RabbitMQ already has an existing solution for this, called Mirrored Queues or HA Queues. Mirrored Queues has been the de facto way of getting high availability and data redundancy for many years now, but the feature has some serious design flaws that has made it a less than ideal choice.
What is wrong with Mirrored Queues anyway?
The main problems are around the synchronization model and performance. Performance is slower than it should be because messages are replicated using a very inefficient algorithm. HA queue synchronization is a troublesome topic and RabbitMQ administrators live in fear of it.
The way that mirrored queues work are that there is a single leader queue and one or more mirror queues. All reads and writes go through the leader queue, and the leader then replicates all the commands (write, read, ack, nack etc) to the mirrors. Once all the live mirrors have the message, the leader will send a confirm to the publisher. At this point, if the leader failed, a mirror would get promoted to leader and the queue would remain available, with no data loss.
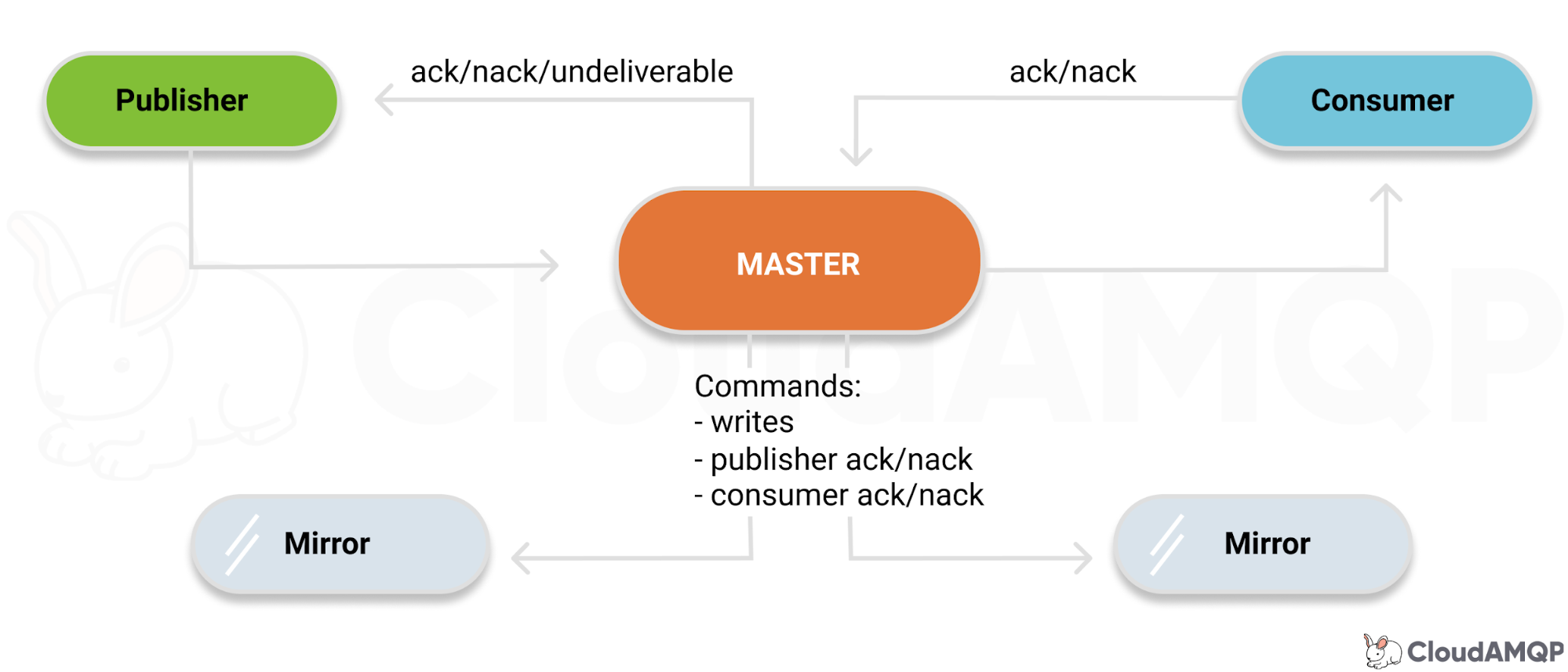 Fig 1 - Leader to mirror replication
Fig 1 - Leader to mirror replication
When you have multiple mirrored queues, the leaders and mirrors get distributed around your cluster, so each broker can host multiple leaders and mirrors.
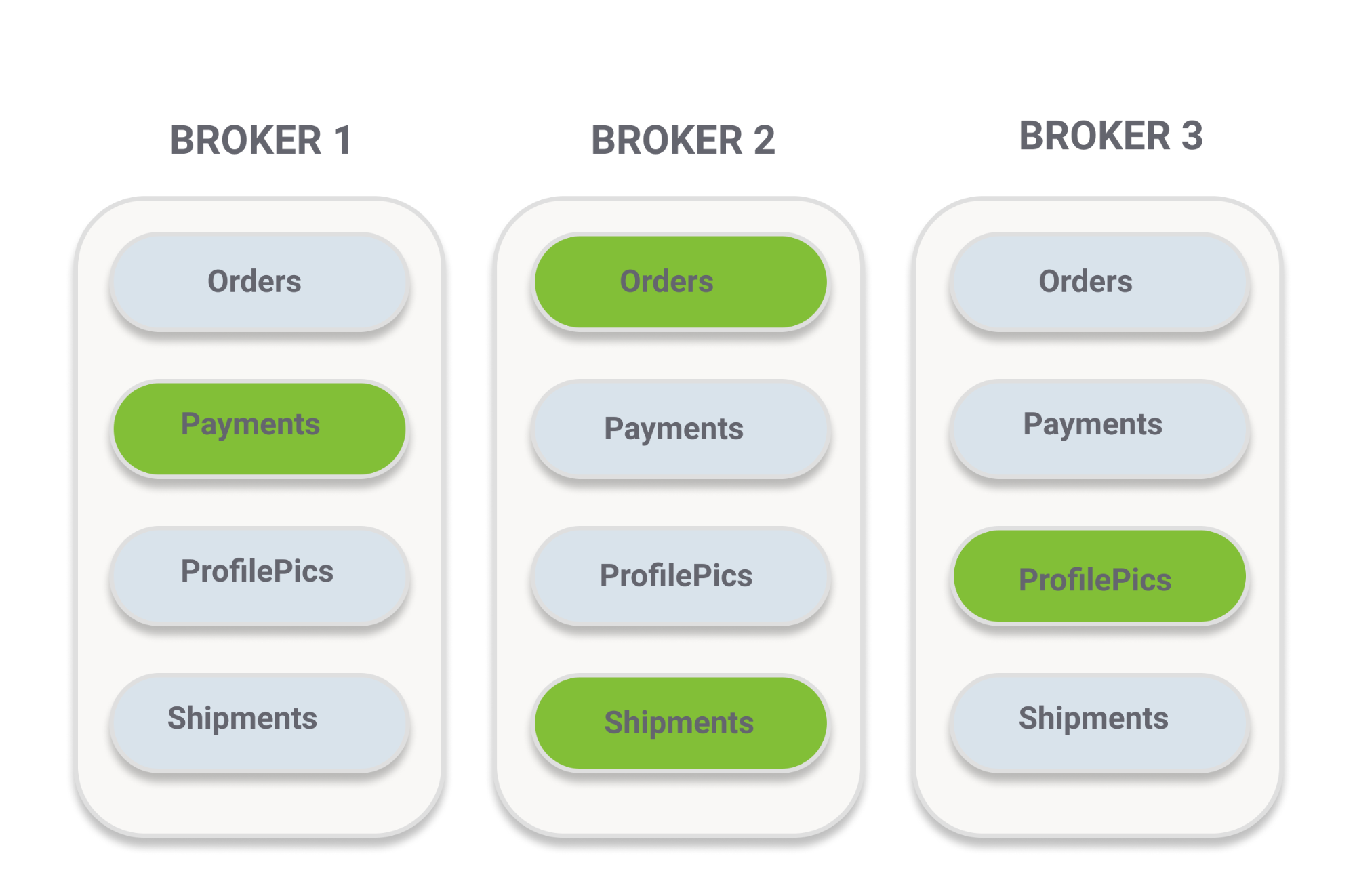
Fig 2 - Leaders and mirrors distributed across a cluster
The basic problem is that when a broker goes offline and comes back again, any data it had in mirrors gets discarded. This is the critical design flaw #1. Now that the mirror is back online but empty, the administrators have a decision to make: to synchronize the mirror or not. "Synchronize" means replicate the current messages from the leader to the mirror.
That's where critical design flaw #2 comes in. Synchronization is blocking, causing the whole queue to become unavailable. Usually, if everything is going well, queues should be empty or have a small number of messages in them. This is the usual healthy state. Messages are getting published and consumed at the same rate and messages remain in the queue for a very short time. But sometimes a queue can grow large, either by choice or because a downstream system is slow or offline. In the meantime, the system remains available but accumulating messages in its queues.
If you have no messages or a few thousand small messages, then the impact of synchronization is small. Synchronization will be quick and publishers can resend any messages that don't get accepted by the broker while it is unavailable. But when a queue is large, the impact is much greater. It can take minutes, hours or in very extreme cases even days to synchronize (though in most of the cases when we see this, the server crashes before it finishes, and then it needs to start over and over again). Not only that, but synchronization has been known to cause memory related issues on the cluster sometimes even causing synchronization to get stuck requiring reboot.
So sometimes administrators simply chose not to synchronize a mirror. All new messages would get replicated but any existing messages would not, causing reduced redundancy and exposing the cluster to a greater chance of message loss.
These issues also made rolling upgrades problematic as a rebooted broker would discard all its data and require synchronization to recover full data redundancy.
Quorum Queues - The next generation
Quorum queues aim to resolve both the performance and the synchronization failings of mirrored queues. But it does so with a reduced set of features in its first release and also introduces its own new headaches. Unfortunately we don't have an easy choice to make.
Quorum Queues uses a variant of the Raft protocol which has become the industry de facto distributed consensus algorithm. It is both safer and achieves higher throughput than mirrored queues.
Message Replication with Raft
Each Quorum Queue is a replicated queue; it has a leader and multiple followers. A common term to refer to these leaders and followers is the word replica. A quorum queue with a replication factor of five will consist of five replicas: the leader and four followers. Each replica will be hosted on a different node (broker).
Clients (publishers and consumers) always interact with the leader replica, which then replicates all the commands (write, read, ack etc.) to the followers. The followers do not interact with the clients at all; they exist only for redundancy, allowing availability when a RabbitMQ broker fails, is shutdown or rebooted. When a broker goes offline, a follower replica on another broker will be elected leader and service will continue.
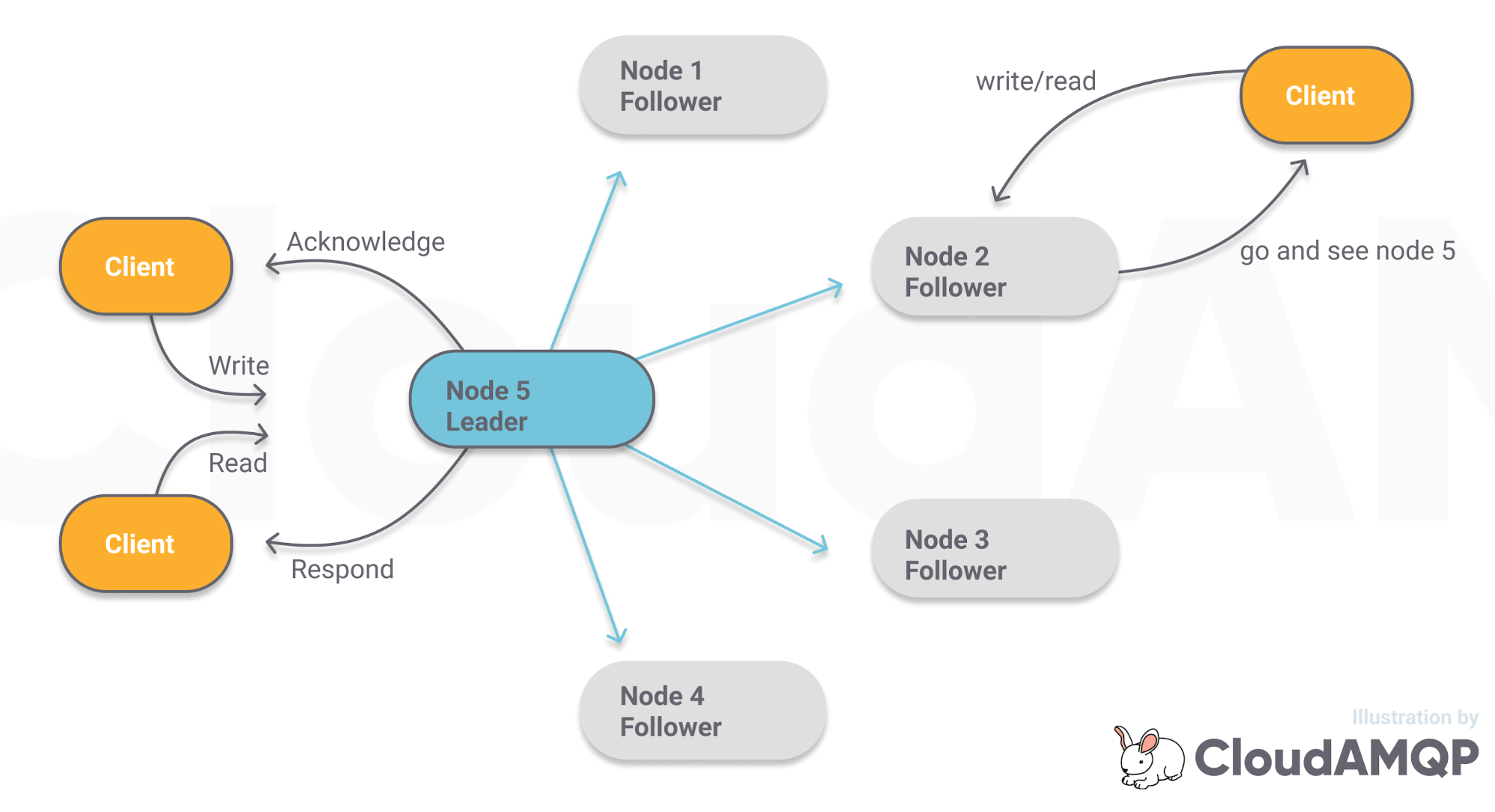 Fig 3. Raft consensus
Fig 3. Raft consensus
Quorum queues have their name because all operations (message replication and leader election) require a majority (known as a quorum) of the replicas to agree. When a publisher sends a message, the queue can only confirm it once a majority of replicas have written the message to disk. This means that a slow minority do not slow down the queue as a whole. Likewise, a leader can only be elected when a majority agree to it, and this prevents two leaders from accepting messages when a network partition occurs. So quorum queues are oriented towards consistency over availability.
Quorum Queues - The Good Parts
Firstly
Clients don’t need to change how they publish and subscribe, the queue type is not a concern to those operations. The only difference is when the queue is declared, it must be declared as a quorum queue. So if you rely on a client to do queue declaration, you’ll need it to add the necessary properties.
Secondly
The issues of synchronization are gone. When brokers come back online, they do not discard their data. All messages remain on disk and the leader simply replicates messages from where it left off.Replication of messages to a returning follower is non-blocking. So queues do not get so impacted by new followers or rejoining followers. The only impact can be network utilization.
This alone makes messages more durable than mirrored queues as there is not the risk of the synchronization problems. Also because each write must be written to disk by a majority of nodes, there is no risk of a split-brain scenario causing message loss. Note that sometimes no availability means message loss: if a publisher has no recourse but to discard a message then an unavailable queue will cause message loss, just outside of RabbitMQ itself.
Finally
Raft is more efficient than the mirrored queue algorithm and should provide better throughput.So far this all adds up to better throughput, better data safety, easier rolling server upgrades (like OS patches). But let's start looking at the downsides of Quorum Queues.
The Not So Shiny Parts
Less Features
Certain features will not be available in the first release or never. The list of features not available with Quorum Queues:- Non-durable messages
- Queue Exclusivity
- Queue/message TTL
- Some policies are not available. Only DLX and length limit are available.
- Priorities
- Lazy queues
- No global QoS
Disk Usage - Write Amplification
Quorum queues have a different disk and memory profile to normal queues.Normal queues have a shared storage model where a message is stored once and all queues that it gets delivered to simply get a reference to it. This means that in a publish-subscribe model, the fact that a message will be delivered to multiple queues does not cause the on-disk storage size to grow linearly with the number of queues.
Let's take the example of a fanout with 10 bound queues.
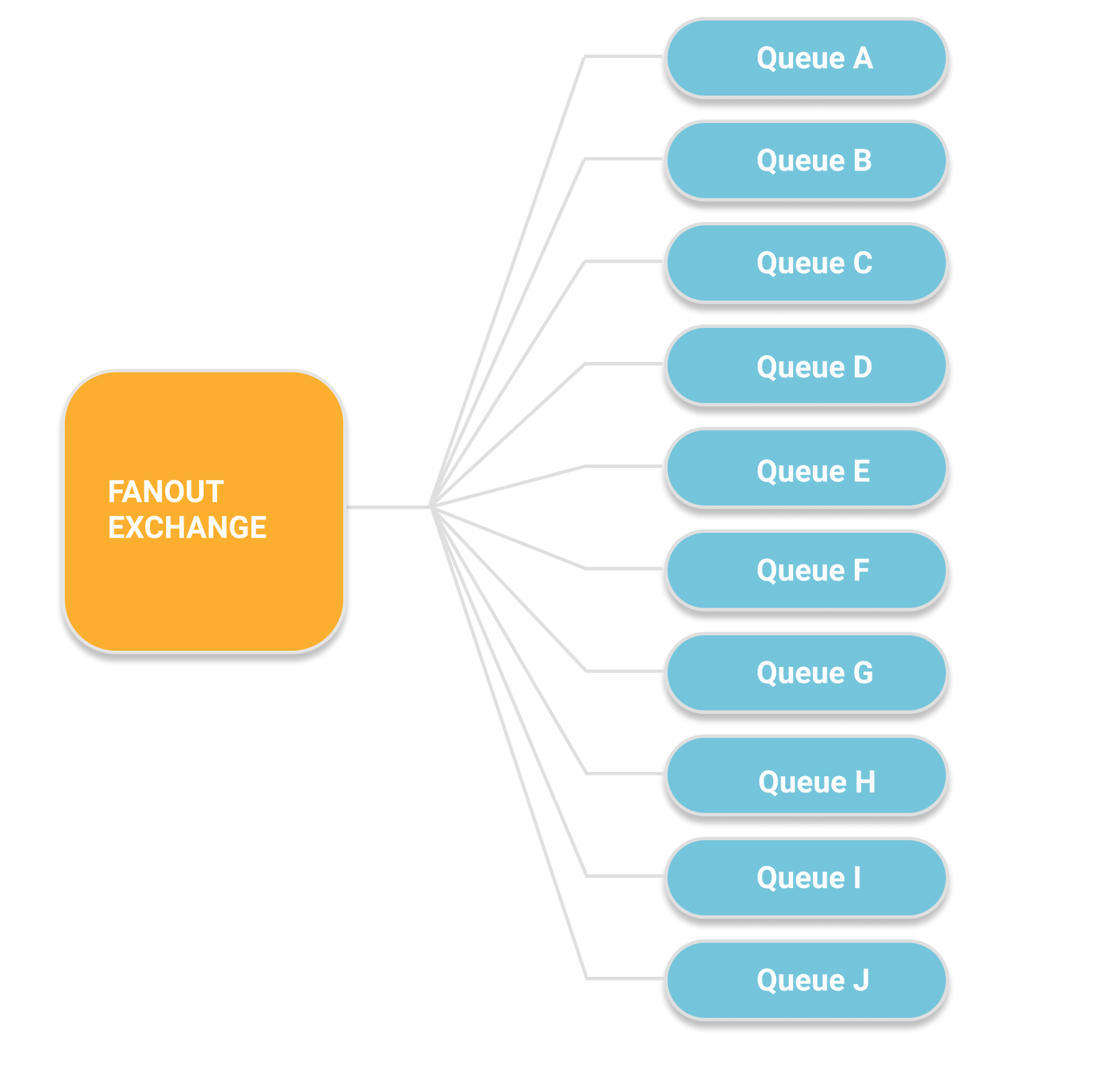
With each of the ten queues being a mirrored queue with a replication factor of 5.
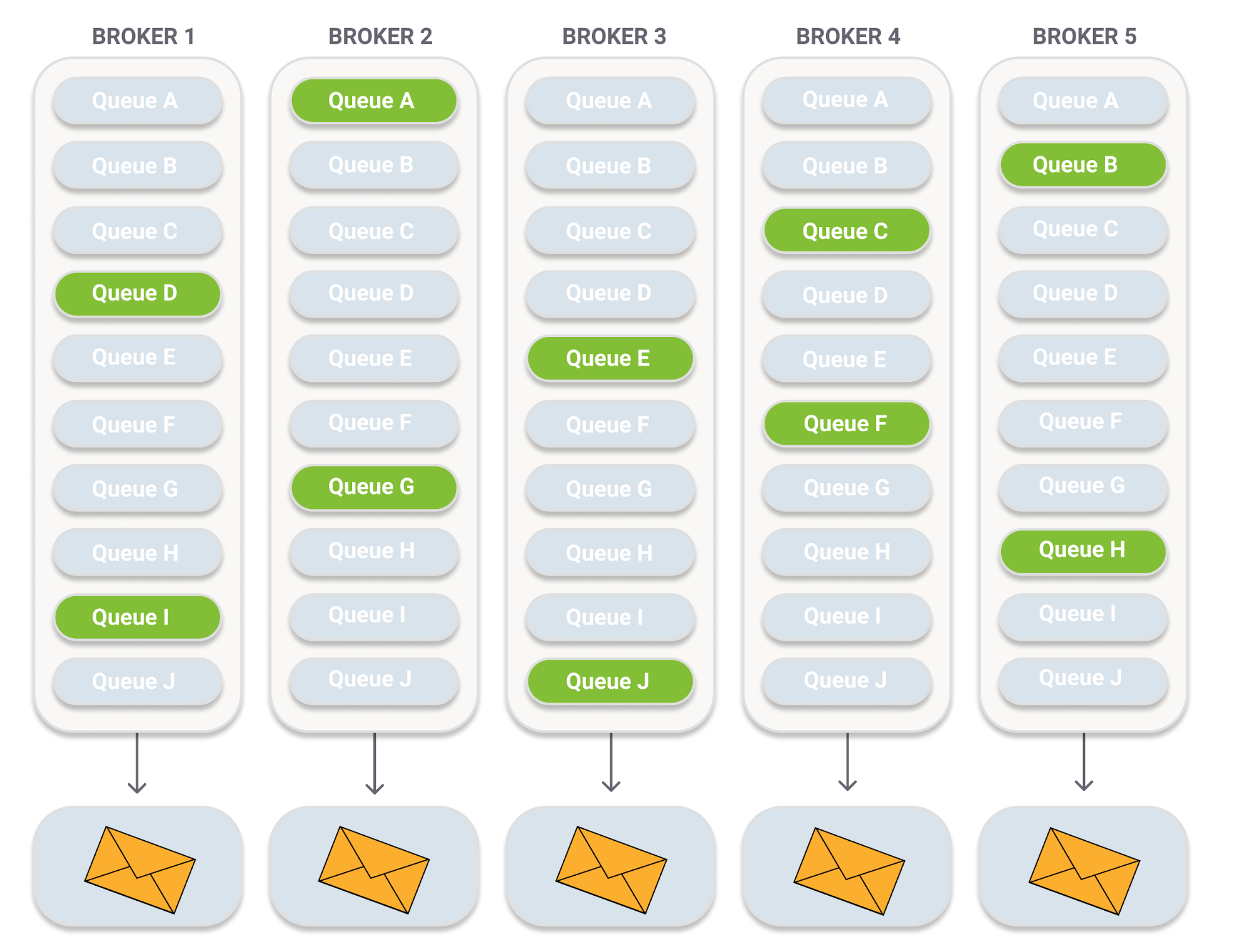
We end up with 5 messages stored across the cluster for each message sent to the fanout exchange = write amplification x5.
Quorums Queues on the other hand, only have a shared model in memory. On disk each message is stored separately, so publish-subscribe creates a write amplification that may make Quorum Queues infeasible or require higher end disks at best.
With each of the ten queues being a quorum queue with a replication factor of 5.
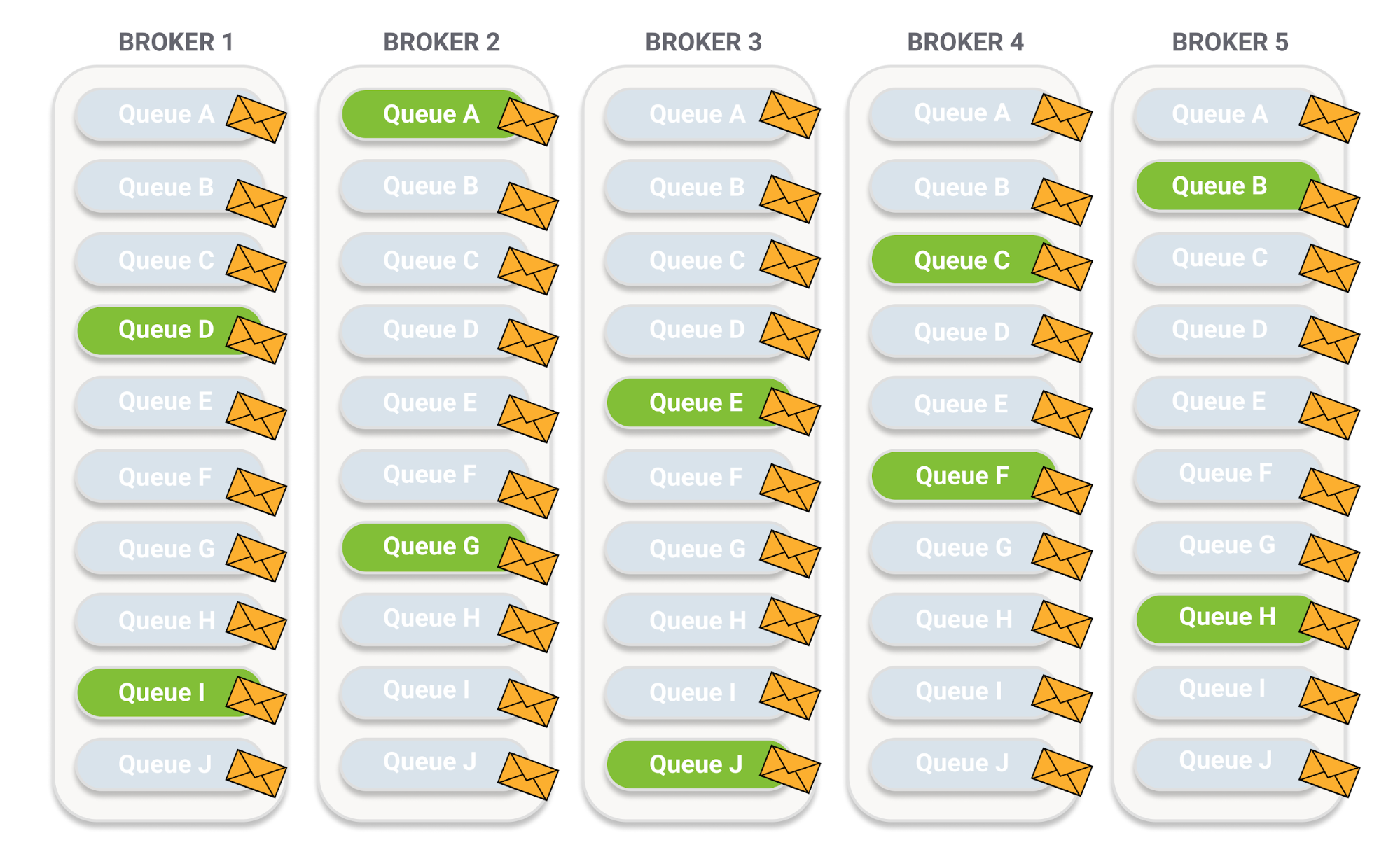
We end up with 50 messages stored across the cluster for each message sent to the fanout exchange = write amplification x50.
Fan-out is not well suited to Quorum Queues and massive fanout probably just isn't possible at all.
Memory Usage - All messages in-memory all the time
The fact that all messages in Quorum Queues are always in-memory at all times also increases memory usage, to the point that you can end-up causing unavailability of your cluster. If unchecked, a growing queue could cause all ingress to cease until messages get consumed and removed from memory. This is why when using Quorum Queues, it is vital that Length Limit policies are applied and messages are offloaded to lazy queues via a dead letter exchange.
This makes planning and monitoring ever more important. A downstream outage or slowdown could cause multiple queues to grow and you need to plan accordingly. How many quorum queues do you have, what is the expected ingress velocity, what other queues could be impacted if the cluster reaches its memory limit?
Permanent Loss of a Majority = Lost Queue
If a quorum of queue replicas is permanently lost, their data is gone forever, then even though a minority remains, the queue cannot be recovered and must be force deleted. This is an unlikely scenario, but the risk is there. Use reliable disks, and prefer a replication factor of 5 to 3.
Latency
While throughput is better, latency may be higher. This comes down to the use of Raft. We don't get non-durable messages and all messages are always persisted to disk across all replicas. Safety is the primary goal of Quorum Queues.
Only the Beginning
Quorum queues is still in beta right now, but later this year they will be included in the 3.8 release, ready for production usage. You can start playing with the beta version now which is pretty stable. You can find the latest 3.7 and 3.8 releases on GitHub
The first release of Quorum Queues aims for minimal features, concentrating on reliability and performance. The RabbitMQ team has plans to improve many aspects, including memory usage. So while not a silver bullet by any means, for certain use cases Quorum Queues offers a better alternative to mirrored queues. Read up more for yourself on the Next RabbitMQ page.
Please send us an email at contact@cloudamqp.com if you have any questions or feedback to this blogpost.
