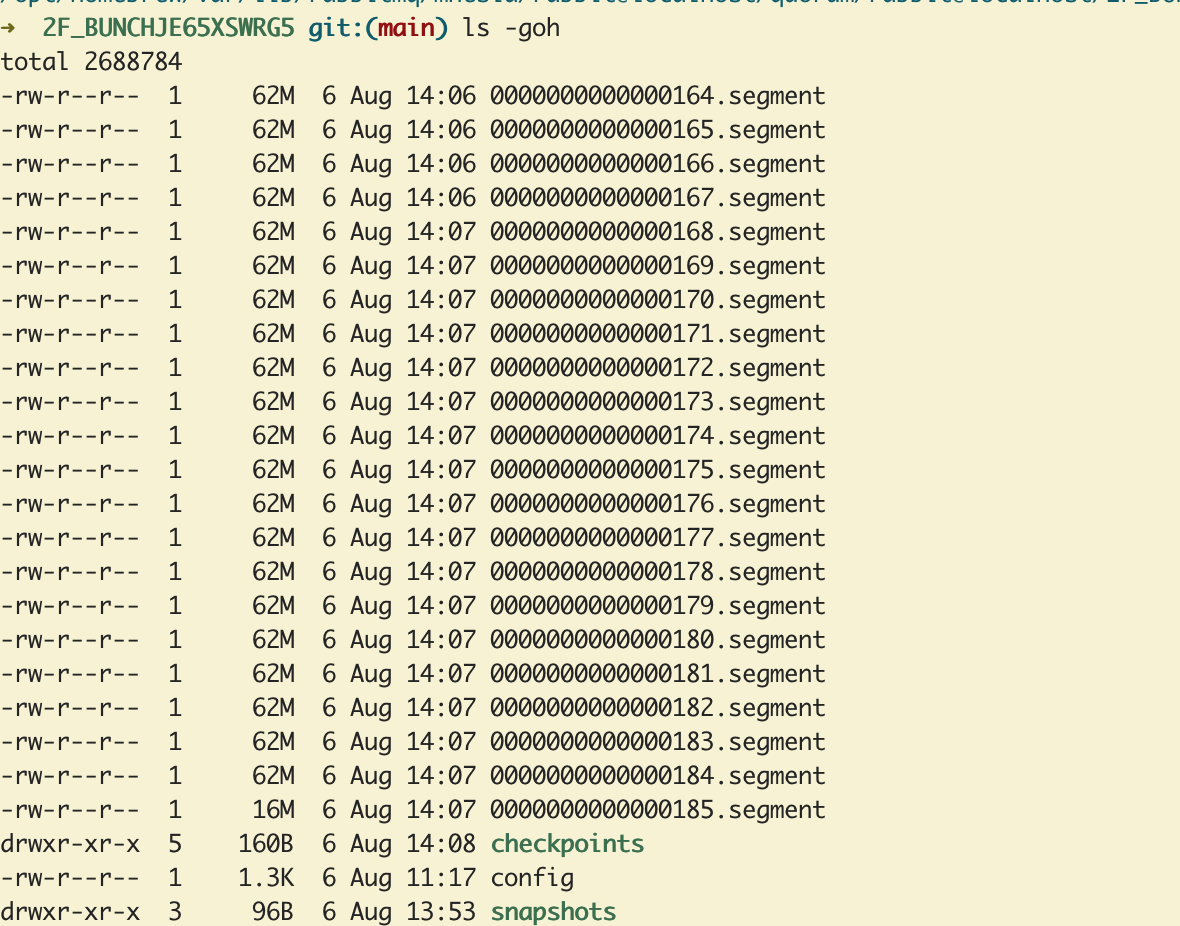
All subsequent actions written to the queue log files (publishes, acknowledgements, etc.) are stored on disk until the slow consumer finally acknowledges its message.
Update (July 2026): This behavior is greatly improved in RabbitMQ 4.3.0. Quorum queues now track how much reclaimable data has accumulated and trigger snapshots when garbage piles up, and the underlying Ra library performs major compactions that rewrite partially-dead segment files, keeping only the live entries. In practice, a single unacknowledged message no longer keeps all subsequent segment files on disk. Rerunning the scenario above, a workload that accumulated 737 segment files (~2.6 GB) for the queue on RabbitMQ 4.2.7 resulted in just 6 segment files (~1.4 MB) on 4.3.2. The guidance in the rest of this post still applies, but the disk impact of slow consumers is far less severe from 4.3.0 onwards.
The problem: long-running unacknowledged messages
When consumers fail to acknowledge messages within a reasonable timeframe, segment file accumulation becomes a serious issue:
Segment file accumulation
Unacknowledged messages prevent segment files from being truncated, resulting in continuous disk usage growth. This creates problems because:
- A single unacknowledged message can keep an entire segment file (potentially containing thousands of other acknowledged messages) from being deleted.
- Multiple segment files can accumulate over time, leading to rapid disk space consumption.
Performance degradation
Large numbers of segment files can impact performance, as the system must manage more files during operations.
Delivery acknowledgement timeout: your safety net
RabbitMQ's delivery acknowledgement timeout is a protection mechanism designed to detect and handle stuck consumers that never acknowledge their deliveries.
How it works
The delivery acknowledgement timeout works as follows:
- When a message is delivered to a consumer, RabbitMQ starts a delivery acknowledgement timer.
- For CloudAMQP, this is configured to 2 hours. Customers can modify this timeout in the CloudAMQP console. Under RabbitMQ ➡️ configuration ➡️
rabbit.consumer_timeout. -
If the consumer doesn't acknowledge the message within the timeout period, RabbitMQ will:
- Closes the consumer's channel with a
PRECONDITION_FAILEDexception. - Logs an error message indicating the timeout.
- Requeues the unacknowledged message.
- Closes the consumer's channel with a
Here's what an example of the error message looks like:
Consumer 'consumer-tag-998754663370' on channel 1 and queue 'qq.1' in vhost '/' has timed out
waiting for a consumer acknowledgement of a delivery with delivery tag = 10. Timeout used: 180000 ms.
This timeout value can be configured, see consumers doc guide to learn moreWhy this matters for Quorum queues
The delivery acknowledgement timeout is particularly crucial for quorum queues because:
- Disk space protection: It prevents runaway disk usage by ensuring messages don't remain unacknowledged indefinitely.
- Segment file rotation: By forcing acknowledgements or requeuing, it allows segment files to be truncated.
- System stability: It prevents individual misbehaving consumers from affecting the entire system.
Configuring delivery acknowledgement timeout
Global configuration
Configure the default value in your CloudAMQP console.
Per-queue configuration using policies
For more granular control, you can configure timeouts per queue using policies:
# Set a 1-hour timeout for all quorum queues matching the pattern
rabbitmqctl set_policy quorum_timeout "qq\\..*" '{"consumer-timeout":3600000}' --apply-to quorum_queues
# Set a shorter timeout for high-throughput queues
rabbitmqctl set_policy fast_queues "fast\\..*" '{"consumer-timeout":600000}' --apply-to quorum_queuesPer-queue configuration using queue arguments
You can also set the timeout when declaring a queue:
Map arguments = new HashMap<>();
arguments.put("x-consumer-timeout", 3600000); // 1 hour in milliseconds
arguments.put("x-queue-type", "quorum");
channel.queueDeclare("my-queue", true, false, false, arguments); Understanding segment file patterns
Segment files follow a specific naming pattern and storage organization that's important to understand:
File organization
- Each quorum queue member has its own set of segment files.
- Files are stored in the queue's data directory under the RabbitMQ data path.
- Segment files are numbered sequentially (example:
00000001.segment
,
00000002.segment
).
Tuning segment file behavior
The number of entries per segment file can be tuned based on your workload. We recommend setting a lower value (like 128) for messages over 100KB, and for smaller messages under 8k, we recommend a high value (e.g., 32768).
Currently, you will have to contact our support team to update this value in the configuration.
The redelivery problem
Beyond just unacknowledged messages, repeatedly requeued messages can also prevent segment file rotation. When messages are continuously redelivered but never successfully acknowledged, they create the same disk usage issues.
Note: Some of the commands in this section use rabbitmqadmin to connect to your cluster. To use these commands you will need to obtain a TLS certificate here. You will also need to create a config file for your instance as shown below.
Rabbitmqadmin config example, ensure all text is contained in quote marks as shown:
[default]
hostname = "CLUSTER_URL"
port = 443
username = "USERNAME"
password = "PASSWORD"
vhost = "VHOST"Why redelivered messages prevent rotation
When a message is redelivered multiple times:
- The message remains "live" in the segment file.
- The segment file cannot be truncated until the message is finally acknowledged.
- If the message keeps getting requeued due to processing failures, the segment file grows but cannot be cleaned up. The log begins to fill with the action “return” each time the message is not acknowledged. Read more about Requeued deliveries.
Protection mechanisms
Starting with RabbitMQ 4.0, quorum queues have a default delivery limit of 20 attempts to prevent this:
\# Configure delivery limit to prevent infinite redelivery
rabbitmqadmin --use-tls --tls-ca-cert-file=$CERTIFICATE_LOCATION --config=$CONFIG_LOCATION policies declare \
--name delivery_limits \
--pattern “” \
--definition '{"delivery-limit": 20, "dead-letter-exchange": "failed-messages"}' \
--apply-to quorum_queuesThis ensures that problematic messages are eventually dead-lettered rather than preventing segment file rotation indefinitely.
Best practices and recommendations
1. Choose appropriate timeout values
You can set up an appropriate timeout using the configuration tab in the CloudAMQP console for a global value:

2. Monitor and alert on timeout events
Set up monitoring to alert when delivery acknowledgement timeouts occur:
- Look for
PRECONDITION_FAILEDerrors in logs. - Monitor queue lengths for sudden increases (which may indicate requeuing).
- Track consumer registration/cancellation patterns.
- utilize CloudAMQP disk space alarms.
3. Design resilient consumers
Ensure your consumers can handle:
- Graceful shutdown: Acknowledge processed messages before shutting down.
- Error handling: Properly acknowledge or reject messages that can't be processed.
- Processing time awareness: Break down long-running tasks or increase timeouts appropriately.
4. Use dead letter exchanges
For messages that repeatedly fail processing:
rabbitmqadmin --use-tls --tls-ca-cert-file=$CERTIFICATE_LOCATION --config=$CONFIG_LOCATION policies declare \
--name failed_messages \
--pattern ^process\. \
--definition '{"dead-letter-exchange":"failed-dlx", "delivery-limit":5}' \
-—vhost $VHOST_NAME
--apply-to quorum_queues
This prevents problematic messages from causing infinite redelivery loops. On the DLQ, you can configure expiration and have messages dead-lettered back to the original queue for automatic retry. This way, segment files won't be impacted, and the message will automatically be retried.
5. Monitor disk usage patterns
- Keep an eye on disk space. Either using alarms, or by using one of our metrics integrations.
- Consider adding disk space to your cluster to ensure you can handle an instance of leaky segment files.
Troubleshooting common issues
High disk usage despite low queue lengths
If you see high disk usage but relatively empty queues:
- Check for long-running unacknowledged messages.
- Look for consumers that may be stuck or processing very slowly.
- Consider increasing the disk space of your cluster to handle growth. A good rule of thumb is that the segment file can grow for delivery timeout * delivery limit seconds, before message is either DLQ'd or discarded.
- Contact our support team for a breakdown of the quorum message store. We will be able to give you some hints on what queues are consuming most disk space.
Conclusion
Delivery acknowledgement timeout and delivery limits are critical configurations for quorum queue deployments. It serves as both a protection mechanism against misbehaving consumers and a tool for maintaining healthy disk usage patterns. By understanding how unacknowledged messages affect segment file rotation and configuring appropriate timeouts, you can ensure your quorum queues perform optimally while maintaining their excellent data safety guarantees.
Remember the key principles:
- Unacknowledged messages prevent segment file truncation, leading to disk space growth.
- Delivery acknowledgement timeout provides automatic protection against stuck consumers.
- Monitoring and alerting help catch issues before they become critical.
- Sufficient disk space consider increasing the disk space where needed.
With these practices in place, you can confidently deploy quorum queues knowing that disk usage will remain under control even when consumer issues arise.
Please send us an email at contact@cloudamqp.com if you have any questions about Quorum Queues and disk usage in RabbitMQ.
