RabbitMQ Summit 2018 was a one day conference which brought light to RabbitMQ from a number of angles. Among others, Jack Vanlightly look at an alternative to the competing consumer pattern by using the Consistent Hash Exchange.
In this session we'll look at an alternative to the competing consumer pattern by using the Consistent Hash Exchange. We'll see how this exchange enables different messaging patterns such as data locality, message processing order guarantees at scale and helping to avoid large queues which can be difficult to keep synchronized in a HA configuration.
The Consistent Hash Exchange: Making RabbitMQ a better broker
We are going to be looking at the consistent hash exchange and partitioning a single queue into multiple queues. And looking at some patterns that we can get from that and avoiding some of the issues that you can get with a single queue, especially when you are trying to scale out with multiple consumers.
The original title had something about it been making RabbitMQ a better broker – but it’s kind of more like, making it a safer broker. So, we are going to look at a few different things around consistency and safety, amongst other things.
How to scale consumers
The easy way to scale out your consumers when you have a velocity of messages that a single consumer can’t handle. That is either because it takes some time to process his message or, it is just because it’s very fast. We can just scale out our consumers and have multiple consumers.
It’s really easy. You just point your consumer at the queue and RabbitMQ will do it’s best to distribute those as evenly as possible given the prefetch settings that you’ve got. And your unit of parallelism here is the consumer itself.
An alternative way it’s that you do sharding or partitioning and RabbitMQ has a few options here. I’m going to specifically be looking at the consistent hash exchange. In this situation the unit of parallelism is the queue. What we do is, we actually route messages; we partition the messages based on the hash of a routing key.
What we can do is rather than using routing keys, where we might say you bookings.new, bookings.modified, we can actually put a booking ID or a client ID etc, as your routing key.
Then you can make sure that all your messages related to a given object or entity, always go to the same queue and therefor always to the same consumer.
Now, we have lost out our total ordering of our bookings. For example, we don’t have a totally ordered set of bookings and now it’s partially ordered. But, because of the way we do routing, we actually get causal ordering. It’s a partial ordering but, we still maintain the ordering that is important to us; which is to say that we are not going to end up processing a “booking modified”, before “booking new”. Because in no doubts, you probably have the same application dealing with new and modified bookings. You don’t necessary want them in different queues, because you can then process them out of order. So this is a way of scaling out and maintaining ordering guarantees with causal ordering.
Competing consumers - What problems can arise?
Some of the problems that can arise with competing consumers is the weakening of processing ordering guarantees. Because at anytime you process a single sequence in parallel, the processing of that sequence is not going to match the stored sequence in the queue.
We also see that this (hopefully) is going to go away with the new quorum queues. But, with the current High Availability queues and with the blocking synchronization etc, large queues can be quite problematic.
Yes, you can get large queues simply by having downstream problem with availability of a downstream service. And, if you have a high velocity queue it can go quite quickly. And then, if you have multiple failures, you might be in a situation where you need to repair the replication in your broker whilst you can get to some quite difficult decisions. So, we are going to look at how we can solve that.
One consumer per queue partition pattern - what can I do with it?
We can get guaranteed processing order of dependent messages with a consistent hashing exchange. This is ensuring that we are using a routine key that does that for us. So, with a routing key that says “booking ID” or a “client ID”, we can actually have a single consumer process. One with lots of different events – all related to a client. It could be a new client or it could be change of address or whatever. You can have all kinds of mashing together of related events and you can guarantee that the order of those events is going to be processed scaled out, but also in the correct order.
With this pattern we also get data locality patterns. Let’s say I am on my company’s website which is Vueling the airline and I am making some booking. All my bookings are going to be consumed by the same consumer and therefore we can get some data locality patterns where we can do things in memory. We don’t necessarily always need to be using the cache, because we’ve got stuff in memory that we can process.
Another benefit is that we can also reduce queue sizes, which is related to the problems I was mentioning earlier about High Availability in RabbitMQ.
Parallel processing and the safety scale
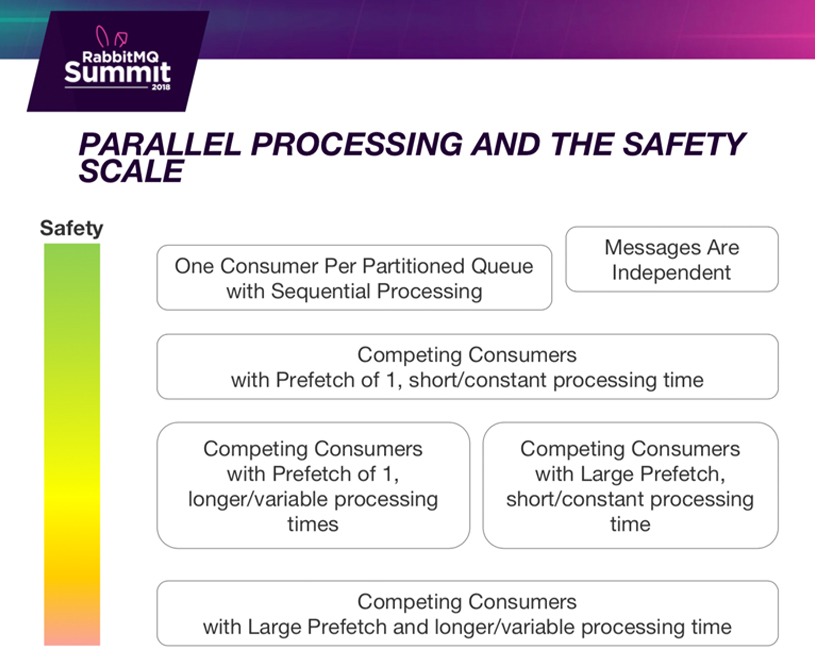
Seen above is some kind of a safety scale. From green, which is “pretty safe” to orange/red, which stands for “not necessarily safe” regarding message ordering.
The best you can have regarding message ordering is that your messages are independent. This could be your logs, if you are using RabbitMQ for your logs it is essentially that each log event is independent. When you need to order them, you’d be using your data store to do the ordering. The fact that you are processing them in different order – doesn’t matter, because you are just adding it. It’s like an append-only operation. So when messages are independent, you don’t really worry about message ordering at all.
Then we’ve got the one consumer per partitioned queue. This is what I was talking about earlier with using the consistent hashing exchange, also known as consumer groups (for people who know Kafka). And as long as each consumer is processing its queue sequentially, then we still maintain those ordering guarantees.
Now less safe, but can still be safe depending on how close your related independent messages come in the queue. When you have a prefetch of 1, you have a constant processing time. Then on short processing time in your consumers you’ll be getting very close to the order you get in the queue, more or less. It won’t be perfect. But if you’ve got related messages coming in minutes apart, with a prefetch of 1 (or even if you’ve get them seconds apart) then most likely you are going to be fine.
Where things start getting a little less safe is when you have a large prefetch. So, if you have a prefetch of 10 or 100, now you are talking about RabbitMQ delivering messages in kind of batches. The consequence will be that your total ordering is getting more and more out of order. If you have larger prefetch the larger the number of consumers and the further out of order your ordering is going to get. Also, the more your processing times varies between competing consumers, the more out of order your processing is going to get.
The worst is when you have long and variable processing times with a large prefetch. Take all of this with a grain of salt because if you do have 5 or 10 minutes between each message, it’s probably not going to matter. If you were in situations when you can have stats change to objects that can be very close together; or, if you are in a situation where you’ve had some down time and your queue is 4, and now you’re catching up. You can actually have messages that are temporarily separated by a few minutes (which are actually very close together in your queue).
Let’s look at some demonstrations, just to see how this will affect the messaging ordering.
RabbitMQ Demo 1: Loss of total ordering
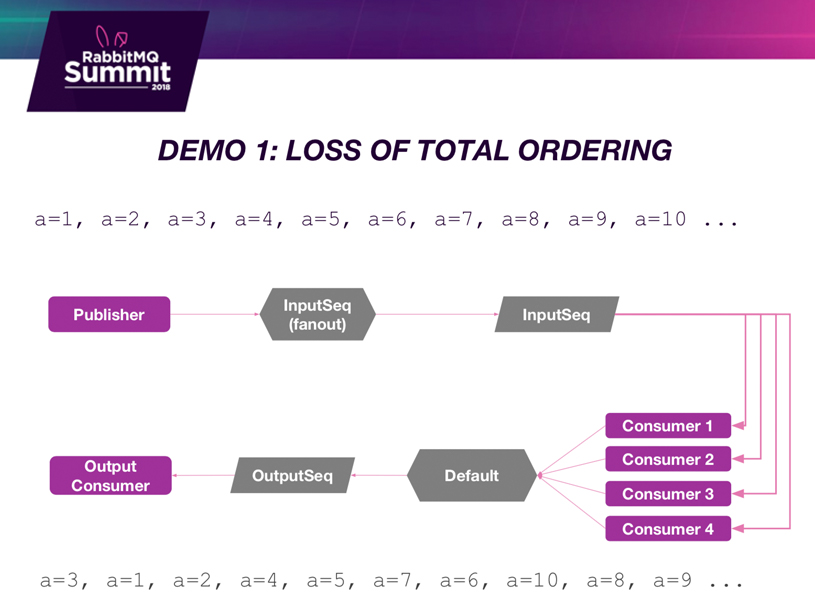
In the first demonstration I’ve got a publisher and it’s got a key A and it’s going to publish a series of state changes. So that key is basically a sequence of monotonically increasing integers and it’s going to publish that. Then we’ve got four consumers that are going to process that sequence in parallel and publish that out to this consumer, and the consumer is just going to print out what it gets back.
And we’ll see that, we’re competing consumers even with basically 0 milliseconds of time – it will be out of order.
RabbitMQ Demo 2: Multiple update sequence
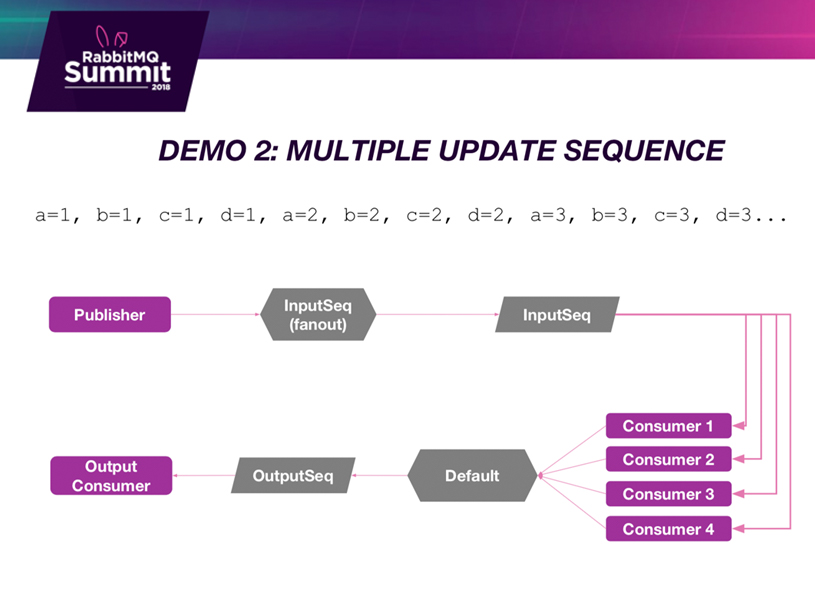
In demonstration number two we’ve got multiple keys. This will be more like something that you have in real life. Each of these letters could be a “booking ID” or a “client ID”, or whatever. Then we’ll be publishing multiple keys and we’ll see what the kind of causal ordering effect has on competing consumers. And we’ll be comparing the result to see if the order is correct for each given key.
RabbitMQ Demo 3: Multiple update sequence - with hash exchange

Finally, we’ll be doing exactly the same as in the previous demo, but we’ll be using a hashing exchange. Just to see how that affects the message ordering.
Data Locality Patterns - Deduplicating competing consumers
Other things that you can do when it comes to data locality patterns is deduplication. When you have a producer that is producing a series of messages and you get a connection failure or similar. Then you don’t know if those messages have been persisted safely. You might choose to resend, at which point some were persisted safely, and now you’ve got duplicates.
In this case, on the consumer side, you can try and go for idempotent processing. It’s not always possible though, if you are sending emails or similar. Some things aren’t idempotent and you want to deduplicate instead. Here you might go for a strategy where you are storing correlation or message ID’s and redis or PostgreSQL os similar. And you are just doing lookups. This can be inefficient and slow, and also there are no guarantees. Because two duplicates could come back at the same time and you could have two different consumers. Do the same check against redis and redis says “No, i haven’t seen that message ID”. And so, the duplicate gets through.
Deduplication - One consumer per queue partition
Whereas when you are having all your dependent messages all routed to the same consumer. Now you can actually make some bets that you can’t with competing consumers. One is, that you can actually store stuff in memory. The most sort of simple way of doing it (not necessarily the best) is to store your correlation IDs or messages ID’s in an in-memory map. A LinkedHashMap is nice because you can actually expire your messages because you probably don’t want to store every message for all time (because then you might run out of memory).
But there are other combinations of queues and maps that you can use. You might have an embedded database or, you might use a bloom filter which is great for having duplicate detection in small amount of memory.
However, the complication is that your consumer might need to be shut down or it might fail. And now, your memory data is gone. You then might want to look at snapshots in your data periodically so a consumer that comes to replace your lost consumer can recover the data. Now, obviously it’s a periodic which means you wouldn’t get all data. It’s no silver bullet.
Windowing and agretations - one consumer per queue partition
Some of other things you can do when you know a given booking ID always goes to the same consumer is, we might have some business rules. We might say, a client cannot do more than X actions of type Y within their period Z. We can store all that in memory. Then you can just do in-memory lookups and you don’t need to be making queries against the database to check if the action is valid.
RabbitMQ Demo 4: Deduplication
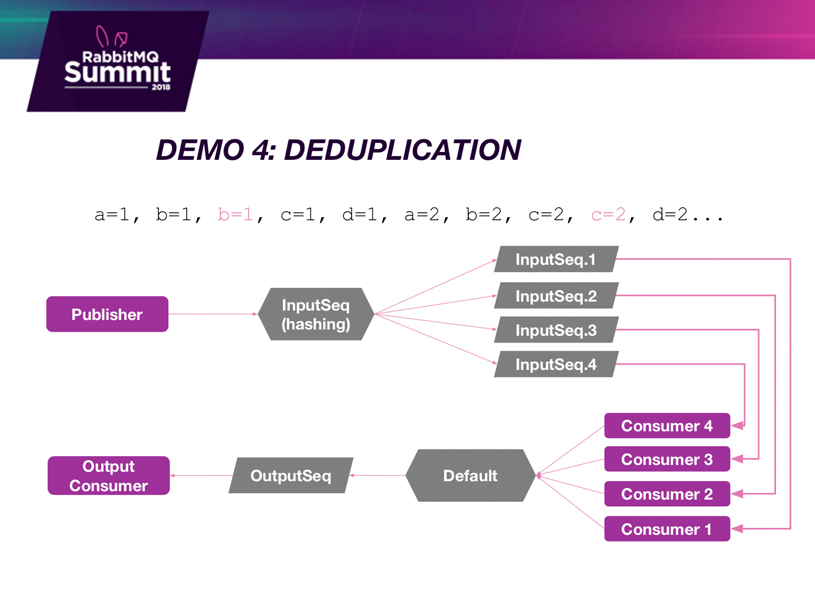
I have prepared another demonstration where we just implement deduplication and it’s only using Python. In the Python client I am using the dictionary to simply just do a lookup. And if they’ve seen the RabbitMQ message before then they just ignore it.
So, this time I can configure them to say: hey, look for duplicates!
Queue Mirroring and blocking synchronization
This is something which I was very happy to learn today. That we now have Quorum Queues because this is something that has bothered me and many others about RabbitMQ. Namely, when you have a situation where you need to synchronize an empty mirror and it is blocking, which makes your queue unavailable. Which is why they always recommend not to have large queues.
Mirrored Queues - Blocking synchronization one monolithic queue
With mirrored queues you have a leader mirror and publishers and consumers both read and write from the leader. And all the messages and the acknowledgments etc are replicated to the mirror. When we then lose a mirror and we have configured it to have exactly two replicas RabbitMQ will say: “Great! I’ll create another mirror on node 1. But it’s empty.”
Now, at this point, let’s just say we have a million or ten million messages – if we have a large queues, it is problematic. As an administrator you face the dilemma. Do I risk having no redundancy now, given that I’ve already lost a node, or do i synchronize? And if I synchronize my queue is going to be unavailable. How long it’s going to be unavailable depends on the load of the network and how much data there is.
In this situation you might hope for the best and pass. Basically just wait for the natural synchronization, as messages are consumed and added for the natural synchronization to take place.
But, if you do have large queues or, in situations where you do have a high velocity queues and you’ve had a history where maybe downstream services aren’t available and you have periods where your consumers are slow or they just can’t run. And your queues can quickly grow - then one strategy is to partition your queues.
Mirrored Queues - Blocking synchronization, multiple queues, multiple cores
It’s not just the consistent hashing exchange that does this. Now we can say, well I’ve got 10 keys – which means I’ve got 10 leaders. And this is a larger cluster as well, because if I am worried about this. Then I can just distribute the same amount of data over more service and over more queues. Now, why ever more queues?
Because each queue is linked to a core, and one of the bottlenecks in synchronization is CPU. So if you’ve got 3 or 5 or 10 gigs of data to synchronize and it’s on one core – then that could be your bottleneck. But, we can now leverage multiple cores on multiple servers. So when we lose a node and we’ve promoted a couple of mirrors to leaders, when we’ve created another couple of mirrors that are empty, we can now synchronize much faster because we’ve got smaller queues. And each one is a separate core and we can get much better parallelization of our synchronization.
But, you can now figure all of that out when it comes to QuorumQueues, which will not throw away all their data.
Hard things about using the Consistent Hash Exchange
Next up: things that are hard about the consistent hash exchange. I just received news yesterday that one of the things I heard will be hard no longer. There has been work done on consumer group functionality. One of the hard things has been: consumer group assignment.
If you have worked with other message brokers that have partitioning, you know they give you out of the box queue consumer assignment. You just set up your queue with these groups, with this topic and it will automatically assign your queues. But in RabbitMQ right now, we don’t have that.
Therefore I created a little project called Rebalanser (Github). This is just temporary because I’ve heard that Pivotal will implement consumer group functionality in the Java client. This is welcoming news.
What the Rebalanser does is that if you partitioned your queue it will help you do it dynamically - using the simple consensus algorithm.
The other hard thing about data locality is state. Now we can do things very fast in memory. But now, it’s in memory. So anytime you need to shut down a consumer or you lose a consumer, you need to think about how to get that state back. This might actually be more complicated than the problem you are trying to solve in the first place. Or, it might not. That is your decision to work out.
Changing the number of queues also changes the hash space which each queue is related to. The way I understand it is they try to limit that change – but, if you are going from 5 to 20, my Booking.1 that was going to queue 2, might now go to queue 5. Because all the hash base is different, definitely distributed. So, that is something else to take into account.
RabbitMQ Demo 5: Rebalanser
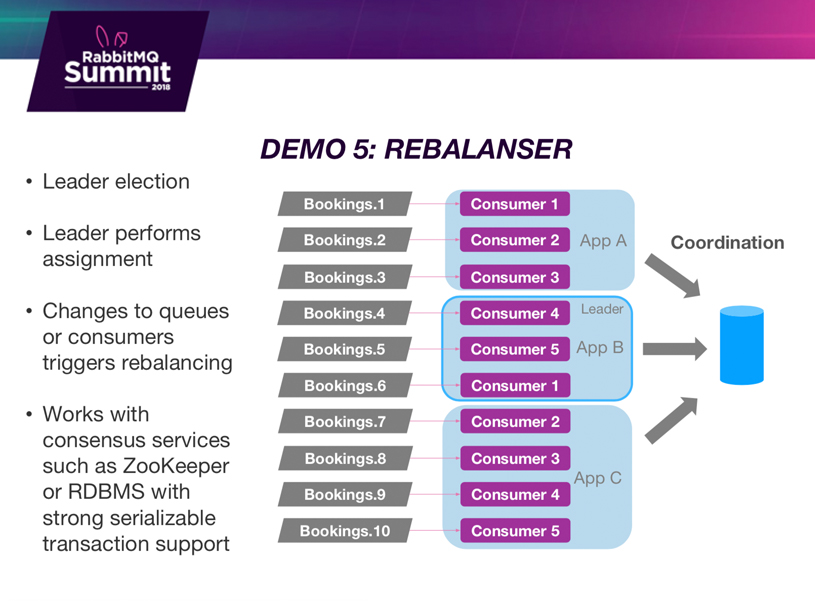
I’m going was going to do a quick demonstration of Rebalanser and this can act as a primer, I guess, on consumer groups that hopefully will be coming with the Java plan and other clients.
So basically what Rebalancer does, is that it’s a library which sits on top of the parent client. And you just say: “Hey, I am in this group” and it provides hooks on events: When you get assigned a queue and when you get unassigned to a queue, it just allows you to start your consumers up and shut them down on those events. It uses a backing store, you can use a distributed census store or any database that has serializable transactional support. What it will do is - it will create this number of consumers. It will always have one consumer per queue and it will create multiple consumers in a single application. I’ll just do a quick demo of that.
If you want to maintain your message ordering, you really need to make sure you have a single consumer per queue.
[Applause]
