Some articles on the web make Apache Kafka shine in front of RabbitMQ, and others do the opposite. A lot of us could plead guilty to listening to the hype and running with the crowd. I feel that it's important to know that the decision of whether to go with RabbitMQ or Apache Kafka is dependent on the requirements of your project, and a true comparison can only be made if you have used them both with the correct setup in a fitting scenario.
84codes and I have been in the industry for a long time providing hosted solutions for both RabbitMQ through the service CloudAMQP, and Apache Kafka through the service CloudKarafka (deprecated jan 27, 2025). Since I have seen so many use cases and different application setups by both CloudAMQP and CloudKarafka users, I feel like I can authoritatively answer use case questions, based on my experience, on both RabbitMQ and Apache Kafka.
In this article, my mission is to share insights based on the many developer-to-developer chats I have had over the years and to try to convey their thoughts about why they were choosing a specific message broker service over another.
The terminology used in this article includes:
A message queue is a queue in RabbitMQ, and this “queue” in Kafka is referred to as a log, but to simplify the information in the article, I will refer to queues instead of switching to ‘log’ all the time.
A message in Kafka is often called a record, but again, I will refer to messages in order to simplify the information here.
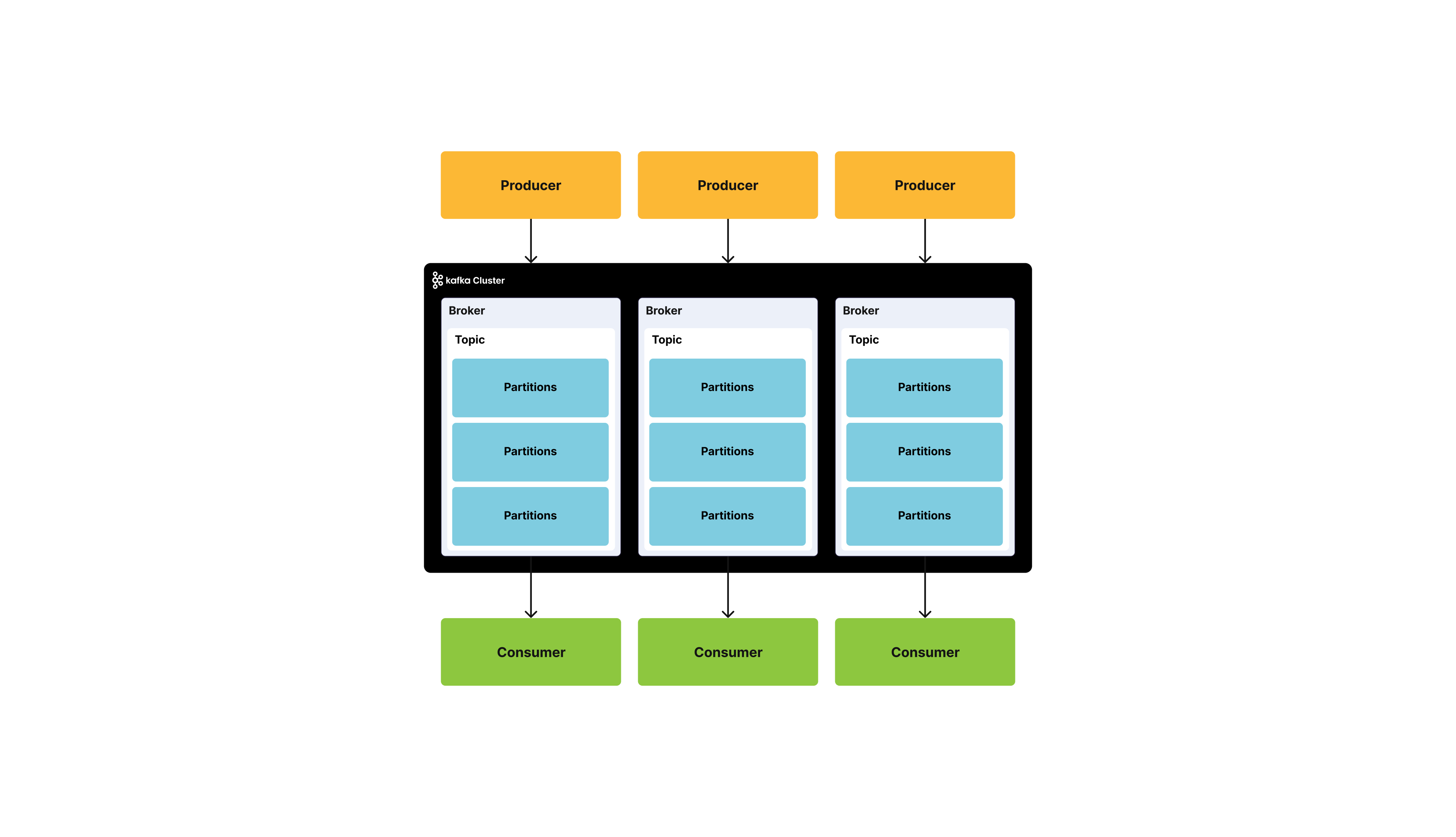
When I write about a topic in Kafka, you can think of it as a categorization inside a message queue. Kafka topics are divided into partitions which contain records in an unchangeable sequence.
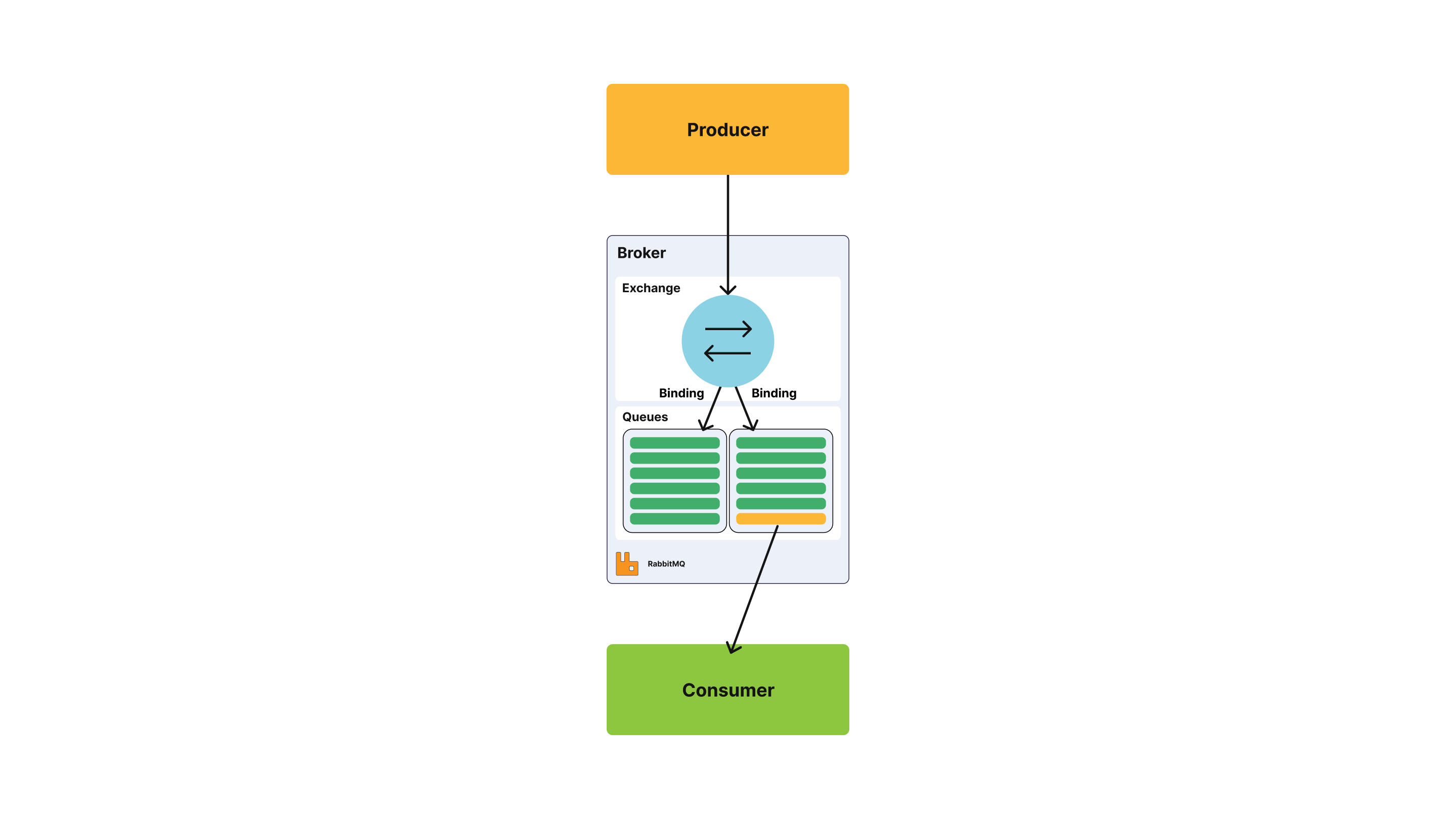
Both systems pass messages between producers and consumers through queues or topics. A message can include any kind of information. It could, for example, have information about an event that has happened on a website or it could be a simple text message that triggers an event on another application.
This kind of system is ideal for connecting different components, building microservices, real-time streaming of data or when passing work to remote workers.
Both RabbitMQ and Apache Kafka play roles in significant roles in large companies worldwide, proving the need for sophisticated and reliable messaging and streaming solutions. According to Confluent, more than one-third of fortune 500 companies utilize Apache Kafka. Various big industries also rely on RabbitMQ, like Zalando, Adidas, WeWork, Wunderlist and Bloomberg.
The big question; when to use Kafka, and when to use RabbitMQ?
A while ago I wrote an answer on Stackoverflow to answer the question, “Is there any reason to use RabbitMQ over Kafka?”. The answer is just a few lines, but it has proven to be an answer many people have found helpful.
I will try to break down the answer into sub answers and try to explain each part. First of all, I wrote - “RabbitMQ is a solid, mature, general-purpose message broker that supports several protocols such as AMQP, MQTT, STOMP, and more. RabbitMQ can handle high throughput. A common use case for it is to handle background jobs or to act as a message broker between microservices. Kafka is a message bus optimized for high-ingress data streams and replay. Kafka can be seen as a durable message broker where applications can process and re-process streamed data on disk."
Regarding the term “mature”; RabbitMQ has simply been on the market for a longer time then Kafka (2007 vs 2011, respectively). Both RabbitMQ and Kafka are “mature”, which means they both are considered to be reliable and scalable messaging systems.
I’d like to mention that I wrote that Stackoverflow answer years ago and RabbitMQ has changed a lot since then. It has made significant strides towards becoming a message streaming platform with the introduction of Stream Queues to v3.9.
Consequently, this has extended its reach beyond message queueing to use cases that had predominantly been covered by Kafka.
Before we proceed, let’s take a quick detour and learn a bit about RabbitMQ streams as you will see it a lot in the subsequent sections.
Introducing RabbitMQ Streams
We had earlier mention how messages flow from a producer to a queue and then to a consumer. RabbitMQ as a broker stands out with its variety of Queue Types, each tailored for specific messaging requirements. The traditional queue types in RabbitMQ since its creation had lacked non-destructive consumer semantics - messages are deleted from a queue once consumed and acknowledged.
This inherent nature of queues in RabbitMQ made them unsuitable for scenarios requiring long term data persistence or replay of messages. But all that changed with RabbitMQ v3.9 …
Stream Queues were introduced in RabbitMQ v3.9. They are persistent and replicated, and like traditional queues, they buffer messages from producers for consumers to read. However, Streams differ from traditional queues in two ways:
- How producers write messages to them
- And how consumers read messages from them
Under the hood, Streams model an append-only log that's immutable. In this context, this means messages written to a Stream can't be erased, they can only be read. To read messages from a Stream in RabbitMQ, one or more consumers subscribe to it and read the same message as many times as they want.
This functionality mirrors the behavior of Kafka, making RabbitMQ's stream queues an attractive option for users seeking Kafka-like features in a RabbitMQ environment. You can learn more about this new queue type in our RabbitMQ Streams blog series.
Now, let’s cycle back to the main conversation: How is RabbitMQ(with Streams) different from Kafka?
Message handling (message replay)
Even though traditional RabbitMQ queues(Classic and Quorum), only store messages until a receiving application connects and receives them, RabbitMQ Streams has changed this drastically.
As far as message replay goes, both RabbitMQ and Apache Kafka handle this in the same way. With both Kafka and RabbitMQ Streams, the data sent is stored until a specified retention period has passed, either a period of time or a size limit. The message stays in the queue until the retention period/size limit is exceeded, meaning the message is not removed once it’s consumed. Instead, it can be replayed or consumed multiple times, which is a setting that can be adjusted.
If you are using replay in both RabbitMQ and Apache Kafka, ensure that you are using it in the correct way and for the correct reason. Replaying an event multiple times that should just happen a single time; e.g. if you happen to save a customer order multiple times, is not ideal in most usage scenarios. Where a replay does come in handy is when you have a bug in the consumer that requires deploying a newer version, and you need to re-processing some or all of the messages.
Protocol
I also mentioned that “RabbitMQ supports several standardized protocols such as AMQP, MQTT, STOMP, etc.”, where it natively implements AMQP 0.9.1. Native support for AMQP 1.0 is coming in RabbitMQ v4.0. In fact, RabbitMQ currently supports AMQP 1.0 via a plugin, but not natively.
Kafka uses a custom protocol, on top of TCP/IP for communication between applications and the cluster. Kafka can’t simply be removed and replaced, since its the only software implementing this protocol.
The ability of RabbitMQ to support different protocols means that it can be used in many different scenarios.
Routing
The next part of the answer is about routing, I wrote: “Kafka has a very simple routing approach. RabbitMQ has better options if you need to route your messages in complex ways to your consumers.”
Chief among RabbitMQ’s benefits is the ability to flexibly route messages. Direct or regular expression-based routing allows messages to reach specific queues without additional code. RabbitMQ has four different routing options: direct, topic, fanout, and header exchanges. Direct exchanges route messages to all queues with an exact match for something called a routing key. The fanout exchange can broadcast a message to every queue that is bound to the exchange. The topics method is similar to direct as it uses a routing key but allows for wildcard matching along with exact matching. Check out our blog post for more information about the different exchange types.
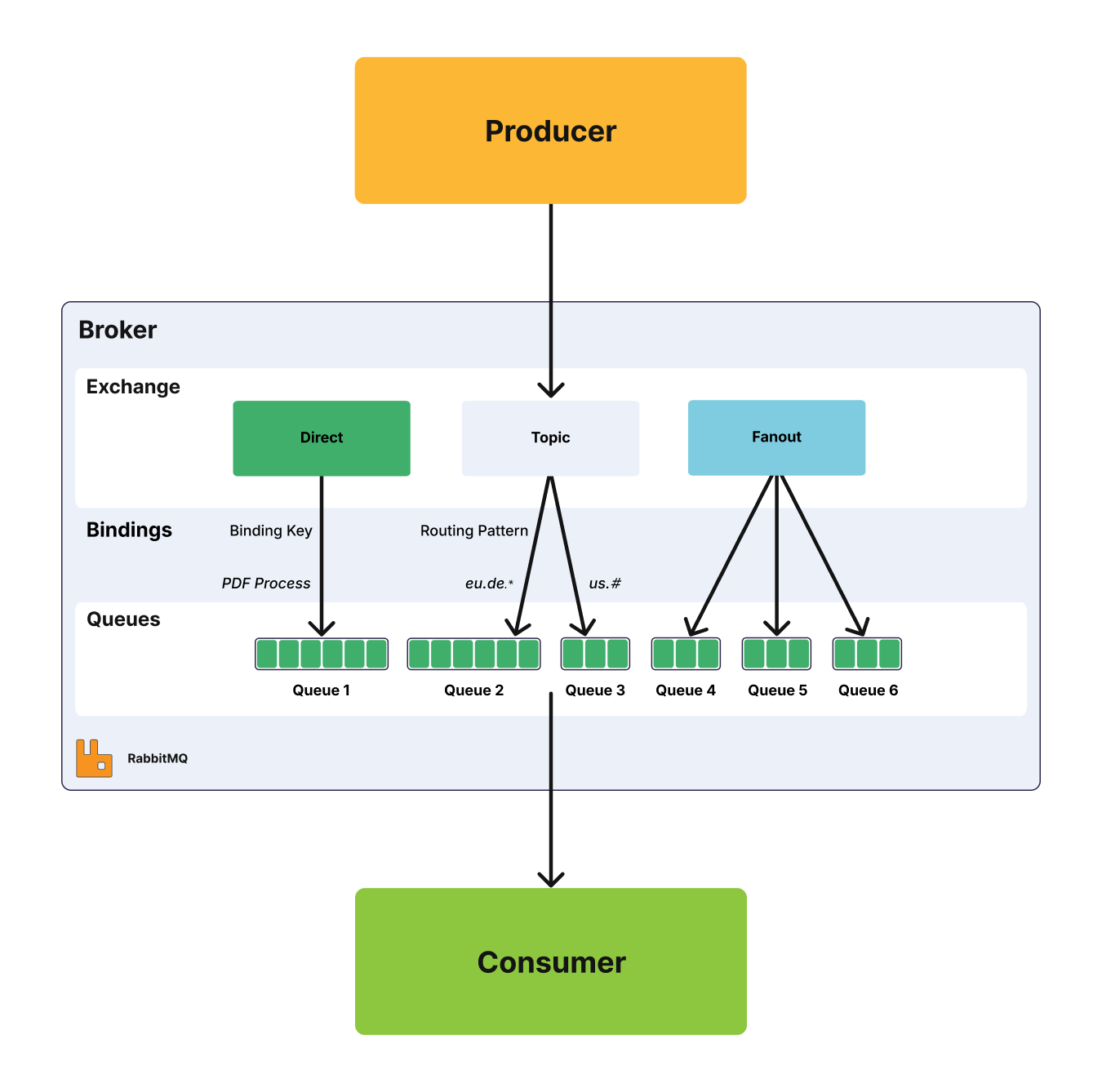
Kafka does not support routing; Kafka topics are divided into partitions which contain messages in an unchangeable sequence. You can make use of consumer groups and persistent topics as a substitute for the routing in RabbitMQ, where you send all messages to one topic, but let your consumer groups subscribe from different offsets.
An offset is a unique ID given to each message that shows the order of the message in the list of messages (log).
You can create dynamic routing yourself with help of Kafka streams, where you dynamically route events to topics, but it’s not a default feature.
Message Priority
RabbitMQ supports something called priority queues, meaning that a queue can be set to have a range of priorities. The priority of each message can be set when it is published. Depending on the priority of the message it is placed in the appropriate priority queue. So, when could priority queues be used? Here follow a simple example: We are running database backups every day. Thousands of backup events are added to RabbitMQ without order. A customer can also trigger a backup on demand, and if that happens, a new backup event is added to the queue, but with a higher priority.
A message cannot be sent with a priority level or delivered in priority order in Apache Kafka. All messages in Kafka are stored and delivered in the order they are received, regardless of how busy the consumer side is.
Acknowledgment (Commit or Confirm)
“Acknowledgment”, is the signal passed between communicating processes to signify receipt of the message sent or handled.
Both Kafka and RabbitMQ have support for producer acknowledgments (publisher confirms in RabbitMQ) to make sure published messages have safely reached the broker.
When a node delivers a message to a consumer, it has to decide whether the message should be considered handled (or at least received) by the consumer. The client can either ack the message when it receives it, or when the client has completely processed the message.
RabbitMQ can consider a message delivered once it’s sent out, or wait for the consumer to manually acknowledge when it has been received.
Kafka maintains an offset for each message in a partition. The committed position is the last offset that has been saved. Should the process fail and restart, is this the offset that it will recover to. A consumer in Kafka can either automatically commit offsets periodically, or it can choose to control this committed position manually.
How Kafka keeps track of what's been consumed and what has not differs in different versions of Apache Kafka. In earlier versions, the consumer kept track of the offset.
A RabbitMQ client can also nack (negative acknowledgement) a message when it fails to handle the message. The message will be returned to the queue it came from as if it were a new message; this is useful in case of a temporary failure on the consumer side.
How to work with the queues?
RabbitMQ's traditional queues are fastest when they're empty.
However, both RabbitMQ Streams and Kafka are designed for holding and distributing large volumes of messages.
Furthermore, Classic queues in RabbitMQ could operate in "lazy mode" . Lazy queues are queues where the messages are automatically stored to disk, thereby minimizing the RAM usage, but extending the throughput time. Note that in RabbitMQ < v3.12 the lazy mode has to be enabled but it is the default behavior of classic queues in versions >= 3.12.
In our experience, lazy queues create a more stable cluster with better predictive performance. If you are sending a lot of messages at once (e.g. processing batch jobs), or if you think that your consumers will not consistently keep up with the speed of the publishers, we recommend that you enable lazy queues.
Scaling
Scaling means the process of increasing or decreasing the capacity of the system. RabbitMQ and Kafka can scale in different ways, you can adjust the number of consumers, the power of the broker or add more nodes into the system.
Consumer Scaling
If you publish quicker then you can consume in RabbitMQ, your queue will start to grow and might end up with millions of messages, finally causing RabbitMQ to run out of memory. In this case, you can scale the number of consumers that are handling (consuming) your messages. Each queue in RabbitMQ can have many consumers, and these consumers can all “compete” to consume messages from the queue. The message processing is spread across all active consumers, so scaling up and down in RabbitMQ can be done by simply adding and removing consumers.
In Kafka, the way to distribute consumers is by using topic partitions, where each consumer in a group is dedicated to one or more partitions. You can use the partition mechanism to send each partition different set of messages by business key, for example, by user id, location, etc.
Scaling broker
In the answer at stackoverflow I wrote; “Kafka is built from the ground up with horizontal scaling (adding more machines) in mind, while RabbitMQ is mostly designed for vertical scaling (adding more power)”. This part of the answer is giving information about the machines running Kafka or RabbitMQ.
Horizontal scaling does not always give you a better performance in RabbitMQ. The best performance levels are achieved with vertical scaling (adding more power). Horizontal scaling is possible in RabbitMQ, but that means that you must set up clustering between your nodes, which will probably slow down your setup.
In Kafka, you can scale by adding more nodes to the cluster or by adding more partitions to topics. This is sometimes easier than to add CPU or memory into an existing machine like you have to do in RabbitMQ.
Many people and blogs, including Confluent, are talking about how great Kafka is at scaling. And sure, Kafka can scale further than RabbitMQ since there will always be a limit on how beefy the machines are that you can buy. However, in this case, we need to remember the reason why we are using a broker. You probably have a message volume that both Kafka and RabbitMQ can support without any problems at all, and most of us don't deal with a scale where RabbitMQ runs out of space.
Log compaction
A feature that is worth mentioning in Apache Kafka, that does not exist in RabbitMQ is the log compaction strategy. Log compaction ensures that Kafka always retains the last known value for each message key within the queue for a single topic partition. Kafka simply keeps the latest version of a message and delete the older versions with the same key.
Log compaction can be seen as a way of using Kafka as a database. You set the retention period to “forever” or enable log compaction on a topic, and voila, the data is stored forever.
An example of where we use log compaction is when we are showing the latest status of one cluster among thousands of clusters running. Instead of storing whether a cluster is responding or not all the time, we store the final status. The latest information is available immediately, such as how many messages are currently in the queue. Compacted logs are helpful when you need to restore the system after crashes or failures.
Monitoring
RabbitMQ has a user-friendly interface that lets you monitor and handle your RabbitMQ server from a web browser. Among other things, queues, connections, channels, exchanges, users and user permissions can be handled (created, deleted, and listed) in the browser, and you can monitor message rates and send/receive messages manually.
For Kafka, we have a number of open-source tools for monitoring, and also some commercial ones, offering administration and monitoring functionalities. Information about different monitoring tools for Kafka
PUSH or PULL
Messages are pushed from RabbitMQ to the consumer. It’s important to configure a prefetch limit in order to prevent overwhelming the consumer (if messages arrive at the queue faster than the consumers can process them). Consumers can also pull messages from RabbitMQ, but it’s not recommended. Kafka, on the other hand, uses a pull model, as described earlier, where consumers request batches of messages from a given offset.
License
RabbitMQ was originally created by Rabbit Technologies Ltd. The project became a part of Broadcom in 2023. The source code for RabbitMQ is released under the Mozilla Public License. The license has never changed (as of Sep. 2024).
Kafka was originally created at LinkedIn. It was given open-source status and passed to the Apache Foundation in 2011. Apache Kafka is covered by the Apache 2.0 license. Some of the components often used in combination with Kafka are covered by another license called Confluent Community License, e.g. Rest Proxy, Schema Registry, and KSL. This license still allows people to freely download, modify, and redistribute the code (very much like Apache 2.0 does), but it does not allow anyone to provide the software as a SaaS offering.
Both licenses are free and open-source software licenses. If Kafka changes the license again to something even stricter, this is where RabbitMQ has the advantage as it can easily be replaced by another AMQP broker while Kafka cannot.
Complexity
Personally, I thought it was easier to get started with RabbitMQ and found it easy to work with. And as a customer of ours said;
"We didn't spend any time learning RabbitMQ and it worked for years. It definitely reduced tons of operational cost during DoorDash's hyper-growth." Zhaobang Liu, Doordash
In my opinion, the architecture in Kafka brings more complexity, as it does include more concepts such as topics/partitions/message offsets, etc. from the very beginning. You have to be familiar with consumer groups and how to handle offsets.
As Kafka(now deprecated) and RabbitMQ operators, we feel that it's a bit more complicated to handle failures in Kafka. The process to recover or fix something is usually more time consuming and bit more messy.
The Kafka Ecosystem
Kafka is not just a broker, it’s a streaming platform, and there are many tools available that are easy to integrate with Kafka outside the main distribution. The Kafka ecosystem consists of Kafka Core, Kafka Streams, Kafka Connect, Kafka REST Proxy, and the Schema Registry. Please note that most of the additional tools of the Kafka ecosystem come from Confluent and are not part of Apache.
The good thing with all these tools is that you can configure a huge system before you need to write a single line of code.
Kafka Connect lets you integrate other systems with Kafka. You can add a data source that allows you to consume data from that source and store it in Kafka, or the other way around, and have all data in a topic sent to another system for processing or storage. There are many possibilities with using Kafka Connect, and it's easy to get started since there are already a lot of connectors available.
The Kafka REST Proxy gives you the opportunity to receive metadata from a cluster and produce and consume messages over a simple REST API. This feature can easily be enabled from the Control Panel for your cluster.
Common use cases - RabbitMQ vs Apache Kafka
Up till here, there has been a lot of information about what one system can or can’t do. Here follows four main use cases describing how I and many of our customers have been thinking about and making a decision on which system to use. Of course, we have also seen situations where a customer has built a system where one system should have been used instead of the other one.
Use cases for RabbitMQ
In general, if you want a simple/traditional pub-sub message broker, the obvious choice is RabbitMQ, as it will most probably scale more than you will ever need it to scale. I would have chosen RabbitMQ if my requirements were to deal with system communication through channels/queues with adding streaming as an option and I would also consider it as the more beginner friendly option.
But even more interestingly with Streams support you can also now use RabbitMQ in high throughput, reading(re-reading) message streaming scenarios.
Use cases for Apache Kafka
In general, if you want a framework purely designed for storing, reading (re-reading), and analyzing streaming data, use Apache Kafka. It’s ideal for systems that are audited or those that need to store messages permanently. Also, consider navigating through the Apache Kafka Ecosystem if you already have your system requirements sorted out.
Now, let's look at different scenarios requiring middleware and see where Kafka or RabbitMQ is more ideal.
Long-running tasks
Ideal for: RabbitMQ
Message queues enable asynchronous processing, meaning that they allow you to put a message in a queue without processing it immediately.
An example can be found in our RabbitMQ beginner guide, which follows a classic scenario where a web application allows users to upload information to a web site. The site will handle this information, generate a PDF, and email it back to the user. Completing the tasks in this example case takes several seconds, which is one of the reasons why a message queue will be used.
Many of our customers let RabbitMQ queues serve as event buses allowing web servers to respond quickly to requests instead of being forced to perform computationally intensive tasks on the spot.
Take Softonic as an example, they use RabbitMQ in an event-based microservices architecture that supports 100 million users a month.
Middleman in a Microservice architectures
Ideal for: RabbitMQ
Many customers use RabbitMQ for microservice architecture, which communicates between applications and avoids bottlenecks in passing messages.
You can for example read how Parkster (a digital parking service) are breaking down a system into multiple microservices by using RabbitMQ.
MapQuest is a large direction service supporting 23.1 million unique mobile users every month. Map updates are published to personal devices and software located in organizations and corporations. Here RabbitMQ topics spread over an appropriate number of queues. Tens of millions of users receive accurate enterprise-grade map information through the framework.
Data Analysis: Tracking, Ingestion, Logging, Security
Ideal for: Apache Kafka & possible through RabbitMQ Streams
In all these cases, large amounts of data need to be collected, stored, and handled. Companies that need to gain insights into data, provide search features, auditing or analysis of tons of data justify the use of Kafka.
According to the creators of Apache Kafka, the original use case for Kafka was to track website activity including page views, searches, uploads or other actions users may take. This kind of activity tracking often requires a very high volume of throughput, since messages are generated for each action and for each user. Many of these activities - in fact, all of the system activities - can be stored in Kafka and handled as needed.
Producers of data only need to send their data to a single place while a host of backend services can consume the data as required. Major analytics, search and storage systems have integrations with Kafka.
Kafka can be used to stream large amounts of information to storage systems, and these days hard drive space is not a large expense.
Real-time processing
Ideal for: Apache Kafka & possible through RabbitMQ Streams
Kafka acts as a high-throughput distributed system; source services push streams of data into the target services that pull them in real-time.
Kafka could be used in systems handling many producers in real-time with a small number of consumers; i.e. financial IT systems monitoring stock data.
Streaming services from Spotify to the Rabobank publish information in real-time over Kafka. The ability to handle high-throughput in real-time empowers applications, making these applications more powerful than ever before.
CloudAMQP uses RabbitMQ in the automated process of server setups, but we have used Kafka when publishing logs and metrics.
| RabbitMQ | Apache Kafka | |
|---|---|---|
| What it is? | RabbitMQ is a solid, mature, general purpose message broker | Apache Kafka is a message bus optimized for high-ingress data streams and replay |
| Primary use | Message queue for communication and integration within, and between applications. For long-running tasks, or when you need to run reliable background jobs. Can also be used for message streaming. | A framework for storing, reading (re-reading), and analyzing streaming data. |
| License | Open Source: Mozilla Public License | Open Source: Apache License 2.0 |
| Written in | Erlang | Scala (JVM) |
| First Version Released | 2007 | 2011 |
| Persistence | Persist messages in traditional queues until they are dropped on the acknowledgement of receipt. Persists messages in Streams for as long as they are needed - with an option to delete after a retention period. | Persists messages with an option to delete after a retention period |
| Replay | Yes, via RabbitMQ Streams | Yes |
| Routing | Supports flexible routing which can return information to a consumer node | Does not support flexible routing, must be done through separate topics |
| Message Priority | Supported | Not supported |
| Monitoring | Available through a built-in UI | Available through third-party tools such as when deployed on Confluent |
| Language Support | Most languages are supported | Most languages are supported |
| Secure Authentication | Supports standard authentication and OAuth2 | Supports Kerberos, OAuth2, and standard authentication |
Contact us, we are happy to help you get started with RabbitMQ using our free plans on CloudAMQP.
Enjoyed reading about RabbitMQ and Kafka? Check out LavinMQ, another AMQP message broker! Learn more
Check out LavinMQ – a message broker from CloudAMQP
