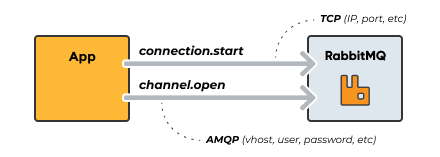
RabbitMQ was originally developed to support AMQP 0.9.1 which is the "core" protocol supported by the RabbitMQ broker. Here are the channels used to send messages over TCP connections.
What is a connection?
A connection (TCP) is a link between the client and the broker, that performs underlying networking tasks including initial authentication, IP resolution, and networking.

What is a channel?
Connections can multiplex over a single TCP connection, meaning that an application can open "lightweight connections" on a single connection. This "lightweight connection" is called a channel. Each connection can maintain a set of underlying channels.
Many applications needs to have multiple connections to the broker, and instead of having many connections an application can reuse the connection, by instead, create and delete channels. Keeping many TCP connections open at the same time is not desired, as they consume system resources. The handshake process for a connection is also quite complex and requires at least 7 TCP packets or more if TLS is used.
A channel acts as a virtual connection inside a TCP connection. A channel reuses a connection, forgoing the need to reauthorize and open a new TCP stream. Channels allow you to use resources more efficiently (more about this later in this article).
Every AMQP protocol-related operation occurs over a channel.

A connection is created by opening a physical TCP connection to the target server. The client resolves the hostname to one or more IP addresses before sending a handshake. The receiving server then authenticates the client.
To send a message or manage queues, a connection is created with the broker
before establishing a channel through a client. The channel packages the
messages and handles protocol operations. Clients send messages through
the channel’s
basic_publish
method. Queue creation and maintenance also occur here, such as AMQP commands
like
queue.create
and
exchange.create
are all sent over AMQP, on a channel.
Closing a connection closes all associated channels.
Publish a message to the RabbitMQ broker
We will look at a simple example from the Python library Pika.
- As with all clients, you establish a TCP connection.
-
After that, a logical channel is created for sending data or performing
other operations (like the creation of a queue). You provide authorization
information when instantiating a
BlockingConnectionsince the broker verifies this information on a per-connection basis. - A message is routed to the queue, over the channel.
- The connection is closed (and so the are all channels in the connection).
connection = pika.BlockingConnection(connection_parameters)
channel = connection.channel()
channel.basic_publish(exchange="my_exchange",
routing_key="my_route",
body= bytes("test_message")
)
connection.close()Configuring the number of channels
We recommend to use the operator limit for connections and
channels.
Use
channel_max
to configure the max amount of allowed channels on a
connection. This variable corresponds to
rabbit.channel_max
in the new config format. Exceeding this limit results in a fatal error.
Use
connections_max
to configure the max amount of allowed connections.
A common question we get is how many channels one should have per RabbitMQ connection, or how many channels is optimal. It’s hard to give an answer to that since it always depends on the setup. Ideally, you should establish one connection per process with a dedicated channel given to each new thread.
Setting
channel_max
to 0 means "unlimited". This could be a dangerous move, since applications
sometimes have channel leaks.
Avoiding connection and channel leaks
Two common user mistakes are channel and connection leaks, when a client opens millions of connections/channels, causing RabbitMQ to crash due to memory issues. To help catch these issues early, CloudAMQP provides alarms that can be enabled.
Often, a channel or connection leak is the result of failing to close either
when finished.
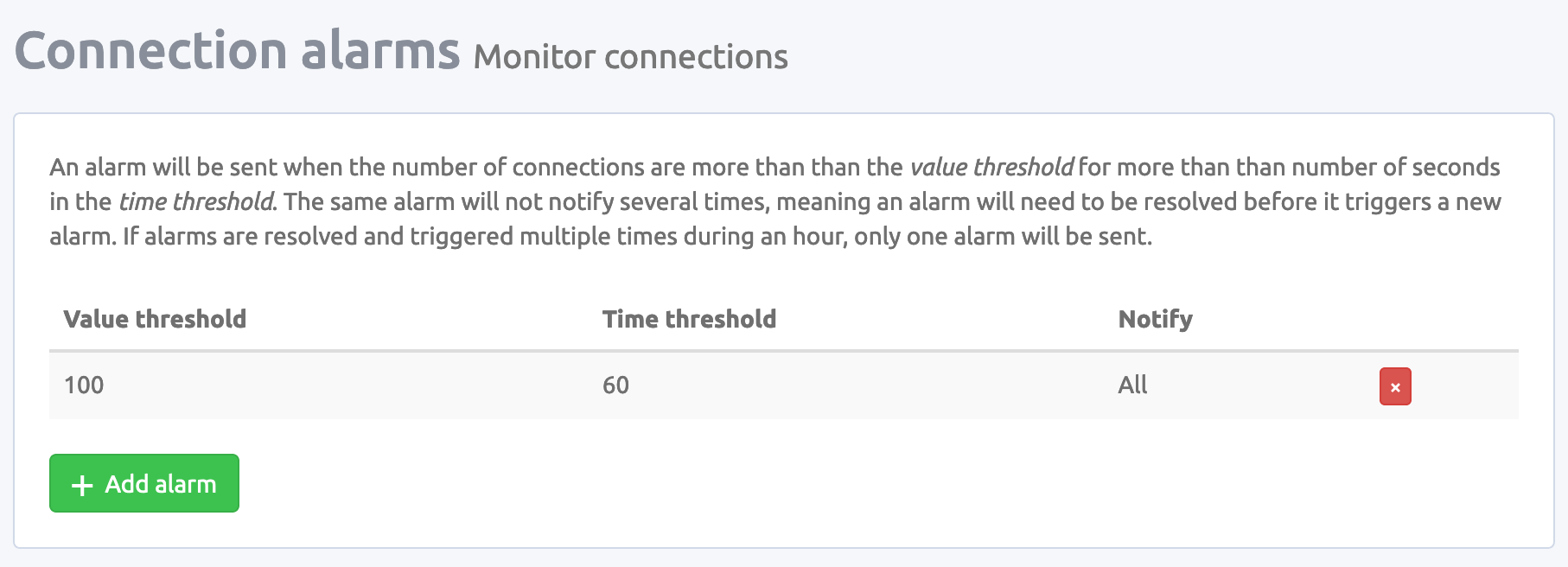
Recommendations for connections and channels
Here follow some recommendations of how to use, and not to use connections and channels.
Use long-lived connection
Each channel consumes a relatively small amount of memory on the client, compared to a connection. Too many connections can be a heavy burden on the RabbitMQ server memory usage. Try to keep long-lived connections and instead open and close channels more frequently, if required.
We recommend that each process only creates one TCP connection and uses multiple channels in that connection for different threads.
Separate the connections for publishers and consumers
Use at least one connection for publishing and one for consuming for each app/service/process.
RabbitMQ can apply back pressure on the TCP connection when the publisher is sending too many messages for the server to handle. If you consume on the same TCP connection, the server might not receive the message acknowledgments from the client, thus affecting the consumer performance. With a lower consume speed, the server will be overwhelmed.
Don’t share channels between threads
Use one channel per thread in your application, and make sure that you don’t share channels between threads as most clients don’t make channels thread-safe.
CloudAMQP allows you to scale your instances to meet demand while providing mechanisms to troubleshoot leaks. If you have any questions, you can reach out to us at support@cloudamqp.com
