Quorum queues will be a new high availability offering that addresses some deficiencies of the existing mirrored queue functionality. It also introduces some new issues as we described in our article about Quorum Queues.
Each Quorum Queue is a replicated queue; it has a leader and multiple followers. A common term to refer to these leaders and followers is the word replica. A quorum queue with a replication factor of five will consist of five replicas: the leader and four followers. Each replica will be hosted on a different node (broker). We need multiple replicas in order to achieve high availability and durability. Depending on the replication factor of a quorum queue, we can lose one or more brokers without message loss and continued availability of the queue.
Introduction to Raft
Raft is a distributed consensus algorithm, that means it is a distributed algorithm where multiple nodes agree on some state. In Raft the state is an ordered sequence of commands. Those commands in RabbitMQ are the writes, reads, acknowledgements etc, that a queue processes when interacting with clients.
Raft refers to nodes or servers, which translate to queue replicas. Each quorum queue is a separate Raft cluster, so if we have 100 quorum queues, there are 100 Raft clusters. Running many hundreds or thousands of Raft clusters creates a communication flood that would be too resource intensive, so there is a variant of Raft called Multi-Raft, where the communications of the separate Raft clusters are combined and batched together into fewer calls. The RabbitMQ team decided for a Multi-Raft implementation for this reason.
Regardless of using Multi-Raft, the logical design of the standard Raft protocol still holds true and that is what we’ll cover next.
With Raft, all reads and writes go through a leader whose job it is to replicate the writes to its followers. When a client attempts to read/write to a follower, it is told who the leader is and told to send all writes to that node. The leader will only confirm the write to the client once a quorum of nodes has confirmed they have written the data to disk. A quorum is simply a majority of nodes. A cluster of three nodes has a quorum of two, a cluster of five has a quorum of three. Each node stores all commands in a log structure, where each command has an index in that log. The job of the consensus algorithm is to ensure that all nodes have the same command in the same index in their log.
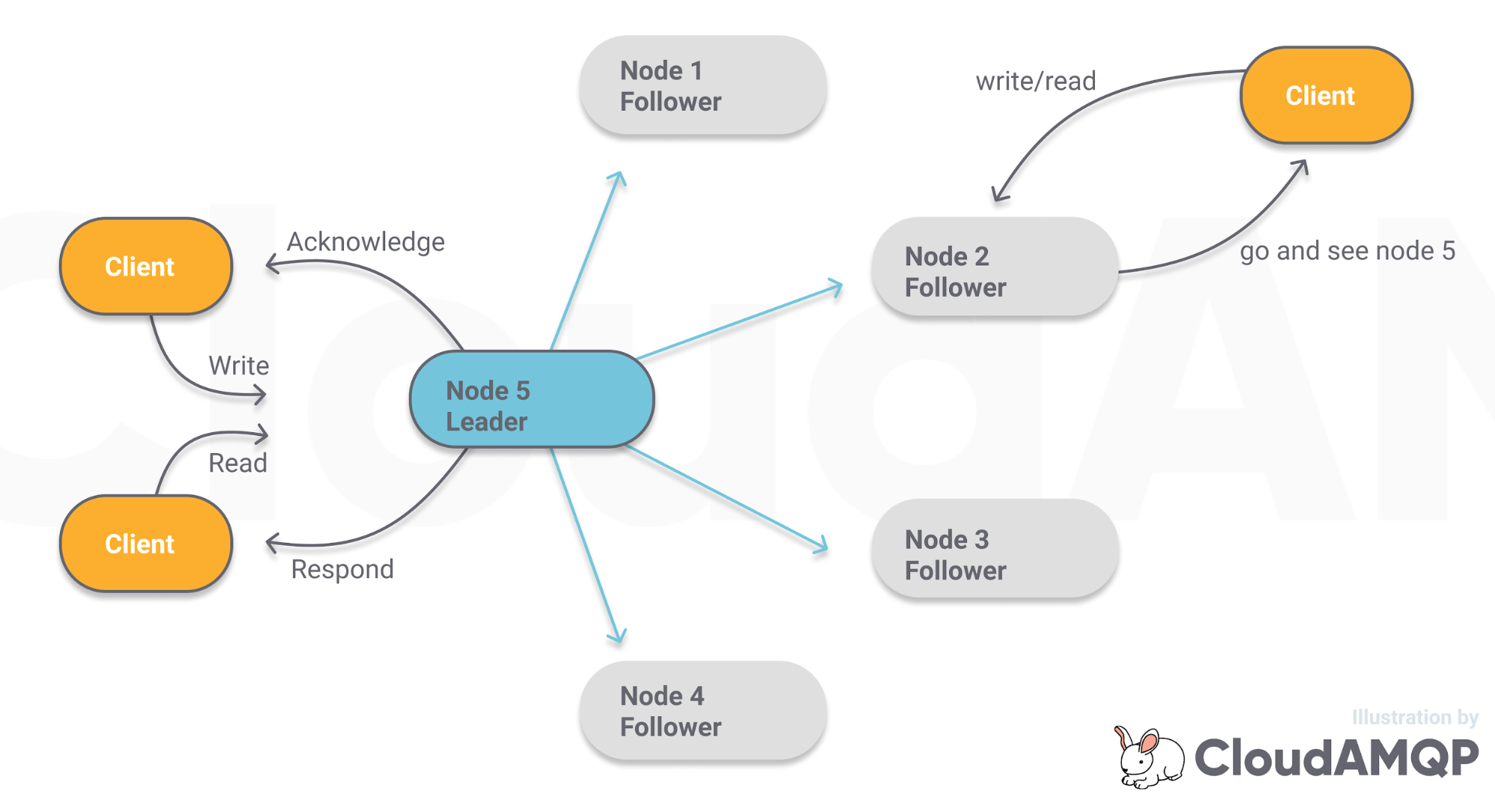 Fig 1. Raft consensus
Fig 1. Raft consensus
Raft has three main components:
- leader election
- log replication
- cluster membership changes
Leader Election
Leader election is the process of agreeing on a leader. Raft does not permit two functional leaders at the same time.
Each node will be in one of three states:
- Follower. In this state a node issues no requests but passively waits for requests to come in from the Leader or Candidates
- Candidate. Used for leader election. When a follower detects the loss of the leader, they transition to the Candidate state and start sending out RequestVote requests to all other nodes.
- Leader. Responsible for interacting with clients and replicating the log to the Followers.
- A majority of nodes should respond with a positive vote
- When a candidate sends a RequestVote message, it includes what it considers is the current term + 1. The receiving node checks that the term is greater than its own. This prevents stale nodes (that might have been disconnected or down for a while) from gaining leadership.
- A candidate includes in the RequestVote message, the last log entry index in its log. A node will reject the message if the index is behind its own committed last log entry index. This ensures that a node that is further behind cannot become the leader as this would cause data loss.
- the quorum vote requirement for leader elections
- the quorum write requirement for all writes
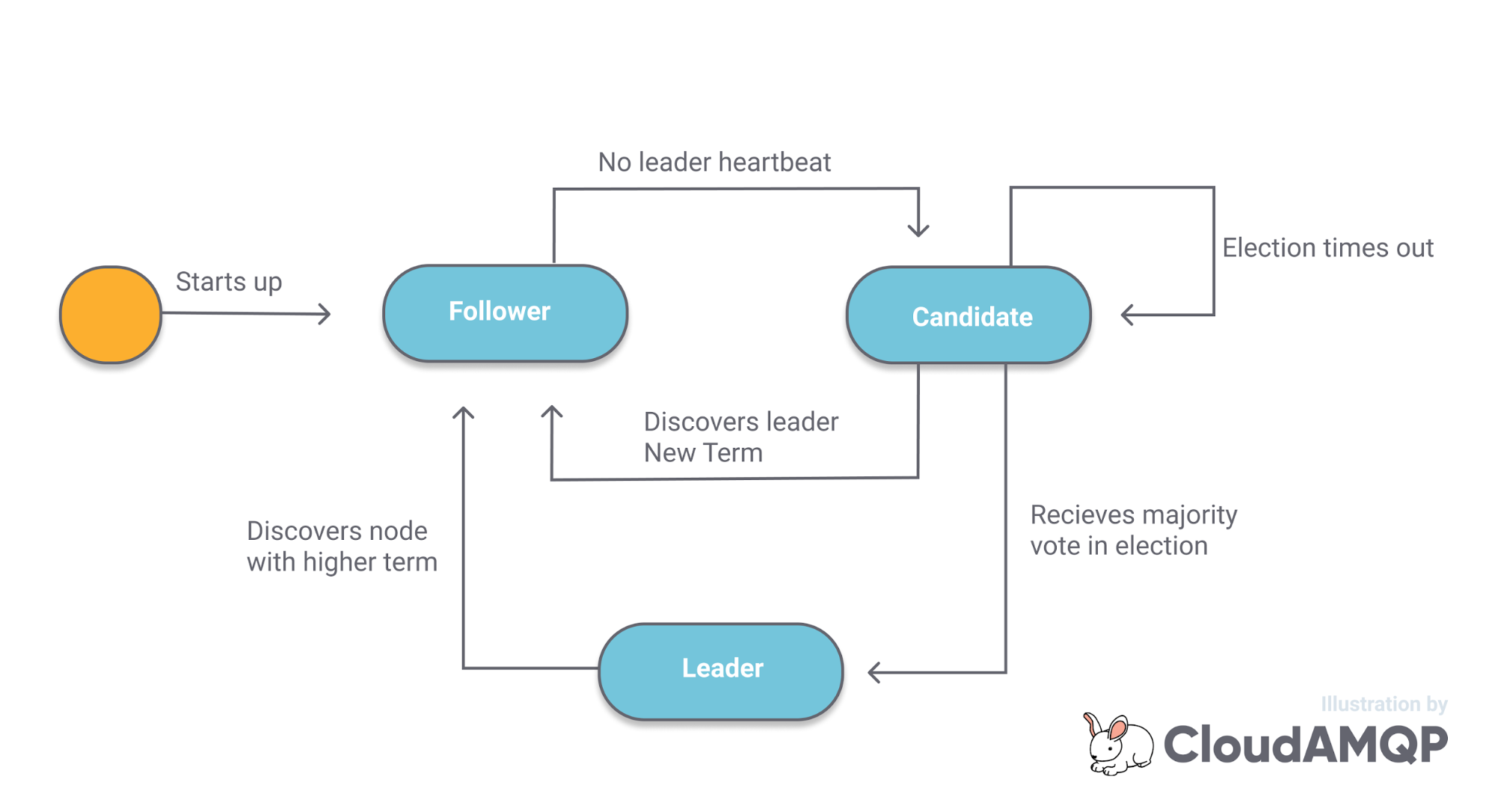 Fig 2. Follower, leader, candidate
Fig 2. Follower, leader, candidate
When a node starts-up it is in the Follower state and it waits for a heartbeat from the leader. If the wait times out then it transitions to the Candidate state and it sends out a RequestVote message to all members of the cluster. If other nodes also timed out waiting for the leader heartbeat then they may also be sending out RequestVote requests at the same time. If a candidate does not get a majority vote then the node transitions back to the Follower state. Only if the node gets a majority vote it will become the leader. The first node to send out its RequestVote requests will usually become the leader.
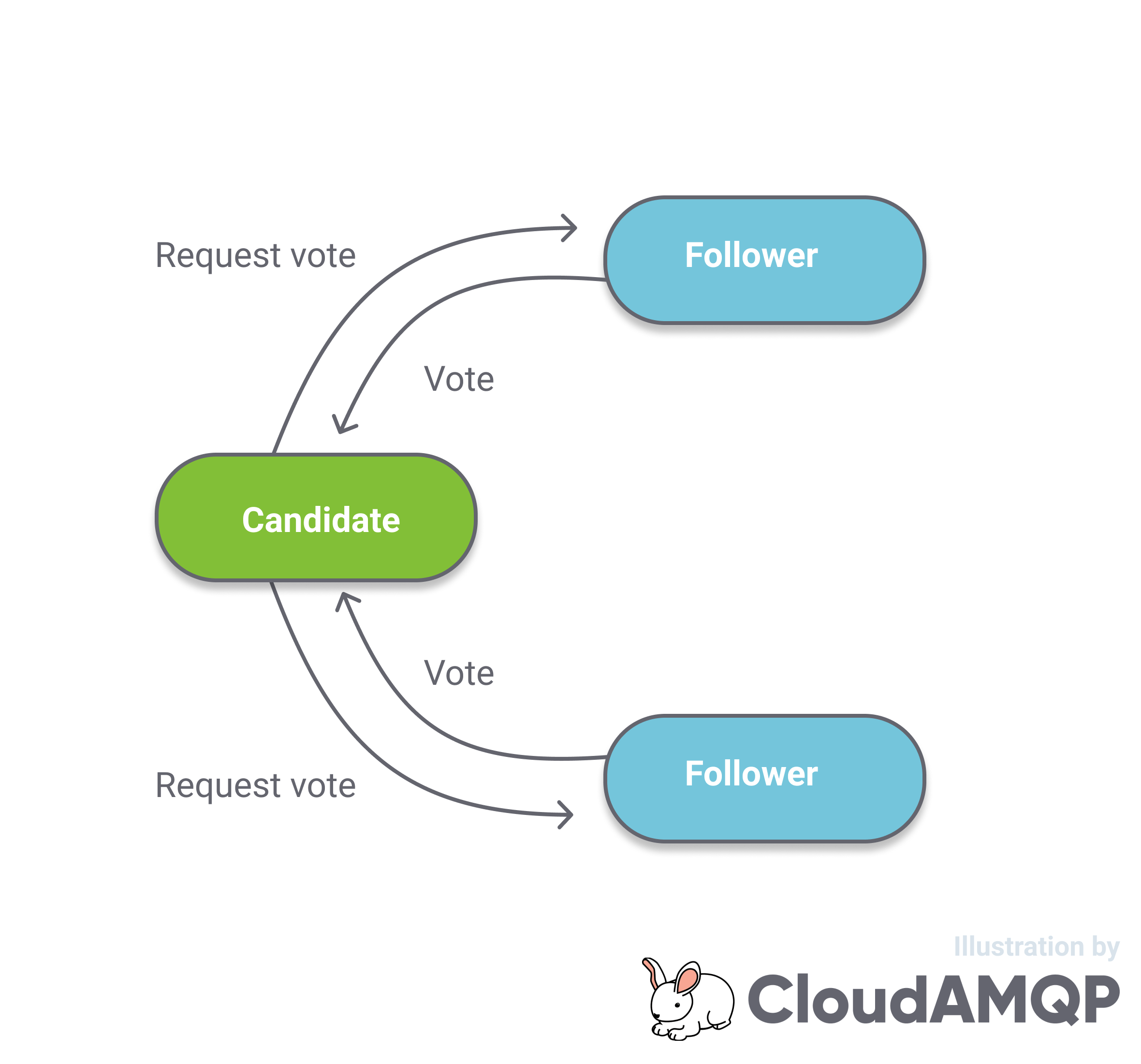
Fig 3. RequestVote
Once a node becomes the leader it sends out a periodic heartbeat to all followers. If the leader fails or is shutdown, then the Followers will time out (Election timeout period) waiting for the heartbeat and they will start sending out RequestVote requests again and one will become the new leader.
The concept of a term (also known as an epoch or fencing token) is a monotonic counter (a logical clock) that is used to detect out-of-date nodes that might have been disconnected or down for a while and have obsolete information. Each time a Follower transitions to Candidate, it increments its term and includes that term in its RequestVote messages. Once a leader is elected, the term does not change until the next election. The current term is included in all communications as a safety mechanism.
To win an election there are three rules:
Log Replication
Log replication is performed by the leader sending AppendEntries messages to its followers. The Followers are able to indicate to the leader what their last committed index is and the leader can send out AppendEntries messages with the next commands from that point. This means that a leader can be replicating log entries to one follower that is mostly up-to-date and also to another follower that just joined and has no data at all. The AppendEntries message acts as the leader heartbeat and is sent out periodically even if there is no new data.
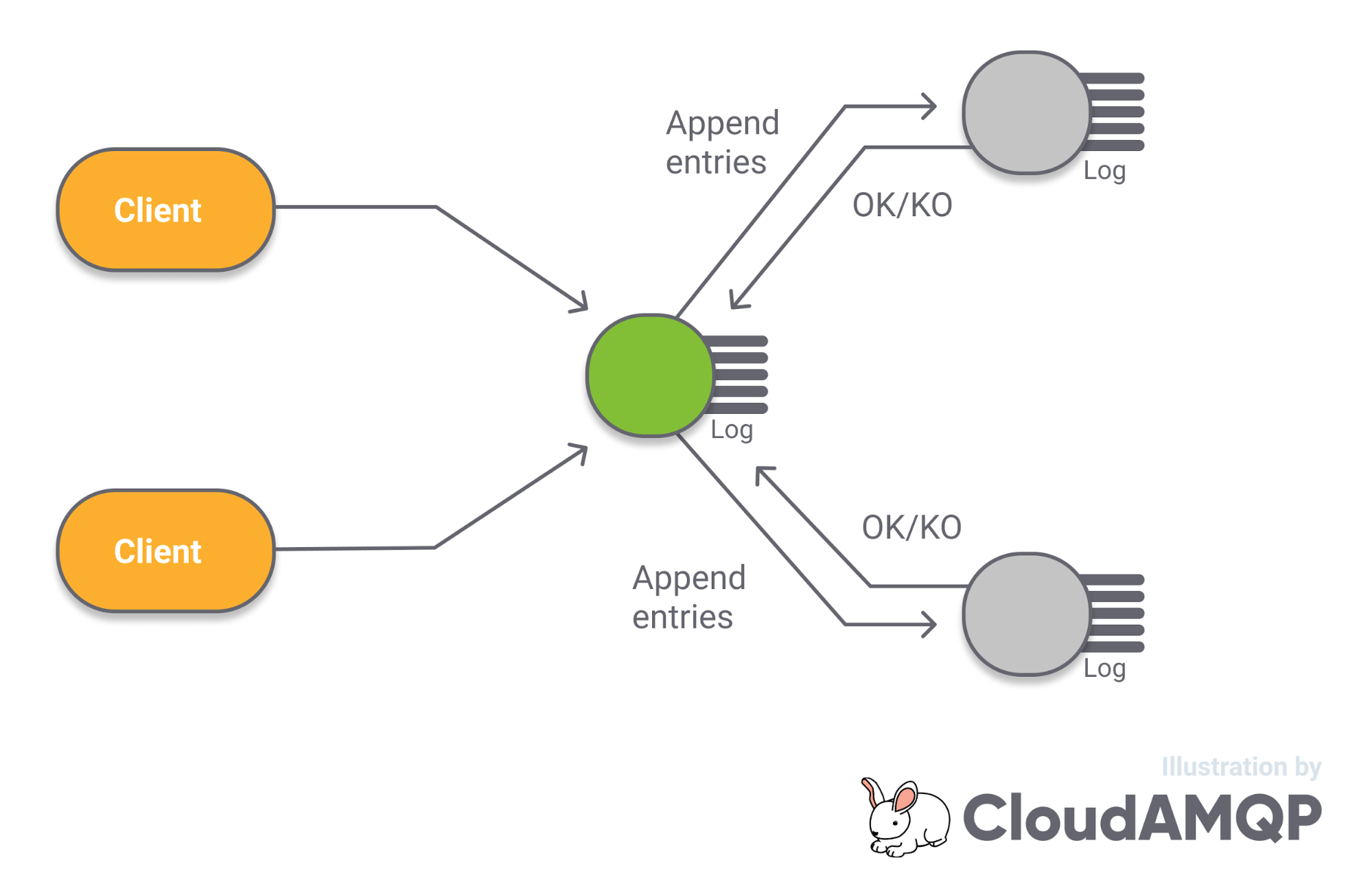
Fig 4. Log Replication
Network Partitions
When a network partition occurs that breaks communications between nodes, mirrored queues have the possibility of entering a split-brain mode (unless pause minority is used). This is where the nodes that are on the other side of the partition from the leader, stop seeing the leader and elect a new one. Now the cluster has two leaders who accept reads and writes. Having two leaders accepting reads and writes allows for continued availability at the cost of a divergent queue and can result in message loss.
Note that a “read” in RabbitMQ is in fact also a “write” as all reads are destructive. They implicitly include a command to delete the message.
Raft prevents split-brain due to:
If a leader is on the minority side of a partition, then it cannot confirm any new writes as it cannot replicate those writes to a majority. The nodes on the majority side can elect a new leader, and service can continue. There would be two leaders at this point but only the leader on the majority side is functional. When the partition is resolved, the original leader will send out an AppendEntries message with a term that is now lower than that of the other nodes and it will immediately become a follower.
If a leader is on the majority side of a partition, then it can continue to accept writes. The follower(s) on the minority side will stop receiving the leader heartbeat (AppendEntries) and will become candidates. But these candidates cannot win a leader election because they cannot get a majority vote. They will continue to send out RequestVote messages until the partition is resolved at which point they will see that there is already a leader and they will revert to being followers again.
There is a lot more to the Raft protocol and there are a host of nuances that we have not covered here, so if you want to understand Raft in full then check out the Raft website and the paper.
As mentioned earlier, RabbitMQ does not implement Raft exactly as described due to the amount of inter-broker communication required. The RabbitMQ team have implemented a variant based on Multi-Raft where the communications of multiple Raft clusters are bundled together into a single shared communication protocol. But the important logical properties of the original Raft protocol still hold true.
Consistency and Availability
A quorum queue is only available when a majority (quorum) of replicas are available. A quorum queue with a replication factor of three, on a three broker cluster can only tolerate the loss of a single broker. If two brokers go down then the queue becomes unavailable to clients. Likewise, if a network partition splits the replicas into one group of two and another of one, then only the majority side can continue to function.
Likewise, message durability (consistency) is only guaranteed when a quorum remains available. A quorum queue will be unrecoverable if the data of a quorum of replicas is permanently lost.

Summary
Quorum queues will be part of the 3.8 release later this year. Quorum Queues are not suitable for all scenarios so review their features and limitations well. You can read more about Quorum Queues here:
Please send us an email at contact@cloudamqp.com if you have any questions or feedback to this blogpost.
