By letting AI handle the cognitive load of organizing complex story worlds, authors are free to focus on the craft itself. However, as this background analysis grew more computationally heavy, TrueTale’s initial architecture needed a more robust way to scale.
We sat down with founder Andrea Cerasoni to discuss their shift toward a message-driven system. By replacing traditional request-response patterns with managed LavinMQ, TrueTale is now able to scale this "memory" without the risk of data loss.
The problem: When REST holds you back
Initially, TrueTale relied on synchronous REST calls. It’s a common starting point, but for an AI-heavy application, it’s risky. Every time a writer made an edit, the system had to process the entire narrative context.
If a service was busy or a network spike occurred, the request simply failed. For Andrea and his team, this meant "stuck" analyses, manual database resets, and the risk of losing a writer’s work.
To fix this, they moved to an asynchronous "hand-off" model. Instead of the writer service waiting for a complex analysis to complete, it now simply drops the edit into a queue, a process that takes milliseconds, and immediately confirms to the author that their work is safe. The narrative engine then picks up those messages at its own pace to update the Story Bible. If the analysis service is overloaded or an LLM provider is down, the data sits safely in the queue until the system is ready.
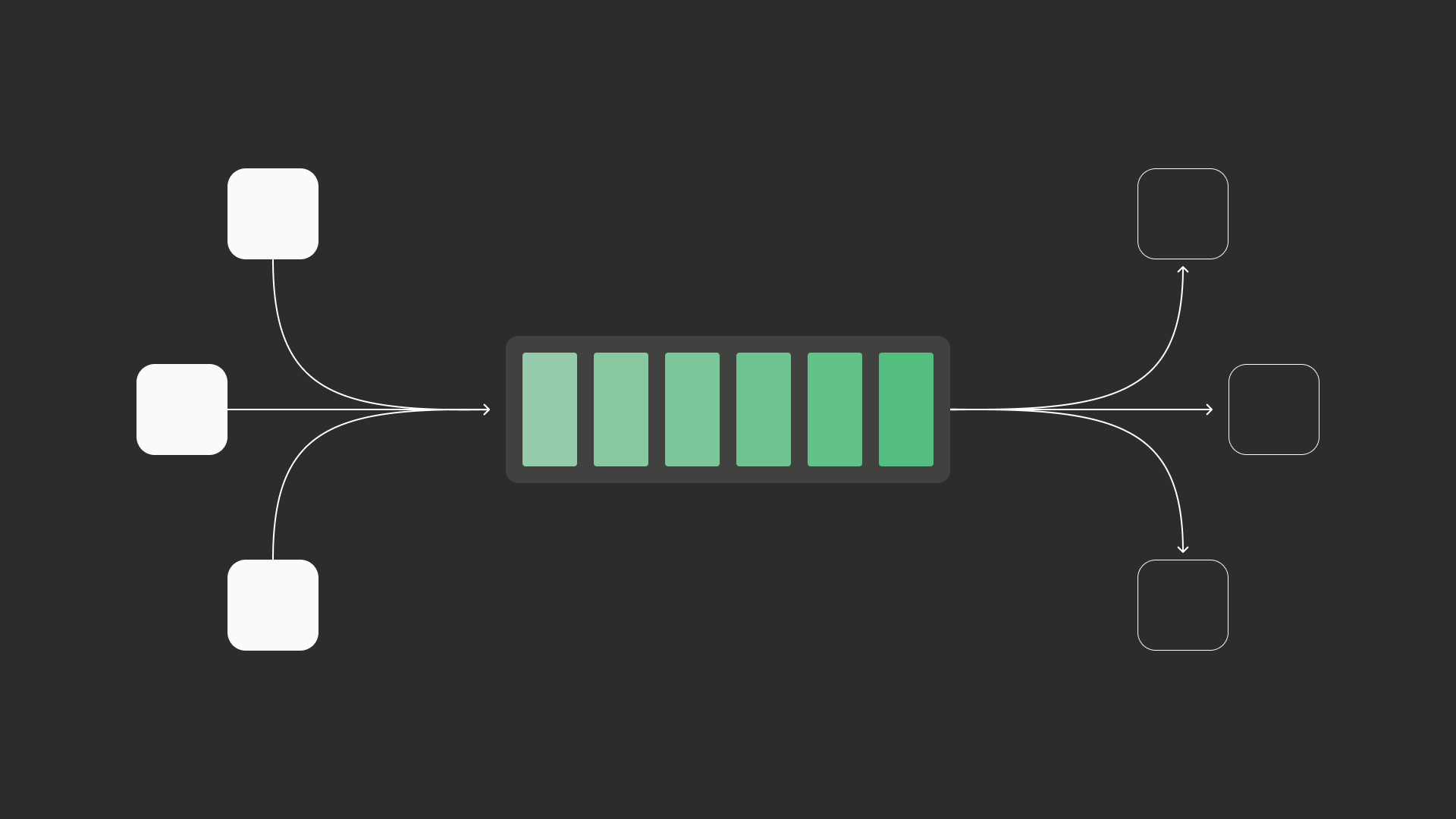
The "Zero-DevOps" choice
Andrea knew he wanted a message broker, and LavinMQ was the natural choice for high-performance, low-latency text processing.
TrueTale follows a "Zero-DevOps" approach, prioritizing feature development over infrastructure management. They considered Kafka, re-using Redis, or moving to serverless, but those options required complex setups they wanted to avoid. After a successful proof of concept confirmed LavinMQ’s compatibility with their Spring Boot environment, they moved to CloudAMQP.
"We needed a reliable way to handle messaging without the burden of managing the broker ourselves," Andrea told me. "We strongly preferred the white-glove service, simplicity, and cost predictability of CloudAMQP over traditional cloud offerings.”
The results: leaner, faster, and more affordable
The shift to a producer-consumer model on CloudAMQP not only resolved reliability issues but also changed its cost structure.
- Handle traffic spikes: By using LavinMQ to buffer traffic spikes, TrueTale no longer needs to run oversized server instances to handle peak loads. They reduced their microservice sizes by two-thirds.
- Stopping the "AI Leak": Before the move, roughly 15% of their LLM token costs were wasted on failed requests. Now, with the queue ensuring every message is delivered, that waste is gone.
- Getting time back: The team reclaimed about five hours per week previously spent on manual support and "babysitting" the infrastructure.
"It just works."
Today, TrueTale is leaner and more resilient. By moving the core of their narrative engine to a managed instance, they’ve deleted hundreds of lines of complex "retry" logic and haven't seen a single data loss incident since.
As Andrea puts it: "The infrastructure has become invisible." And honestly, as a hosting provider, that’s the best compliment we can get.

Jeff Hara
Customer Success Manager
Hi, I'm Jeff, and I'm here to help
Curious about what CloudAMQP can do in your architecture?
Reach out to us and let us help. The consultation is free, and we'll ensure you get in touch with one of our experienced architects. / Jeff
Contact us today