What is Celery?
Celery is a distributed job queue that simplifies the management of task distribution. Developers break datasets into smaller batches for Celery to process in a unit of work known as a job.
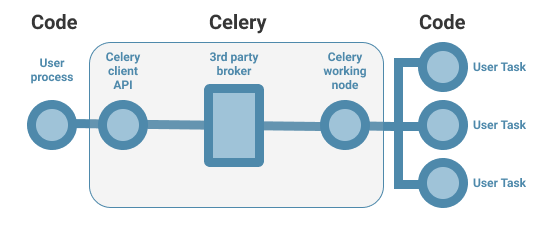
You deploy one or more worker processes that connect to a message queue (an AMQP or SQS based broker). Clients submit jobs to the message broker, and the queue is listening for job requests using Celery. The message broker then distributes job requests to workers. Workers wait for jobs from Celery and execute the tasks. When finished, the worker sends a result to another queue for the client to process.
In Celery, clients and workers do not communicate directly with each other but through message queues. Clients submit messages using tasks in the system much as a remote procedure call initiates a function. Clients do not need to understand the actual format but annotate functions and register them with the framework:
@app.task
def send_hello(x, y):
return ‘Hello’
# overrides the broker from your configuration
app = Celery('app_name', broker='...')
app.tasks[‘__main__.send_hello’]
Using the official Python binding, we created a task and registered it with
the system. You can use the
apply_async(function, args, kwargs,...)
method
to send the task to the appropriate queue. The client calls
get
on the
future returned by
apply_async
to block and retrieve the response or uses
the state method to initiate a call to the broker checking on the status of
the request.
A message routed to a queue waits in the queue until someone consumes it, and the message is deleted from the queue when it has been acknowledged.
Results in Celery
It is possible to keep track of a tasks’ states. Celery can also store or send the states. So, instead of using the get function, it is possible to push results to a different backend. There are several built-in result backends to choose from including SQLAlchemy, specific databases and RPC (RabbitMQ).
By default, Celery is configured not to consume task results. Setting the
configuration option
result_backend = 'rpc'
tells the system to send a response to a unique queue for consumption. It is
not advised to use the ampq backend. It might result in a memory leak.
More information about results can be found here.
What are exchanges in Celery?
Celery works through the message router and the publish-subscribe patterns. Publishers push messages to an exchange that utilizes either direct or wildcard matching to route them to one or more work queues in the broker. The exchange type defines how the messages are routed through the exchange. You configure exchange types in the configuration:
CELERY_QUEUES = {
“my_queue”:{
“exchange”: “my_exchange”,
“exchange_type”: “topic”,
“binding_key”: “all_tasks.task_type”
}
}
CELERY_DEFUALT_EXCHANGE=”my_exchange”
CELERY_DEFAULT_EXCHANGE_TYPE=”direct”
CELERY_DEFAULT_ROUTING_KEY=”all_tasks”In this example, you declare a default queue as the only known queue with the default exchange but override the type to topic with the routing key all_tasks.task_type. The topic exchange allows you to use wildcard matching so that tasks sent to all_tasks.* are still received. This configuration may occur in the same module where you start your application.
Types of Exchanges
The standard exchange types are direct, topic, fanout and headers. These dictate how messages pass to subscribers. Routing keys must match exactly in a direct exchanges. Fanout exchanges send messages to all attached queues. Topics allow for wildcard matching. Header exchanges pass only metadata.
Learn more about RabbitMQ exchanges and routing keys
When should I use Celery?
As a task-queueing system, Celery works well with long running processes or small repeatable tasks working on batches. The types of problems Celery handles are common asynchronous tasks. Image scaling, video encoding, ETL, email sending, or other pipelines benefit from this pre-built framework handling much of the work involved in their construction.
What are the benefits of using Celery?
Celery works with any language through the standardized message protocol. Apart from the official Python release, other APIs are in development for e.g. Java, Rust and Node. It is possible to create a centralized system using any language with an AMQP or SQS API.
Other benefits include minimizing the amount of code required to distribute tasks and the ability to schedule jobs periodically through celerybeat. Celerybeat is a scheduler that kicks off tasks at regular intervals. A standalone real-time monitoring for Celery workers is also available through celerymon.
Why should I use a cloud message broker?
As a prebuilt middleman, Celery simplifies pipeline development and management. CloudAMQP eliminates the administrative needs of your backend with ready-made clusters.
“We are using CloudAMQP - RabbitMQ as a broker for our async tasks through Celery. We are using it as the event-based async service. CloudAMQP supports our project through proper monitoring and high availability and scalable broker queues.” Shivam Arora, Delhivery
You no longer need to worry about scaling your system to meet growing demand. Our instances come with the management console already running.
Setting up RabbitMQ with CloudAMQP
CloudAMQP provisions your RabbitMQ instances nearly instantaneously. Create an account and provision an instance directly from the web management interface. Built-in auto-scaling allows your brokers to work quickly. CloudAMQP bases cost entirely on the power of the underlying provisioned instance, and you are able to scale up and down between different plans when needed. Our free tier, little lemur, is an excellent option for testing.
How do I use CloudAMQP as my Celery message broker?
Once provisioned, your CloudAMQP broker works in the same way as your on-premises system. All you need is a URL, username, and password to establish a connection to the broker. Celery handles the rest:
app = Celery('app_name', broker='amqps://user:password@host:port/host’)
print(app.conf.broker_url)The Celery framework stores the URL in the configuration. Since Celery runs separately from the broker, you gain the same degree of control as if running your entire system on-premises.
Can I run my Celery workers in the cloud?
While CloudAMQP provides a message broker, it is also possible to deploy Celery workers on AWS or another cloud service. Workers only need to know where the broker resides to become a part of the system. Celery maintains a queue for events and notifications without a common registry node.
Due to the use of a broker for system management, you can run your tasks in Docker containers over Kubernetes. Containers automatically scale to fit your needs while Kubernetes allows you to define scaling policies and Flower provides monitoring capabilities. An official Celery container can be found here: https://hub.docker.com/_/celery. Celery is also fully supported on Heroku.
Running your celery clients and workers in the cloud minimizes the cost of developing and deploying pipelines.
Why CloudAMQP is sponsoring the Celery project
We have many customers running applications that are trusting Celery, and we are therefore actively and monthly supporting the development of the Celery (AMQP) project. Please let us know if there is something in the Celery that you would like us to put extra focus on.
Visit our plan page for more information on getting started with deploying a RabbitMQ cluster. We also advise you to read our recommended settings for Celery on CloudAMQP before starting a production pipeline as well as gain an appreciation for the Celery framework.
