In this talk from RabbitMQ Summit 2019 we listen to Lovisa Johansson and Anders Bälter from CloudAMQP.
CloudAMQP provides RabbitMQ clusters as a service, but what happens behind the scenes? It all runs on RabbitMQ servers that provide various functionality in setting up, configuring, monitoring and updating our RabbitMQ service. In this talk we'll go into how AMQP and RabbitMQ can be used to power a micro service architecture with flexibility and reliability.
Short biography
Lovisa Johansson (
Twitter )
holds an M. Sc. in Computer Science and Engineering. Her role covers many areas including content writing, documentation, customer support, growth marketing, and development. She has written numerous of technical guides online and has more than ten years of experience in product development.
Anders Bälter ( GitHub ) is a polyglot developer at 84codes. He has been part of the CloudAMQP team for a long time, where he has helped thousands of customer with their RabbitMQ architecture and hosting.
Running RabbitMQ at Scale
CloudAMQP provides RabbitMQ as a Service. Internally, we really rely heavily on RabbitMQ. Actually, a huge number of our events pass through RabbitMQ. Of course, we eat our own dog food and use CloudAMQP for production. This talk aims to give an overview of the automated process behind CloudAMQP while also showing how RabbitMQ has enabled us to evolve and improve our services.
History and how it all started.
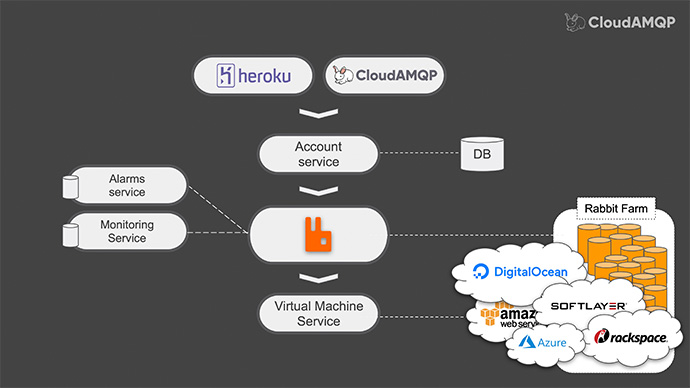
What we would like to do today is to go back to 2012. The year 2012 were simpler times one might say – but not for everyone. There was no hosted RabbitMQ as a Service. Our first goal was to provide RabbitMQ as a heroku add-on and we knew that we wanted the microservice architecture for reasons like flexibility, loose coupling and so on. So we started out with RabbitMQ server: some heroku end points, a database to keep track of stuff and AWS integration, and messages like: account create and account delete . That’s how it started.
As it turns out, users will misbehave or, at least some users will misbehave. Some users could easily create millions of queues or connections, or even channels – causing RabbitMQ to crash… and then it would need restarting.
As a paying customer you kind of, would want to get alerted when your server is close to exhausting its’ limits. All of these user requirements led us to create services for: Monitoring and Alarms/alerts.
Eventually, after some time and as a small startup, we found that it is a bit sad to give 30% of each subscription to heroku.
This led us thinking that maybe we should add our own customer portal that could also produce account delete and account create messages.
This is how slowly, the number of rabbits in our rabbit farm started to grow… as it also does in a normal rabbit farm.
Soon after that, we started getting requests to support other cloud providers and therefore, we created a few more subscribers for our – create and delete messages.
We added support for “Digital Ocean”, “Azure”, “Softlayer” and “Rackspace” and many others.
Even though giving 30% to Heroku made us a little bit sad, we realized that it actually gave us really good exposure. Still, 70% of one dollar is still much more than zero.
With this in mind we added endpoints for a bunch of other marketplaces. And with more and more RabbitMQ servers running, both the company and our customers needed to have better insight into the Rabbit. Therefore we added services to ship logs and metrics. In both of the cases, RabbitMQ was our “very good friend”.
To collect the logs for all the services we had, we used the RabbitMQ log exchange and created shovels to our own rabbit. Then we were able to add consumers that forwarded these logs to centralization service of choice like, “Papertrail” or “Loggly”. For metrics collection, we created a service that pulls richer member’s statistics like free disk space, used and free memory in the system and also data from the RabbitMQ management interface. Then this is published to RabbitMQ.
Then we were able to add a number of useful services that uses this metrics and for example, we could ship them to external services such as “DataDog” and “New Relic”.
We could also put them in our own time service database – to provide charts and to provide more sophisticated alerts, such as: queue matching “x”, has not had an “a” consumer for “y” seconds; or alarms that indicate the connection or channel leaks and warnings about unrouted messages etc.
If you wonder or worry that CloudAMQP relies on just one single RabbitMQ server, we would like to clarify that in fact, there are several servers: one is for business events; one is for logs; one is for metrics etc. We simply thought that the slides would look better if we illustrated this with only one server icon.
One thing that eventually started to annoy both us and our users was the lack of progress feedback in our web console. For the very quick tasks we could rely on the built-in RPC support in RabbitMQ - to get feedback back to the browser… for example, enabling a plug-in in RabbitMQ. it is really fast so we could just do that with RPC call. But, for longer running tasks we had to figure something else out.
For example, when you want to upgrade the RabbitMQ version – you had to refresh the browser to see if the version number changed. That might have been nice in 2012 – but, it is not that nice today.
We started including the session ID of each user initiated message. Then, we had our consumers publish the task progress messages to a new feedback service. These messages could then be forwarded to the user’s browser.
Another option we considered was to use RabbitMQ’s built-in WebSocket support – but that would mean that each page view on our web console would create a new RabbitMQ connection…so, we opted for this kind of proxy for the feedback instead.
And once we solved the problem, we pushed on towards adding more cloud providers like, “Google Cloud" and "Digital Ocean"; even more sales channels like “Azure” and the “IBM Marketplace”; adding also to the list metrics and log integrations like “Librato” and “CloudWatch”.
Since we are publishing our business events and metrics into RabbitMQ, it has been easy to continue adding new services that operate on existing data. We have been able to progressively improve our service without much risk of breaking existing functionality.
We are actually taking great care to never break anything within the environment where our customers’ actual servers are.
It has been a very rewarding experience to work in an architecture like this – where we are able to keep a quiet high pace. As an example, we have been able to be able to add new features for a customer just hours after receiving their request via email.
The requirements on our different services such as the metric and monitoring services have changed over the years. Take the metric service for example…in the beginning it only had to process a few messages per minute, while now it processes thousands of messages per second.
For good practice we do stay away from premature optimization which led us to quite a few rewrites of some services. Luckily, this neat architecture that is centered around RabbitMQ actually made such changes very easily.
With RabbitMQ we feel that we have the flexibility to choose the right tool for the right job. Our services are written in several different languages. We also have the possibility to scale services independently.
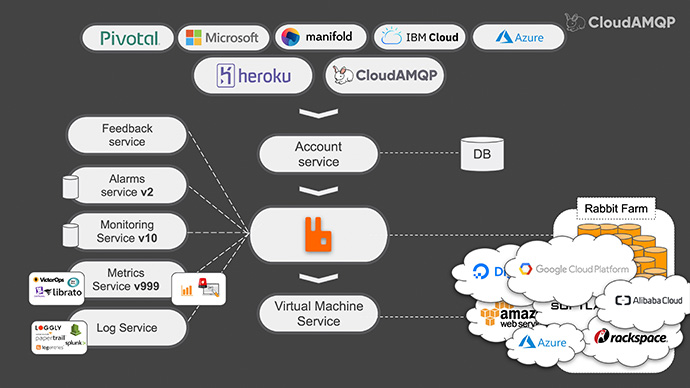
This architecture has served us so well that allowed us to grow from a one man company to a company of twenty people in a period of seven years. Now, one team can be working on the metrics service, while another team is working on adding a new cloud provider – without any interference. It has also made the process of onboarding developers really easy on this type of architecture.
Just by taking a look at the architecture, there is actually not much that is limited to providing RabbitMQ to our end customers. So we have since started providing PostgreSQL as a service, “Mosquitto” which is MQTT as a service and most recently, “Apache Kafka” – all using the same architecture. Apart from learning the ins and outs of these products, all we had to do was to add a few more consumers: one that installs Kafka instead of RabbitMQ; one that gathers PostgreSQL stats instead of RabbitMQ stats. And so on…
What we have learned through the years
After a period of seven years and after managing multi thousand RabbitMQ servers, with a total of 60.000 accounts, we have been able to gather some interesting statistics about typical and maybe not so typical RabbitMQ users.
RabbitMQ version distribution
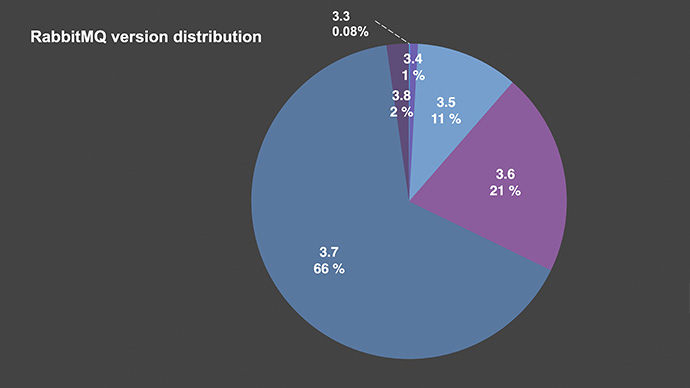
Most users (66%) are still on 3.7 – which is not at all surprising, since 3.8 has only been out for a month. Quite a few are on 3.5 and 3.6 whilst, some are happily still on 3.3. living by the motto: “If it is working, then don’t change it!”
How are people using RabbitMQ
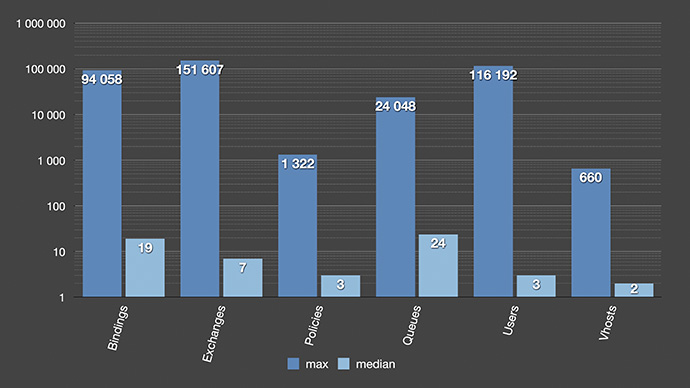
In case you are wondering just how are people using RabbitMQ?! Given chart explains that the left bar for each type is the maximum in any given server, while the right is the medium value. All the medium values look quite reasonable: there are 19 bindings, 7 exchanges, 24 queues… nothing crazy.
Is there anybody in the audience who is using more than 24 queues in their servers? Almost half… well, we are in the margins.
The one thing to note is that most people seem to stay away from policies and separating access with vhosts and users. We actually provision our servers with two vhosts, three policies and two users – and it seems like most people decide to just leave it like that and don’t use those features that much.
The maximum values are also interesting to look at. There is one cluster with 94.000 bindings and this developer has probably not learned about routing key wildcards. So, we might need to educate them about that.
The top exchange cluster with 151,000 exchanges is just looking weird. It is all fanout exchanges, and I couldn’t figure out a good reason for that setup. But it actually might be a good user story behind it.
For the top users cluster – it looks like all their end users get a RabbitMQ user as well and I am not completely certain that is a good idea if their service would face rapid growth.
RabbitMQ messaging statistics
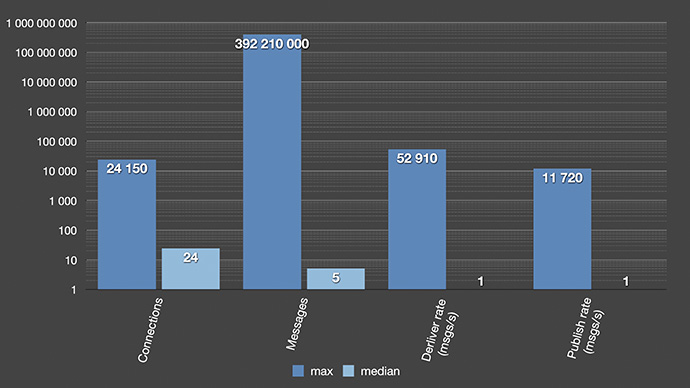
The fact that RabbitMQ performs best when queues are short seems to have reached most of the users. Which is nice to see. Even though someone seems to have confused RabbitMQ for a database with around 400 million queued messages. We also see that most users don’t use RabbitMQ for high frequency messaging as the median value for deliver in publishing rates are both really close to zero. Then, most of the messages are routed to more than one queue as the delivery rates are a few times higher than the publish rates.
Popular clients by connections
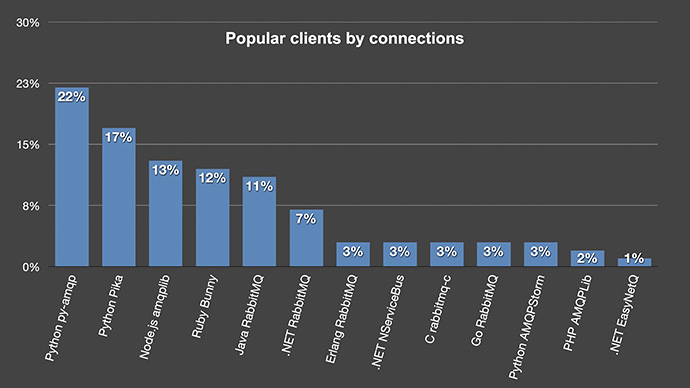
Taking a glance at which clients are most popular: having a look at the breakdown of a snapshot of 600,000 connections, we can see that a couple of different Python clients together with the Pivotal supported clients are the most popular.
We can see that Python and .NET are quite fragmented as they have three different clients (each in this top 13)... and these 13 different clients stood for 99% of all those connections.
Even though Python is a very popular language these days, this made me wonder if counting all connections like this a fair comparison. Maybe a Python client is written in such a way that they create a lot more connections than other clients. So instead I only counted the most popular clients on each vhost which made the statistics looks a bit different.
Popular clients by vhost
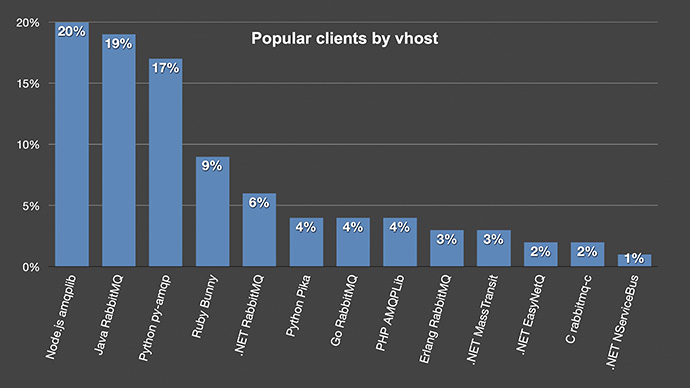
Now, the Python clients have dropped quite a bit, especially the pika clients: they went from 17% of all connections – to only being 4% on the vhost. And I believe this is a more fair way to look at it. We shouldn’t endorse being sloppy with connections.
Popular languages by vhost
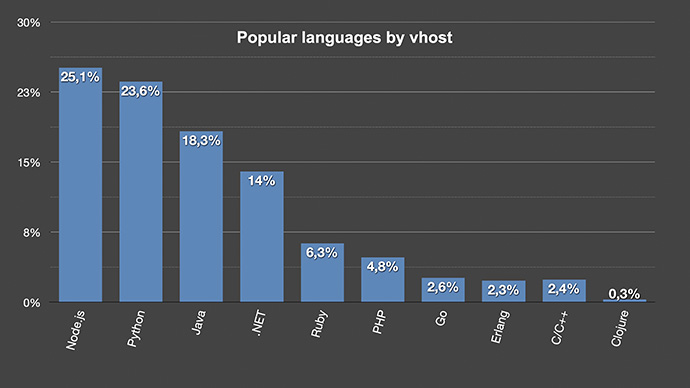
In case we group the language, we see that Node and Python as well as Java are the most popular languages.
[Applause]
