RabbitMQ Summit 2018 was a one day conference which brought light to RabbitMQ from a number of angles. Among others, Nathan Herald from Wunderlist gives an overview of what it’s like to live with rabbit for years.
Wunderlist made big bets on two technologies: AWS and rabbit. I will give an overview of what it’s like to live with rabbit for years, the tools and practices we built up around rabbit, and as many tips and learnings as I can. In this talk you'll see real world data, hear anecdotes from using RabbitMQ at various scales. You should feel more comfortable making a bet on RabbitMQ as a critical part of your infrastructure after my presentation.
What it's like to bet your entire startup on RabbitMQ
I’m Nathan. I go by @myobie on almost every website. I live in Berlin, moved there to work on Wunderlist years ago. I am a product designer and a developer. I worked at Wunderlist. Now I work at Microsoft because they acquired Wunderlist. They are very nice and good people. I can recommend them. Also, I like sneakers. Wunderlist is a to-do list app. This is what it looks like:
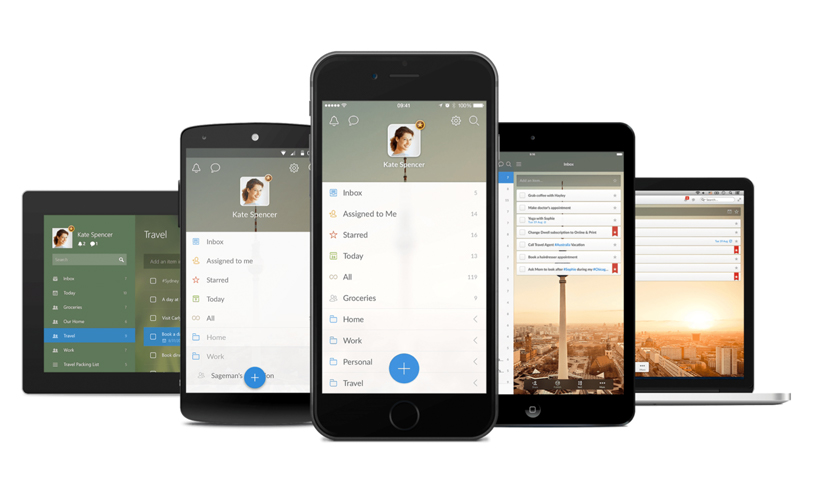
It is not that fancy. You can put tasks in it. Also it has a feature that is Real time collaboration, so when you make changes people you share lists will see them very quickly. Our goal: Take less than 5 seconds for a change to propagate to anywhere in the world. That is a pretty tough goal. Using our app on one device should feel like remote controlling for the other devices. To do that you need to have a good event bus, that is a spoiler to the story.
For some quick history. I found this screenshot somewhere. Wunderlist v1 was a single user app made in three weeks. Customers loved it. Christian was the CEO and they were working on another product. Then they saw that customers like the app more than the other products, so they decided to work on it full time. They made it with Titanium. I don’t know if you remember Titanium, but it’s one of those OG Javascripts frameworks where you can build Javascript and deploy to multiple things, this was before electron and before react-native.
Either way, the company realized Titanium wasn’t a good idea and they made Wunderlist 2, for which I could only find a screenshot where less than half of it is Wunderlist 2.
The big feature of the app is you could share a list with other people and you could collaborate on add tasks where you could see each other’s tasks. They also wrote everything to be native. They made a big effort and customers loved it again. But the app had difficulties scaling where no matter what is done, when a lot of people want to use something, you just never have enough of what they want. It wasn’t anything in particular that was a problem; kind of everything was a problem. There were also a few data synchronization bugs while adding tasks to the list while the other person wasn’t able to see it. It was hard to diagnose. I would say: Never use time stamps for anything. That is just my advice. Don’t do it! I am serious! Ok.
So, they decided they needed to rewrite everything… Well the team did. They were like they got data sync problems, scaling problems etc…”But we’ve got good reviews, so let us rewrite everything so that we have the same app, but one that we can scale and one that doesn’t have data synchronizing issues”.
I decided to join and help. I think that is a good idea. It is never a good idea to rewrite, everyone tells you that, but… When you hear it you are like, this is a great idea.
Wunderlist 3
That became Wunderlist 3 which is the current version. That is the one I worked on. I found better screenshots of it, so that was the Mac app there. The big feature now of the app is that it’s not just data sharing but that it was real time, where we thought that if we forced ourselves to make the real time which is the 5 second change – it would actually make the app reliable and make the customers trust it better. At least we think so.
We wanted reliable data sync and got rid of the time stamps and moved to monotonic clocks and things like that. It turned out that we didn’t want the server to be intelligent when the client can be the intelligent one. What we needed the server to do is to be really fast at moving stuff back and forth. Again, spoiler alert, we were going to use RabbitMQ for that.
We also wanted it to be easier for the team to build new features. The old way that it worked was a lot of coupling, it was really difficult to make changes and it was really difficult to do new things or to do experiments. That was actually something we also wanted to happen.
It turns out when you use something as RabbitMQ as an event bus, you actually get this for free because then you could do things like set up extra bindings and set up your cues and you don’t have to ask anyone. We also built a lot of AWS tooling since we are all on AWS. And we are still on AWS. They did not move it to Azure. They did have an effort to do it, but it turns out like, vendor lock in is a real thing and you cannot move. You just can’t do it.
I and the team spent 13 months rewriting the backend and most of the client applications. That is a long time to work on a project and to end up right where you started. I don’t recommend it, even though it was fun sometimes. We decided to use RabbitMQ even though we knew the event system was going to be a single point failure. We were like let us do a good single point failure, instead of just trying to remove it.
For some reason, we liked the idea that it was written in Erlang. None of us knew Erlang, none of us knew what Erlang was, but we heard about it being good and old, so we were like this is really cool. And we thought maybe it could work. We thought maybe it would work better than the things we would make. Turns out it's probably true. It doesn’t really matter since it is not a way you should evaluate a product.
We decided to use CloudAMQP. We really recommend them (like #shoutout.) Carl and his team really and honestly helped us and we could not be able to done this without them. We didn’t want to run it, I don’t know…we were really bad and everything we started to run did not work. So we were like – someone else has to do this. And it’s really like the only vendor that didn’t screw us. So, AWS screwed you, everybody screwed you, but CloudAMQP has not yet.
People always ask me to explain: why RabbitMQ?
I don’t know if I would say it is good. It’s kind of like Vim and Emacs, like those are very good editors, but I don’t tell people they should use them. You have to be a very motivated person to use those, because they are nuances and you have to learn. That is how I explain it. If you are motivated, it is very good. If you are not motivated, well I don’t know man, you might really get into something. Either way, a lot of technologies have similar learning curves. RabbitMQ causes you to shift your mindset where you are no longer sequel based, which most startups are at first. Then you rip out a little by little. So, it’s good to have that shift of mindset forced upon you. Embrace it! Do it!
We decided to do an evented architecture. A lot of people were very weary because they claim transactions in sequel is very stable. But it is not actually stable. It is only stable in the transaction. But, at the end of the day you can’t scale that.
What I do mean by evented (because I think when people say that - is meaningless). This was going to be our kind of API that we talked about internally. Like you can emit an event and you can listen for things… And that was it. That was the way we wanted everything to work on the backend. So that is what we did. It’s kind of like no Jazz event I guess, if you want to think about it that way.
I think having something simple you can talk about, something really dumb is actually really good, because then you can get an alignment and actually go solve the problem. Simple APIs can be powerful. I really look for things that are really dumb so that I can assemble them into sophisticated things. And I think this was one of them.
Also I like technology that teaches me how to be better and I think RabbitMQ has done that. It has taught me the about exchange queues. I hated that in the beginning, but it does make sense and it is a good idea.
Also, we weren’t very certain that we are going to use RabbitMQ because we didn’t quite understand it so we were very simple with how we used it at first. But again like lock-ins are real, you cannot move to something else once you started using these features, you understand it is not replaceable. We just aligned ourselves.
Anything I say it is not just me. Everybody in the company is involved in everything and every part since design is a team sport. I am not important; I am just here to talking to you. I just wanted to make sure that is clear. Everybody at Wunderlist is awesome. They are all doing different things now and some of them are working on another to-do app.
If it is something you take away from the talk, it is important to learn how to use RabbitMQ and how it works… Not even to use it, just learn it, so that you have new concepts to think about when you build stuff.
-
Do you know what an exchange is? I didn’t know that. Honestly, I kind of wish the default exchange and default queue weren’t there. They are very confusing since you read about it but some parts doesn’t works as you expect. I wish it could go away.
-
Do you know what the queue really is? We thought we understood it, turns out we didn’t and we did it wrong many, many times.
-
Do you know what a binding is? We have never even heard of that for a while because we were using the default exchange for a long time when we were first testing it. We were like this is not at all cool. But once we did the bindings we were like, okay, okay, this is cool.
-
How expensive is a binding? It turns out to be too expensive and you can learn about it the hard way, like we did.
-
How expensive is a connection? It is expensive but it is worth it, since you have to connect.
How would RabbitMQ want me to solve my problem?
Basically you need to learn how would Rabbit want me to solve my problem? Hopefully that is what you will learn. Whether you do it or not is not important as to this is actually worth learning just for your life.
So, this is what we learned (Disclaimer: I am not an expert, I might be wrong): You push to an exchange and you consume from a queue and you use a binding to translate between the two. Once we learned this concept we felt like superheroes because we knew we could do this now and we could further focus on Wunderlist and quit with the junk.
We could not have built our own versions of what RabbitMQ does, like the whole binding and the multiplying and the fan-out etc. I don’t think we would be done in 13 months if we didn’t have all of these features at our disposal.
Aside: I get angry now when I use a streaming system that doesn’t support routing keys, and when I have to use things that don’t have these features.
We have four primary exchanges because you prototype something and then it goes to production. We could have done everything with one exchange and if we’d run routing keys a little differently, nu it doesn’t matter. We did functional sharding and we actually have like tens of rabbits we don’t have just one. So, we have important RabbitMQ servers, less - important ones, we monitor some and we pay more for some. That is the way we did the whole system and that is what fits with what we are already doing with our AWS setup.
We have our primary exchanges: creates, updates, destroys and touches.
The reason why we have four exchanges is because we thought creates was going to be overwhelming and hence, we need to move it to a new box. So, we just wanted already for it to be separated and everything that would happen in the system we push it onto the correct exchange with the routing keys to the type of thing that happened. We call it destroy because it was a rails drop, but also deleted means we updated like a deleted ad, while touch is very similar to what active record calls touch, which means we wanted to increment a number and that is it. We don’t want to update anything else.
Every change in the system we call a mutation. I don’t know why we didn’t call them changes. I think that is weird. The routing key is set to the object types so it would be like task, list, subtext, comment – so you can go to task, create, list and update. There you go. Everything is in there for you to consume and it is fantastic.
Everything that happens is powered by this. Like, when you sign up and you get a welcoming email – it's because there are some consumers bound to the user create. And if you get a push notification it is because something was bound to task create or comment update.
If we want to do a cascading delete, that all happens by churning through, like a million deletes cascading to other deletes through the system. Everything happens to this. That is how everything works.
We set up a queue that binds out to all of four exchanges for all routing keys. Then we call that the mutation stream and that is everything that mutates an old system. That is really nice and you get that for free.
We had intended to archive them and then when I looked, we apparently did not. I don’t know where they have gone – but it is there. I call this the river of data because you can just syphon things out of it and do whatever you want with it. It’s very nice for when you would like to build a new feature. It is all there. Everything that happens in a system is there.
Somebody wanted to batch push notifications up so that, if I create five tasks you would only go to notifications and it will say five tasks were created. So they just made a consumer, they bound in the right queues and they just had it accumulated in memory and then it will stand on after a certain delay. They were able to do this without telling me, without telling anyone – and then show how it is working. Then we could just replace the current notification system with that one. That was really nice. I liked that.
Someone else wanted to do something crazy. They would type in the task name and then it would use Google translate – to translate it in another language. You name the list like the language you want to translate to. Basically it was insane.
They built it so it worked and they showed us in the app and we didn’t even know that anyone had done it until they demoed it. I think that is really nice. I guess some people will be terrified that that is happening; but I myself don’t want to know what all is happening. I can’t handle that, it’s like too much.
Just as a reminder. Touch is an important since it increment numbers as a way to keep track of what has changed. It feels like the sync in the protocol. We also use it to have like a parent - child relationship. So when you write a new comment, on a task, we bobble up the touches. We do that by queuing a new message each time into the correct exchange. Then we sync by going back down, looking at all the numbers that have changed and eventually we get down to wherever something might have happened.
I mentioned cascading deletes. We don’t do bulk deletes. We actually would, if there are hundred tasks under list, we queue a hundred messages under the correct exchange. We just like it that way and you just get the natural flow of information. I don’t know if you can look at your graphs. It’s fun. You can look at spikes and stuff.
Events
We have a queue called events which are slimmed –down to the mutations and all of the changes. These are the ones that go out to the apps. So, if you have the app opened you will receive these events in real time and they literary get sent over from the RabbitMQ.
Cerebro/Cerebra
We wrote an app called Cerebro. This is like the central router and it has he rules of who is parent of who whilst there is a couple that has two parents. It is super annoying but we had to do it for an optimization. Either way, Cerebro has all those rules. It also knows all the bindings, all the queues and all the exchanges because it is really important that you have something that knows that. You could accidentally end up not binding a lot of messages and stuff.
If you don’t know what Cerebro is - it is an X-man thing of how Xavier can find all the mutants. Since it knows all the rules of where things go, we thought it would be funny. We actually rewrote it and called it Cerebra because, and apparently, that is actually what happened in the comic book.
Cerebro was destroyed and they have rebuilt it as Cerebra. This one was in Closure; the first one was in Ruby. Ruby is not built for concurrency with this particular type of thing. Closure was much better for concurrency, so it just had the same rules in Closure.
Codify Exchange and Queue Creation
I mentioned that you need to codify exchange and queue creation in code somewhere. Don’t go clicking around. Never! Don’t click and do something because you will forget and you will need to do it again. It needs to be versioned in its source control. Either have a configuration – so that when RabbitMQ boots, it will apply it (there is a plug-in for that).
What is really important is that we have for multiple times lost data, like throwing it away. You don’t have to do it when you can actually not throw it away. I recommend you to please, put it in code somewhere – I recommend the default durable. I recommend it as a default when you are testing. If you get performance problems you will see it and you should want to get to where the performance problems are. You will know when that happens. Don’t wait on your customers to get to that.
So as an example of the non-durable are all the websocket messages, all the events that are slimmed down mutations. We don’t care about it because the websocket is unreliable. That is actually a way we can speed things up. Everything else is pretty much durable and we haven’t had any problems. It is fine. I don’t know, maybe you have good disks over at CloudAMQP.
Two connections per app
Another important thing is we do two connections per app – publishing and consuming and then we used channels for concurrency from there. I am pretty sure that is what you are supposed to do. If it’s not what you’re supposed to do, then at the end you have to ask a question and you can tell me that I am not supposed to do that.
We also don’t cheat!
If in the app you could run a function to do the work we don’t do that, we put it back in the queue so that it comes around. Don’t cheat! It’s very tempting for people to cheat when something is in the same code base and we actually do have a lot of code bases that are some of the problems; but don’t cheat. Just put it back.
Implicit consumption
The biggest problem people see is that this is implicit consumption. It’s like you are putting stuff in and it's being consumed somewhere else. Then you don’t know if you did it really get there. Just embrace it. Get over it. It’s good. Usually I don’t like implicit code, I agree. But coupling is worse. This is much better.
I recommend that your publishers and consumers agree on a basic schema. But they do not know what each other’s going to do.. It's important that they speak the same language but it is also important that they don’t know what is going to happen. Because something might change and in the future you might do something different.
Asynchronous
Embrace being asynchronous. I know you can do RPC and all this… Don’t do it, just wait for something to come back around. We push the waiting all the way out to the apps, or to the web or web pages. Like, let that thing wait. It can do retries much easier. But if everything else fails fast, don’t do it, just let it go.
The one thing you have to do is you got to account for time. Most probably you might need to know if something happened before something else. I myself would not rely on any queue to keep order for me. I just don’t trust anyone. Come up with a scheme, have a clock somewhere… We put a clock on everything. Every task and every list has a number to increment it when something changes. This is how we know the time has passed. I recommend you to do something.
Don’t use timestamps, use monotonic clocks
Those are really bad. You may say: but Google uses timestamps. Well, you are not Google, and if you are, stop doing that! You are making us look bad. Seriously, don’t use timestamps.
Monotonic clocks are fine. If you don’t know what they are, go to the Wikipedia page. It will explain its system, it is like incrementing a number. I like that, it just works for 90 percent of the cases. I think it is good to have a number and increment it. It should be good.
To be able to send and receive changes quickly, we tried to localize changes down, so we decided that you cannot change two things at once. We decided changes can only happen to one object (row of data) at a time. This is actually very freeing. Again it sounds crazy to lots of people at first. But we have no joins, no transactions and no foreign keys, orphans are fine and we don’t care – because that means a lot of things can happen very quickly. We don’t have to check for anything or to coordinate anything.
Basically, my philosophy is that if something is difficult, I don’t want to do it. It’s like I don’t even want to come up with a solution like, I just don’t want to do it. So, how can I not have to do it…
Atomicity
We did make the rule where each change to each individual item is atomic. That is very important since when you increment a number you would definitely want to know it is incremented. I do recommend that. We actually use PostgreSQL for that, believe it or not.
Sequel databases are very good at saying – I really want to make sure this happens all at once. We do a very special type of row locking when the numbers are incremented. It works very good. But everything else is async. No exceptions.
We weren’t going to cheat. We weren’t going to try and optimize and I think, this has been very good for us. Again it allowed us to create features without asking permissions, to make quick changes and we could move infrastructures around. It doesn’t matter since nothing ever gets affected.
One example I want to bring up again is that we don’t actually care if a parent exists. If you create something – we don’t care. We just put the parent ID in and if that ends up going to an app and it doesn’t have that parent, it’s not going to show it in UI anyways. So, we just don’t care.
Wunderlist - Behind the scenes
One of our RabbitMQ delivers 3 billion events every day to several scala applications so they can let connected clients know about changes they might be interested in. That is a Scala Akka setup and every web socket connection has Akka actor and it registers in a registry (very similar to like an elixir registry). It’s been very good.
RabbitMQ is very good at delivering the messages and Akka is very good at determining if it should then, forward it along. What is good about this is that we don’t have to pin web socket clients to specific web socket machines – they can connect to any of them, and then every Scala app receives every event in the system without a need of filtering.
We don’t actually filter or do anything like that. We literally just send the entire event stream to every scala machine and we leave it up to them to do the filtering. So far, we have been rewarded for being lazy. We know that it only scales up to a certain amount. We just haven’t gotten there yet. I think Amazon is creating better machines all the time and you know Intel is helping us.
RabbitMQ fanout
We don’t actually enque 3 billion messages. We let RabbitMQ fan things out. That is huge and it is a very big feature. We put things into RabbitMQ and depending upon how many websocket machines there are, it will then fan out into 3 billion messages. This is fantastic. This feature is worth every penny.
RabbitMQ has very much been up to the task of multiplying out from an exchange to many queues. What is good though is that we have a new websocket machine and RabbitMQ scales it out for us. We don’t have to do anything. It just sets up a queue, binds an exchange to it so it gets all the events. Then it has its own little registry that is forwarded to websocket.
Some RabbitMQ performance graphs
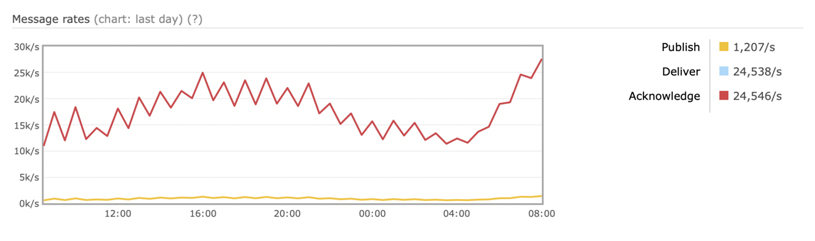
This is an example of the asymmetric relationship; so that the bottom line is what is going in and the top line is what is going out. RabbitMQ is doing all the work and we don’t do that. We didn’t write that code and we are not going to. I think that is good. I don’t know about you, but I love that. The red line can go very high. I have seen it go very high before.
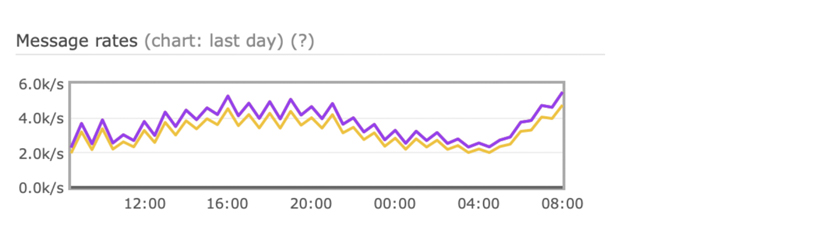
But this is an example of something that has a very symmetric relationship. Whatever we put in – it kind of goes out on the other side. This is probably like task creates, I don’t know.
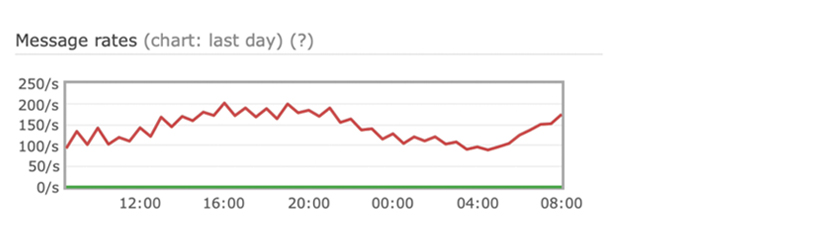
And this is a graph of something that doesn’t do much at all. We have a lot of rabbits that are less important. We have some that just kind of sit there. It is nice that it can scale from this crappy thing up to really helping us. I have some other things that I could run over quickly and then we can get to questions.
RabbitMQ Bindings are expensive
Our original idea was that every websocket would create a binding so we let RabbitMQ do the filtering. And that just creates half a million bindings. Don’t create half a million bindings. It is not a good idea. Basically, it doesn’t work. Eventually, Rabbit will say NO! We had this happen because we tried it and that is how we learned about this stuff. We would literary just try it and found out that it’s not working.
Connections are expensive more than we thought of. As far it’s like actually being taxing the machines. So for very important RabbitMQ clusters we over provisions. We make sure that we have a lot of room, just in case we need to scale out the consumers. We do not want to all of a sudden realize that RabbitMQ is slowing down because of the extra connections. We had it happened a couple of times and we solved it with dollars and get it over with.
RabbitMQ Shovel is great
There is a thing called shovel, it was mention in a few different talks. You got to learn about the shovel - it’s so good. You can be one RabbitMQ server and then in a bit you are another RabbitMQ server. That was big for us. In case you wanted to upgrade a RabbitMQ server but without any downtime, we set up a new RabbitMQ and we move the consumers and the publishers to another RabbitMQ server while shoveling everything to the new one.
Shovel basically just copies everything from one Rabbit to another. That is what it does, at least that is what we use it for. Fantastic. You can use it to move across data centers; it really can do anything. If you want to copy from one RabbitMQ server to another, use the shovel. I really recommend getting familiar with this. It is a really good way of fixing when you screw something up and to be able to fix it very quickly. We did a lot of shoveling.
High Availability (HA) without RabbitMQ
High Availability (HA) is a big topic and we do not have a good story here with RabbitMQ. We cannot recommend RabbitMQ in a HA setup. We do not run any High Availability cluster with RabbitMQ. We only do dedicated RabbitMQ servers. We did not get good performance and they just fell apart on AVS the minute we had a normal load.
I always thought that maybe we were doing it wrong or that maybe things are better now with High Availability. I don’t want to say like it is bad. We just never got it to work. I recommend you look into it since it is important topic. Basically, you just need to answer that question: What to do when RabbitMQ goes down?
We just answered it by coming up with a data loss back up plan. We have a way to look at the data base and infer most of what should have happened. This is how we can figure out what should have been in RabbitMQ and then we’ll just go and try to put it back. We’ve only had to do that twice and we call it the re-player and it worked well enough so that we can feel like we recovered from the data loss problem. So, we considered this as a success. This is an option. You could do this because we did. I recommend looking into all options since it might be like a lot of people say that maybe you actually do not need durable messages. Maybe with this re-player thing we don’t need to have a durable messages, maybe we could turn it off and have better performance and pay less money. I don’t know. It's worth looking into that stuff.
Create tools to stress test
As an aside: create tools to stress test to know if it’s going to work for you if you do not have a way to push it to the limit. I do not know a way to push it and so we made a tool.
Duncan Davidson, who worked with us, created a Scala program where he literary built out Wunderlist the app. It would instantiate hundreds of thousands of customers per machine and we would launch a bunch of EC2 instances ahead of these customers and they would actually collaborate with each other. And everything fell apart. We always had our HA problems but this was literally the worst days ever. When we actually launched our product it made nothing. We were like, why are the graphs not spiking? Then we realized we were way to aggressive with our testing. That is a really good idea. You should do it. Shout out to Duncan , he is the best and he did all that stuff for us. You have got to write something that really breaks everything so you will know where it will break.
Functional Sharding
We do functional sharding and we have a lot of dedicated RabbitMQ clusters and it worked very well for us. I recommend it if you don’t know what to do because it is a fine place to start. But definitely as a said, do your own research. This is how we approach app development. Anything that the customer doesn’t touch we want to crash immediately, anything the clients touches never crash. That’s how I like it to work. And one way to do this is to throw away messages you don’t understand.
This allows us to iterate our message schemas and make breaking changes without actually crashing apps. Log it ofcourse. We did have a bug in one of the apps in the code that discards messages that it doesn’t understand and it caused it to crash. You need to verify that the code works. Because that was embarrassing, but we fixed it.
The bunny gem was problematic for us
So our company was a ruby shop at first. But we had a lot of languages and Bunny was problematic, so we actually made our own gem called Watership to wrap and try to control Bunny. I went back to look at the commit history and it is back and forth rescues and timeouts. It looks to me as we never had it solved.
We had times when we had boxes with messages waiting in queue buffer and not doing anything. We think of it as an internal thread whilst bunny had a crash. We fixed the problem by restarting of the machines periodically.
We never keep any machine longer than a couple of days. It’s sad that this is our solution. I think that Java library didn’t have any problems for us, so all of our Scala apps and closure apps never have a problem.
Backlogs are bad
Another thing that surprised us is backlogs which are way worse than you think. They are not working fast enough. I cannot prove it but we think that a large backlog is slower to provide messages to consumers than one that is emptier.
It actually becomes slower when it gets stuff to do, which is a very anxiety inducing process. At one occasion we had to flush and run the re-player because we felt like based on what we were seeing.. We thought we never was going to make it to actually work again, because stuff was coming in and it was building up. Then it kind of slowed down and again, maybe we didn’t know what we were doing but. I don’t know since it hasn’t happened recently.
We are on pretty big machines now and I think we paid our way out of it. If this is a thing, can you let me know? If this is actually the way it works. Or you think that I am crazy, that is fine too.
I recommend you don’t host your own Rabbit unless you are literally a RabbitMQ service provider. Mainly because you are then spending time working on your product and using RabbitMQ - at the same time. If you are interested in how RabbitMQ works, do whatever you want and don’t listen to me. But, if I am building a product I look for things I don’t have to do myself. And this again is something CloudAMQP helped us with.
RabbitMQ has been running and running for years
After the acquisition for 2 to 3 years Wunderlist has been in maintenance mode and we were asked by Microsoft about what do we want to do.
Overwhelmingly, people just wanted to start over and do a new app. So, that is what they did since it was not turned off and it has been running on maintenance mode. As far as I know, we didn’t get alerted and nothing goes wrong. The thing kind of, just runs. I want to tell you that just because it’s possible. A lot of people doubt it is possible to build an app that runs.
I think RabbitMQ is a big part of why. Because we trusted it and we thought: RabbitMQ is probably not gonna make us fail. We had confidence in that and it allowed us to focus our anxiety elsewhere and make the things that we are good at.
RabbitMQ has worked well for years. I think it has been running for years. We don’t worry about it. It runs. It’s the best part of our architecture. I really appreciate that it keeps working. Actually I think, earlier today we mentioned that there might be breaking changes in the future. I really appreciate that there aren’t very aggressive changes. I like it when things work and I can do my job.
This was the question I was trying to answer:
Should you bet on RabbitMQ?
I would say yes.
[Applause]
