This blog series is a living document that is continually updated. Last updated January 2025.
Some applications require really high throughput, while others publish batch jobs that aren’t as demanding. The goal when designing your system should be to maximize combinations of performance and availability that make sense for your specific application. Bad architecture design decisions or client-side bugs can damage your broker, halt your publisher, crash your server, or affect your throughput in other ways.
This article series focuses on best practices for RabbitMQ, including dos and don'ts for two different usage categories — high availability and high performance (high throughput). Among other topics, we will discuss queue size, common mistakes, lazy queues, prefetch values, connections and channels, Quorum Queues, and the number of nodes in a cluster. These topics are based on general best-practice rules we’ve gained through years of experience working with RabbitMQ.
That said, some of these challenges, like handling long queues or managing thousands of connections, might be more effectively solved with the message broker LavinMQ. Learn more about LavinMQ or check out the LavinMQ migration guide to see how easy it is to get started.
Part 2 - Best Practice for High Performance
High PerformancePart 3 - Best Practice for High Availability
High AvailabilityPart 4 - 13 common RabbitMQ mistakes
RabbitMQ mistakesUpdate: Diagnostics Tool for RabbitMQ
We have, due to popular demand, created a diagnostic tool for RabbitMQ that is available for all dedicated instances in CloudAMQP. A link to the tool can be found in the control panel for your instances.
Queues
Keep your queue short (if possible)
Many messages in a queue can put a heavy load on RAM usage. In order to free up RAM, RabbitMQ starts flushing (page out) messages to disk. The page out process usually takes time and blocks the queue from processing messages when there are many messages to page out, deteriorating queueing speed. Having many messages in the queue might negatively affect the performance of the broker.
Additionally, it is time-consuming to restart a cluster with many messages since the index has to be rebuilt. It also takes time to sync messages between nodes in the cluster after a restart.
Use Quorum Queues
Perhaps one of the most significant changes in RabbitMQ 3.8 was the new queue type called Quorum Queues. This is a replicated queue to provide high availability and data safety. CloudAMQP recommends the use of Quorum Queues.
The reasons you should switch to Quorum Queues and design flaws of classic mirrored queues are described in the article.
Enable lazy queues to get predictable performance (for RabbitMQ version < 3.12)
A feature called lazy queues was added in RabbitMQ 3.6. Lazy queues are queues where the messages are automatically stored to disk, thereby minimizing the RAM usage, but extending the throughput time.
In our experience, lazy queues create a more stable cluster with better predictive performance. Messages will not get flushed to disk without a warning. You will not suddenly experience a hit to queue performance. If you are sending a lot of messages at once (e.g. processing batch jobs) or if you think that your consumers will not keep up with the speed of the publishers all the time, we recommend that you enable lazy queues.
Starting with RabbitMQ version 3.12, all classic queues behave similarly to the way lazy queues behaved previously.
Limit queue size with TTL or max-length
Another recommendation for applications that often get hit by spikes of messages, and where throughput is more important than anything else, is to set a max-length on the queue. This keeps the queue short by discarding messages from the head of the queue so that it never gets larger than the max-length setting.
Number of queues
Queues are single-threaded in RabbitMQ. You will achieve better throughput on a multi-core system if you have multiple queues and consumers and if you have as many queues as cores on the underlying node(s).
The RabbitMQ management interface collects and calculates metrics for every queue in the cluster. This might slow down the server if you have thousands upon thousands of active queues and consumers. The CPU and RAM usage may also be affected negatively if you have too many queues.
Disable busy polling in RabbitMQ if you have many entities (connections or queues), to decrease CPU usage.
Split your queues over different cores
Queue performance is limited to one CPU core. You will, therefore, get better performance if you split your queues into different cores, and into different nodes, if you have a RabbitMQ cluster.
RabbitMQ queues are bound to the node where they were first declared. Even if you create a cluster of RabbitMQ brokers, all messages routed to a specific queue will go to the node where that queue lives. You can manually split your queues evenly between nodes, but; the downside is remembering where your queue is located.
We recommend two plugins that will help you if you have multiple nodes or a single node cluster with multiple cores:
Consistent hash exchange pluginThe consistent hash exchange plugin allows you to use an exchange to load-balance messages between queues. Messages sent to the exchange are consistently and equally distributed across many queues, based on the routing key of the message. The plugin creates a hash of the routing key and spreads the messages out between queues that have a binding to that exchange. It could quickly become problematically to do this manually, without adding too much information about numbers of queues and their bindings into the publisher.
The consistent hash exchange plugin can be used if you need to get the maximum use of many cores in your cluster. Note that it’s important to consume from all queues. Read more about the consistent hash exchange plugin here.
RabbitMQ sharding
The RabbitMQ sharding plugin does the partitioning of queues automatically; i.e., once you define an exchange as sharded, then the supporting queues are automatically created on every cluster node and messages are sharded accordingly. The RabbitMQ sharding plugin gives you a centralized place where you can send your messages, plus load balancing across many nodes, by adding queues to the other nodes in the cluster. Note that it’s important to consume from all queues.
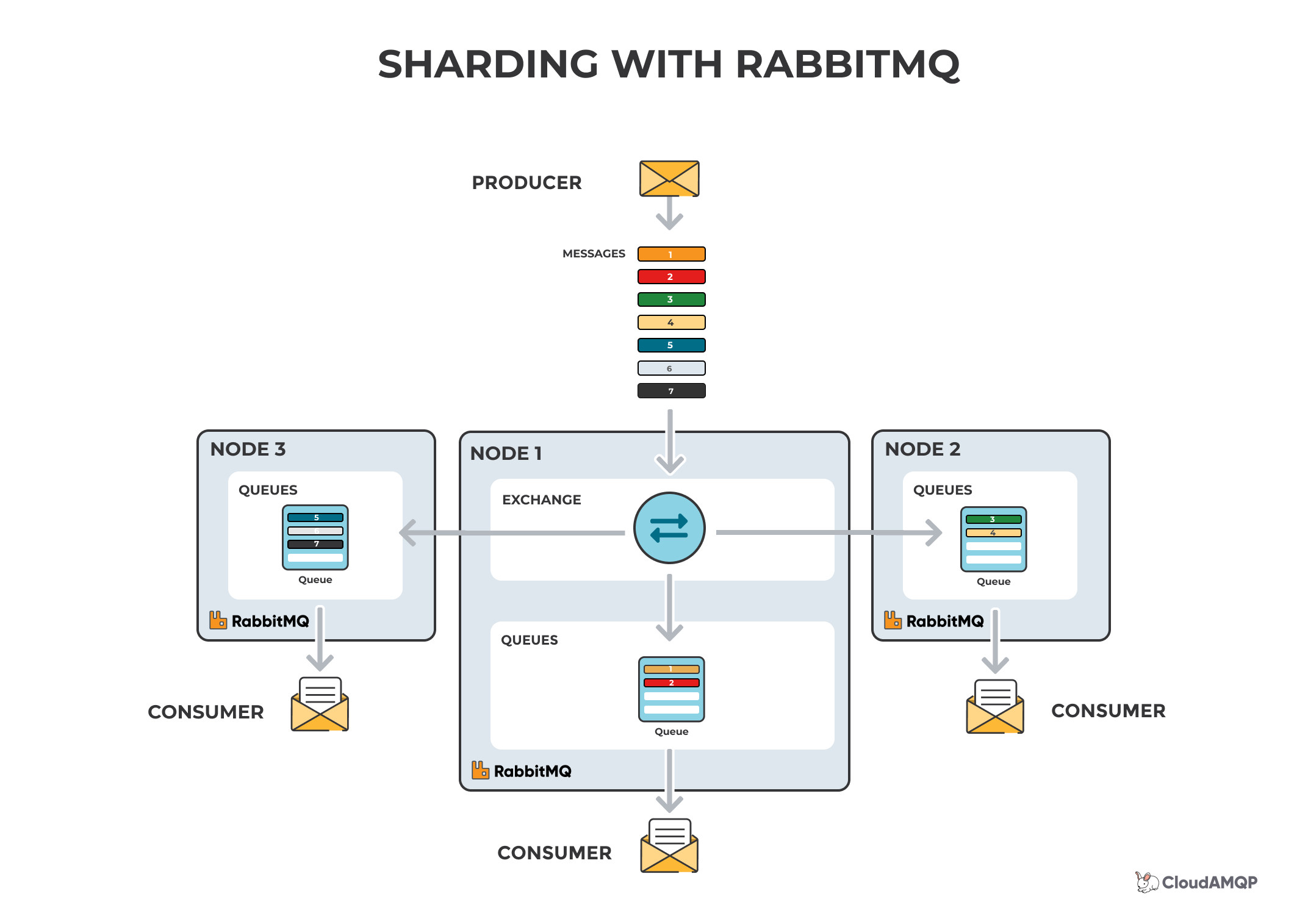
Read more about RabbitMQ sharding here.
Don’t set your own names on temporary queues
Giving a queue a name is important when you want to share the queue between producers and consumers, but it's not important if you are using temporary queues. Instead, you should let the server choose a random queue name instead of making up your own names, or modify the RabbitMQ policies.
Auto-delete queues you are not using
Client connections can fail and potentially leave unused resources (queues) behind, which could affect performance. There are three ways to delete a queue automatically.
Set a TTL policy in the queue; e.g. a TTL policy of 28 days deletes queues that haven't been consumed from for 28 days.
An auto-delete queue is deleted when its last consumer has canceled or when the channel/connection is closed (or when it has lost the TCP connection with the server).
An exclusive queue can only be used (consumed from, purged, deleted, etc.) by its declaring connection. Exclusive queues are deleted when their declaring connection is closed or gone (e.g., due to underlying TCP connection loss).
Set limited use of priority queues
Each priority level uses an internal queue on the Erlang VM, which takes up some resources. In most use cases it is sufficient to have no more than 5 priority levels.
Payload - RabbitMQ message size and types
How to handle the payload (message size) of messages sent to RabbitMQ is a common question among users. Keep in mind that the amount of messages per second is a way larger bottleneck than the message size itself. While sending large messages is not a good practice, sending multiple small messages might be a bad alternative. A better idea is to bundle them into one larger message and let the consumer split it up. However, if you bundle multiple messages you need to keep in mind that this might affect the processing time. If one of the bundled messages fails, will all messages need to be re-processed? When setting up bundled messages, consider your bandwidth and architecture.
Connections and channels
Each connection uses about 100 KB of RAM (more, if TLS is used). Thousands of connections can be a heavy burden on a RabbitMQ server. In the worst case, the server can crash because it is out of memory. The AMQP protocol has a mechanism called channels that “multiplexes” a single TCP connection. It is recommended that each process only creates one TCP connection, using multiple channels in that connection for different threads. Connections should be long-lived. The handshake process for an AMQP connection is quite involved and requires at least 7 TCP packets (more, if TLS is used).
Alternatively, channels can be opened and closed more frequently, if required, and channels should be long-lived if possible, e.g. reuse the same channel per thread of publishing. Don’t open a channel each time you are publishing. The best practice is to reuse connections and multiplex a connection between threads with channels. You should ideally only have one connection per process, and then use a channel per thread in your application.
Don’t share channels between threads
Make sure that you don’t share channels between threads as most clients don’t make channels thread-safe (it would have a serious negative effect on the performance impact).
Psst! I think you should check out LavinMQ...
Don’t open and close connections or channels repeatedly
Make sure you don’t open and close connections and channels repeatedly - doing so gives you a higher latency, as more TCP packages has to be sent and received.
Separate connections for publisher and consumer
Separate the connections for publishers and consumers to achieve high throughput. RabbitMQ can apply back pressure on the TCP connection when the publisher is sending too many messages for the server to handle. If you consume on the same TCP connection, the server might not receive the message acknowledgments from the client, thus effecting the consume performance. With a lower consume speed, the server will be overwhelmed.
A large number of connections and channels might affect the RabbitMQ management interface performance
Another effect of having a large number of connections and channels is the performance of the RabbitMQ management interface. For each connection and channel performance, metrics have to be collected, analyzed and displayed.
Acknowledgements and Confirms
Messages in transit might get lost in an event of a connection failure and need to be retransmitted. Acknowledgments let the server and clients know when to retransmit messages. The client can either ack the message when it receives it, or when the client has completely processed the message. Acknowledgment has a performance impact, so for the fastest possible throughput, manual acks should be disabled.
A consuming application that receives important messages should not acknowledge messages until it has finished with them so that unprocessed messages (worker crashes, exceptions, etc.) don't go missing.
Publish confirm is the same concept for publishing. The server acks when it has received a message from a publisher. Publish confirm also has a performance impact, however, keep in mind that it’s required if the publisher needs at-least-once processing of messages.
Unacknowledged messages
All unacknowledged messages must reside in RAM on the servers. If you have too many unacknowledged messages, you will run out of memory. An efficient way to limit unacknowledged messages is to limit how many messages your clients prefetch. Read more about prefetch in the prefetch section.
Persistent messages and durable queues
If you cannot afford to lose any messages, make sure that your queue is declared as “durable” and that messages are sent with delivery mode "persistent".
In order to avoid losing messages in the broker, you need to be prepared for broker restarts, broker hardware failure, or broker crashes. To ensure that messages and broker definitions survive restarts, ensure that they are on the disk. Messages, exchanges, and queues that are not durable and persistent will be lost during a broker restart.
Persistent messages are heavier with regard to performance, as they have to be written to disk. Keep in mind that lazy queues will have the same effect on performance, even though you are sending transient messages. For high performance, the best practice is to use transient messages.
TLS and AMQPS
You can connect to RabbitMQ over AMQPS, which is the AMQP protocol wrapped in TLS. TLS has a performance impact since all traffic has to be encrypted and decrypted. For maximum performance, we recommend using VPC peering instead as the traffic is private and isolated without involving the AMQP client/server.
At CloudAMQP we configure the RabbitMQ servers to accept and prioritize fast but secure encryption ciphers.
Prefetch
The prefetch value is used to specify how many messages are being sent to the consumer at the same time. It is used to get as much out of your consumers as possible.
From RabbitMQ.com: “The goal is to keep the consumers saturated with work, but to minimize the client's buffer size so that more messages stay in Rabbit's queue and are thus available for new consumers or to just be sent out to consumers as they become free.”
The RabbitMQ default prefetch setting gives clients an unlimited buffer, meaning that RabbitMQ by default sends as many messages as it can to any consumer that looks ready to accept them. Sent messages are cached by the RabbitMQ client library (in the consumer) until processed. Prefetch limits how many messages the client can receive before acknowledging a message. All pre-fetched messages are removed from the queue and invisible to other consumers.
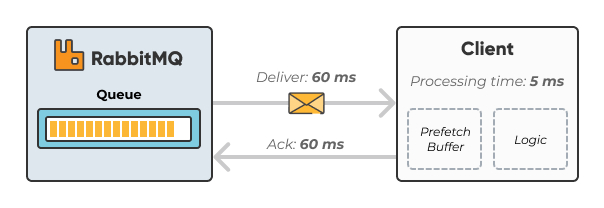
A too-small prefetch count may hurt performance since RabbitMQ is typically waiting to get permission to send more messages. The image below illustrates a long idling time. In the example, we have a QoS prefetch setting of one (1). This means that RabbitMQ won't send out the next message until after the round trip completes (deliver, process, acknowledge). Round-trip time in this picture is in total 125ms with a processing time of only 5ms.
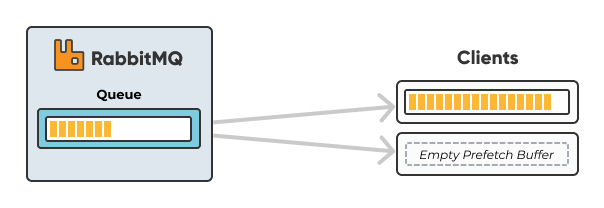
A large prefetch count, on the other hand, could take lots of messages off the queue and deliver to one single consumer, keeping the other consumers in an idling state.
How to set correct prefetch value?
If you have one single or few consumers processing messages quickly, we recommend prefetching many messages at once. Try to keep your client as busy as possible. If you have about the same processing time all the time and network behavior remains the same, simply take the total round trip time and divide by the processing time on the client for each message to get an estimated prefetch value.
In a situation with many consumers and short processing time, we recommend a lower prefetch value. A too low value will keep the consumers idling a lot since they need to wait for messages to arrive. A too high value may keep one consumer busy, while other consumers are being kept in an idling state.
If you have many consumers and/or long processing time, we recommend you to set the prefetch count to one (1) so that messages are evenly distributed among all your workers.
Please note that if your client auto-ack’s messages, the prefetch value will have no effect.
A typical mistake is to have an unlimited prefetch, where one client receives all messages and runs out of memory and crashes, causing all the messages to be re-delivered.
More information about RabbitMQ prefetch can be found in this recommended RabbitMQ documentation.
Cluster setup with at least 3 nodes
A CloudAMQP cluster with three nodes gives you three RabbitMQ servers. These servers are placed in different zones (availability zones in AWS) in all data centers with support for zones. The default quorum queue cluster size is set to the same value as the number of nodes in the cluster. This argument can be overridden with the queue argument quorum_cluster_size. Each quorum queue is a replicated queue; it has a leader and multiple followers. A quorum queue with a replication factor of five will consist of five replicated queues: the leader and four followers. Each replicated queue will be hosted on a different node (broker).
Routing (exchanges setup)
Direct exchanges are the fastest to use; many bindings mean that RabbitMQ has to take time to calculate where to send the message.
Disable unused plugins
Some plugins might be great, but they also consume a lot of CPU or may use a high amount of RAM. Because of this, they are not recommended for a production server. Disable plugins that are not in use. Use the control panel in CloudAMQP to enable - or disable - plugins.
Do not set the RabbitMQ Management statistics rate mode to detailed in production
Setting the RabbitMQ Management statistics rate mode to detailed has a serious performance impact and should not be used in production.
Use updated RabbitMQ client libraries
Make sure that you are using the latest recommended version of client libraries. Check our documentation, and feel free to ask us if you have any questions regarding which library to use.
Use the latest stable RabbitMQ and Erlang version
Stay up-to-date with the latest stable versions of RabbitMQ and Erlang. We go to great lengths to test new major versions before we release them to our customers. Please be aware that we always have the most recommended version as the selected option (default) in the dropdown menu area where selection is made of the version for a new cluster.
Use TTL with caution
Dead lettering and TTL are two popular features in RabbitMQ that should be used with caution. TTL and dead lettering can generate unforeseen negative performance effects, such as:
Dead lettering
A queue that is declared with the x-dead-letter-exchange property will send messages which are either rejected, nacked or expired (with TTL) to the specified dead-letter-exchange. If you specify x-dead-letter-routing-key the routing key of the message with be changed when dead lettered.
TTL
By declaring a queue with the x-message-ttl property, messages will be discarded from the queue if they haven't been consumed within the time specified.
RabbitMQ Streams
If you're exploring high-throughput use cases or need persistent, log-like message storage in RabbitMQ, streams are the best solution for you. To learn more about streams and how to use them effectively, check out our dedicated guide on RabbitMQ streams.
